Moy
1
13 个赞
被水淹没
2
 你是怎么把元数据单独放在右上角的?
你是怎么把元数据单独放在右上角的?
话说有没有那种在元数据那里直接下拉选枚举项的插件(不是mataband那种分离式)
Moy
3
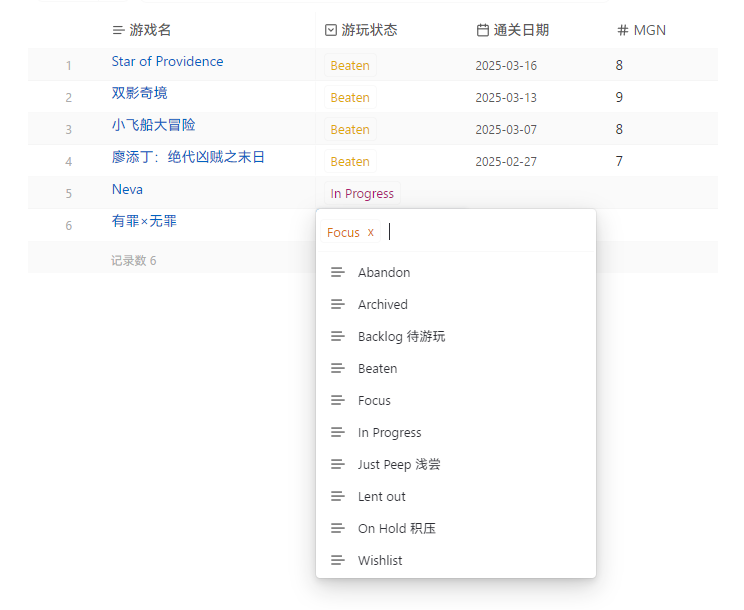
至于枚举,Obsidian 属性原生就对特定类型的数据支持枚举:
(不知道这是不是你指的意思)
如果满足不了的话,应该也没啥别的办法。
1 个赞
被水淹没
4
Moy
5
两种方案:
- 用 Components 插件进行管理和编辑
它的数据视图(数据库)可以做到类似的特性。
- 用 Templater 脚本,自己预先写好枚举值,然后用 Suggestor 来弹出选项,并修改元数据
做法类似 【TP脚本】快速切换任务完成状态并添加日期 - 经验分享 - Obsidian 中文论坛
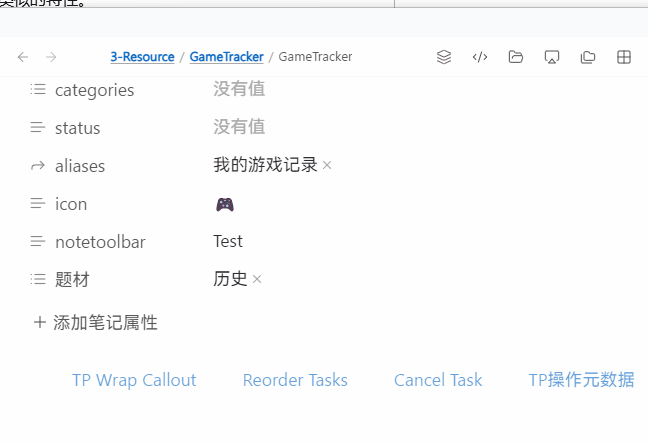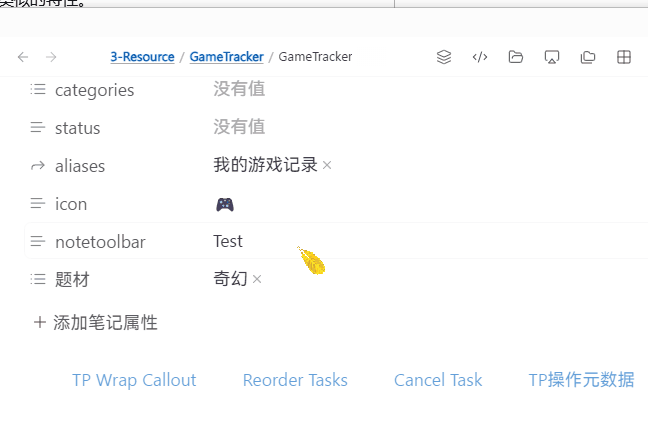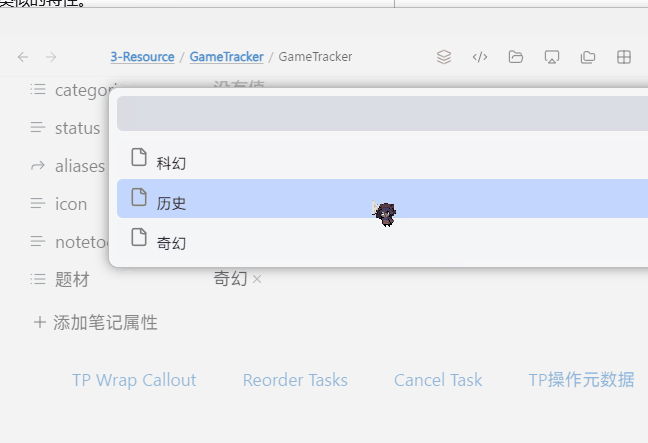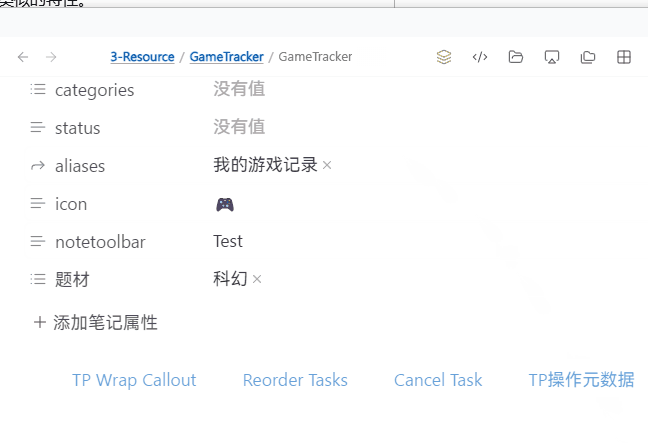
注:动图里我只是用 NTB 方便调用,实际你可以给这个 TP 脚本分配快捷键
参考脚本:
<%*
// 定义题材选项
const genres = ["科幻", "历史", "奇幻"];
// 定义操作模式
const isReplace = true; // true: 完全替换, false: 添加(并去重)
// 让用户选择题材
const selectedGenre = await tp.system.suggester(genres, genres);
if (selectedGenre) {
// 获取当前文件的元数据
const file = app.workspace.getActiveFile();
const meta = app.metadataCache.getFileCache(file).frontmatter || {};
// 初始化“题材”字段(如果不存在)
if (!meta["题材"]) {
meta["题材"] = [];
}
// 根据操作模式更新“题材”字段
if (isReplace) {
meta["题材"] = [selectedGenre]; // 完全替换
} else {
if (!meta["题材"].includes(selectedGenre)) {
meta["题材"].push(selectedGenre); // 添加并去重
}
}
// 更新文件的元数据
await app.fileManager.processFrontMatter(file, (frontmatter) => {
frontmatter["题材"] = meta["题材"];
});
// 提示用户操作成功
new Notice(`已${isReplace ? "完全替换" : "添加"}题材: ${selectedGenre}`);
}
%>
1 个赞
Moy
6
更新:发了 Easy Copy 1.2.0 版本,于是也在论坛这边发帖推荐。
话说这里同时作为答疑贴真的没人想问问题吗?
