为 DataviewJS 小白手册 提供实践巩固,默认读者已知晓“小白入门 DataviewJS 方法”。
进阶教程:DataviewJS 的翻页与随机
学习关键:
1、分清所用函数属于 JS、Ob 还是 Dv 插件,这样才知道该翻哪个文档、用哪种格式书写。
2、提取与汇总的基础是各种取值操作,通用步骤为“获取数组/对象 - 取出数组项/对象属性”。
- 数组是有序的,各项用索引标识,如
数组[0]。 - 对象是无序的,各属性用名称标识,如
对象.属性名或对象[属性名]。
实例代码获取到数组/对象后,往往只取数组的某项/对象的某个属性。
观察代码在取值前如何获取数组/对象,通过开发控制台查看完整的数组/对象,举一反三,尝试取出一些别的值,很快就能学会如何取出自己想要的值。另:
- 用
moment()进行时间相关操作需使用 Moment.js 支持的格式。
自定属性使用moment()为防意外,可写moment(`${ }`)放花括号里。 - 也许你在同一文档定义多个相同属性,
虽然 有时 能借此简便汇总,但长期可能会有意想不到的 问题,原理 见此。
本文不会介绍和使用类似示例,也提醒各位慎用,除非你知道自己在做什么。
折叠三角可点击展开,点击图片或右键 - 打开图片查看大图。
汇总文档
汇总近一周新建文档
要点:
.groupBy()后,需用rows来指代每个组。- 该实例取得的
p.rows.file.link是数组,需用.join()转为字符串。
代码
const dFiles = dv.pages()
.filter(p=> Date.now() - p.file.cday.ts < 6048 * 1e5)
.groupBy(p=> p.file.cday.ts)
const tdata = dFiles.map(p=> [
`${moment(p.key).format('MMDD')} (${p.rows.length})`,
p.rows.file.link.join('\n')
])
dv.table(['日期', '文档'], tdata)
- JS 方法:
.filter()、Date.now()、.groupBy()、.map()、.join() - Moment.js:
moment()、.format()
注意:.format('MMDD') 为表格呈现的日期格式,参 Moment.js Format 自行修改。
效果:

汇总原文
汇总各级标题为大纲 & 汇总各文档各级标题
前者作用于当前活动文档(单文档),后者作用于路径下文档(多文档)。
要点:
- 通过 Ob API 读取各级标题,通过 JS 方法排版格式。
- 多文档汇总用
.filter(p=> p)过滤文档中没有标题的文档。
代码
const startHeadingLevel = 0 // 起始标题级别
const file = app.workspace.getActiveFile()
const { headings } = app.metadataCache.getFileCache(file)
const lists = headings.map(p=>
`${' '.repeat((p.level - startHeadingLevel) * 4)}- ${p.heading}`
) // 前导空格 + 列表格式
dv.paragraph(lists.join('\n')) // 输出
const dFiles = dv.pages(`"文件目录"`)
const startHeadingLevel = 0
dFiles.map(async dFile=> {
const file = app.vault.getAbstractFileByPath(dFile.file.path)
const { headings } = app.metadataCache.getFileCache(file)
const lists = headings.filter(p=> p).map(p=>
`${' '.repeat((p.level - startHeadingLevel) * 4)}- ${p.heading}`
)
dv.header(6, dFile.file.link)
dv.paragraph(lists.join('\n'))
})
- JS 方法:
.map()、.filter()、.repeat() - Ob API:
app.metadataCache.getFileCache()、app.workspace.getActiveFile()(活动文档)、app.vault.getAbstractFileByPath()(路径下文档)
效果:
单文档 ↔ 多文档

汇总标题下标题
档 1 文本
## 任务一
包括两个任务。
### 扫地
扫地
### 洒水
档 2 文本
## 任务一
包括一个任务。
### 扫地
代码
const term = '任务一'
const dFiles = dv.pages(`"文件目录"`)
const headers = dFiles.map(dFile=> {
const file = app.vault.getAbstractFileByPath(dFile.file.path)
const { headings } = app.metadataCache.getFileCache(file)
if (!headings) return
const h = []; let b = false
for (const i of headings) {
if (b && i.level == 2) b = false
if (i.heading == term && i.level == 2) b = true // 判断是否执行
if (b && i.level == 3) h.push(i.heading) // 执行
}; return h.length == 0 ? false : [dFile.file.link, h]
// 仅当有结果时,返回 dFile.file.link 和 h
}); dv.table(['文档', term], headers.filter(p=> p))
- JS 方法:
.map()、.push()、.filter() - Ob API:
app.metadataCache.getFileCache()、app.vault.getAbstractFileByPath()
注意:term = ' ' 中的文本为检测条件,判断行的两个 i.level == 2 表明 2 级标题,执行行的 i.level == 3 表明 3 级标题,故此示例代码检测 2 级标题、添加 3 级标题。
效果:也即汇总了文件目录下所有文档中二级标题“任务一”下所有三级标题。