1 个赞
铅笔小明
9
我有一个问题,其实是我准备搭配Components做一个影视行业中拉片的知识库。我使用。Media Extended,把一个视频的时间点记录下来。快捷键记录的格式为
三级标题(对画面的描述)
- [关键词::撕裂] [关键词::时尚]
- 时间点跳转
- 时间点对应截图
三级标题2(对画面的描述)
不知道有没有方法批量把这种格式的批量变成单独的笔记文件,并以当前笔记名称+三级标题(对画面简答描述)作为新的笔记名,然后同时还embed引用到当前笔记,让当前笔记看着和原来的内容一致。不知道这么描述能不能理解 。因为想用Components做最后的汇总,就需要把他们拆分为单独的笔记内容。(目前只能想到这么一个方法)
。因为想用Components做最后的汇总,就需要把他们拆分为单独的笔记内容。(目前只能想到这么一个方法)
Moy
10
感觉可以先看一下 轻量数据库 的实现方案。
基础格式和你列举的很相似:
- 二级标题
- 标题下面一行 inline property 内联属性
- 然后写链接
- 正文
用 Dataview 可以把它们提取出来并显示成一个表格。
而且不需要拆分很多个页面,单个 md 内就可以。
效果像是这样:
更新版的脚本在这里:
const useList = false;
const curNote = dv.current();
const showLink = input?.showLink ?? true;
const showImage = input?.showImage ?? true;
if (!curNote){
dv.span("当前文档未加载,请重新打开");
return;
}
let tarFile = await app.vault.getAbstractFileByPath(curNote.file.path);
// 获取当前文件的 meta 数据
const curFileMeta = app.metadataCache.getFileCache(tarFile);
const headings = curFileMeta.headings;
const headingsList = headings.map( k => k.heading )
// 获取当前文章的文本内容
const curFilePath = curNote.file.path;
const curTFile = await app.vault.getFileByPath(curFilePath)
const content = await app.vault.cachedRead(curTFile);
if (!headings) {
dv.span("当前文档缺少标题");
return;
}
const meta = content.matchAll(/#+ (.*)\n+(\[.*\:.*\])\n+(\[.*\]\(.*\))\n+(\!\[\[.*\]\])\n/gm);
// 标题作为 key,元数据作为 value,做成 DV 表格
let tableHeads = ["标题"]
// 先存成一个 dict
let metaValues = []
if (showLink) {
tableHeads.push("链接")
}
if (showImage) {
tableHeads.push("图片")
}
if (meta) {
for (let m of meta) {
let title = m[1]
// 检查 title 是否在 headings 内(避免把一些代码块内的内容也当作元数据)
if (headingsList.indexOf(title) == -1) {
continue
}
let metaList = m[2].split(" ")
let metaDict = {}
if (showImage) {
let image = m[4] ?? ""
let imageHtml = ""
if (image) {
// 把图片的displaytext 换成 📸
// image = dv.embed(image)
let imageLink = image.match(/\[\[(.*?)\]\]/)
let imageFullPath = app.metadataCache.getFirstLinkpathDest(imageLink[1], imageLink[1]).path
let resPath = app.vault.adapter.getResourcePath(imageFullPath)
imageHtml = `<img src="${resPath}" style="max-width: 300px;" />`
}
metaDict["图片"] = imageHtml
}
// 添加元数据的 key 到表头
for (let i = 0; i < metaList.length; i++) {
let keyValue = metaList[i].replace("[", "").replace("]", "").split("::")
// console.log(metaList[i], keyValue)
let key = keyValue[0].trim()
if (tableHeads.indexOf(key) == -1) {
tableHeads.push(key)
}
if (useList){
// 1. 列表形式,重复属性会合并
let value = [keyValue[1]]
metaDict[key] = metaDict[key] ? metaDict[key].concat(value) : value
} else {
// 2. 文本形式,重复属性会使用最新的
let value = keyValue[1]
metaDict[key] = metaDict[key] ? metaDict[key] + `,${value}` : value
}
}
// 添加 URL 进元数据
if (showLink) {
let url = m[3]??""
if (url) {
// 把链接的displaytext 换成 🔗
url = url.replace(/\[(.*?)\]/, "[🔗]")
}
metaDict["链接"] = url
}
let returnValuesList = []
for (let i = 0; i < tableHeads.length; i++) {
if (i == 0) {
returnValuesList.push(`[[#${m[1]}]]`)
} else {
returnValuesList.push(metaDict[tableHeads[i]] ? metaDict[tableHeads[i]] : "")
}
}
metaValues.push(returnValuesList)
}
}
dv.table(
tableHeads,
metaValues.map( k => k )
)
用法见 【Dataview 入门介绍】DV 脚本是什么?怎么用? - 经验分享 - Obsidian 中文论坛
例图里对应的文本源代码为:
### DOIO
[按键::16] [旋钮::1] [连接::蓝牙双模] [价格::378]
[DOIO 16键设计师小键盘 客制化 蓝牙双模 无线 机械键盘 KB16B-02-tmall.com天猫](https://detail.tmall.com/item.htm...)
![[250427_单手小键盘选购-img-250427_094128.webp]]
需要注意的是,列表类型的属性直接写到一起就可以,像是 [关键字::A,B] 这样。
脚本本身也有一些开关选项,可以询问 AI 进行调整。
铅笔小明
11
但是这个可以把某个文件夹下所有的笔记内的内容进行汇总筛选么。我可能还需要涉及到筛选相关的,所以想着用Components可能方便一些。
Moy
12
想做都能做,把脚本里的 tarFile 从当前笔记改成「文件夹内的笔记」就可以提取多个笔记。
筛选也能实现……不过讲真如果不熟悉 JS,自己搞这些会有点麻烦。
回到 CPS 的思路,你把这个固定格式交给 AI 然后跟它讲需求就好了,写个 Python 脚本很快的。
- 基于三级标题拆分,给每一个三级标题创建成对应同名的笔记文件(markdown)
- 将标题内的内容都提取到对应的笔记内
- 同时,在原有位置替换成
![[笔记名称]] 格式的内嵌链接
大概这样的思路,细节你可以和 AI 老师再磋商。
另外,用这种形式的话可以干脆直接把「关键字」、「时间点(链接)」都作为新笔记的文件属性,方便 CPS 那边进行属性的相关操作。
1 个赞
Moy
13
另外针对「截取网页截图+复制时间码」,我也做过一个 Quicker 动作: 视频笔记 - by Moy
在 OB 内调用 QK 文章里有简单提及。
如果是 Windows 用户+有 Quicker 的话也可以试试。
铅笔小明
14
感谢,我去试试看。因为我是mac系统,所以quicker整不了。
1 个赞
铅笔小明
15
话说想问一个有关于css的问题,我想把一些指定的标签在阅读模式改成这种样式的,但是我尝试让AI帮我进行调整,总是没办法把标签前面的#去掉,有点强迫症,大佬有研究过这个么。
Moy
16
你这个截图里用的是:
gapmiss/inline-callouts: An Obsidian.md plugin for displaying inline “callouts” badges & icons.
你是单纯想实现这个效果,还是确实就想把标签改成类似这样的样式?
标签前面的 # 有单独的 DOM 元素的:
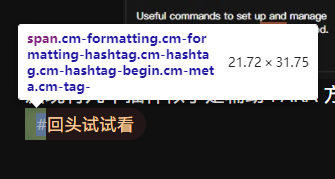
可以参考: 【新手向教程】OB样式调整基础课:CSS入门科普 - 经验分享 - Obsidian 中文论坛
另外,个人非常不建议出于强迫症去除 # 或者 ** 一类的 Markdown 标记符号。
更新:
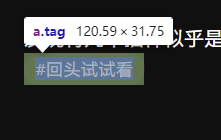
阅读模式下井号和后面的文本是一个整体,拆不出来。建议别折腾。
铅笔小明
17
我是想把一些特定的标签改成类似的样式,因为感觉是蛮好看的。子弹笔记的时候也容易分辨。
Moy
18
# 去不掉;

别的样式你可以根据 href="#标签名称" 来指定:
a.tag[href="#样式"] {
background-color: aquamarine;
color: black;
border-radius: 4px;
&::before {
/* svg 图标 */
width: 24px;
content: url('data:image/svg+xml;utf8,<svg xmlns="http://www.w3.org/2000/svg" width="20" height="20" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="lucide lucide-palette-icon lucide-palette"><path d="M12 22a1 1 0 0 1 0-20 10 9 0 0 1 10 9 5 5 0 0 1-5 5h-2.25a1.75 1.75 0 0 0-1.4 2.8l.3.4a1.75 1.75 0 0 1-1.4 2.8z"/><circle cx="13.5" cy="6.5" r=".5" fill="currentColor"/><circle cx="17.5" cy="10.5" r=".5" fill="currentColor"/><circle cx="6.5" cy="12.5" r=".5" fill="currentColor"/><circle cx="8.5" cy="7.5" r=".5" fill="currentColor"/></svg>');
padding-right: 0.3em;
opacity: 0.8 !important
}
}
效果:

铅笔小明
19
感谢尝试,我现在研究怎么把这个背景调整和上面那个类似的,感觉上面的像是自动把文字的颜色做了一个有透明度的底放在下面。
Moy
20
文字用 #66ccff 这种格式的颜色变量,背景色用它+两位数的不透明度:#66ccff88
是十六进制的 HEX 色值,具体可问 AI
1 个赞
发的帖子越来越多了,有时候自己都不太好找。
 基础入门
基础入门 技巧分享
技巧分享 插件推荐
插件推荐 实用脚本
实用脚本 CSS 样式美化
CSS 样式美化 工作流优化
工作流优化 笔记的方法论
笔记的方法论 疑问解答
疑问解答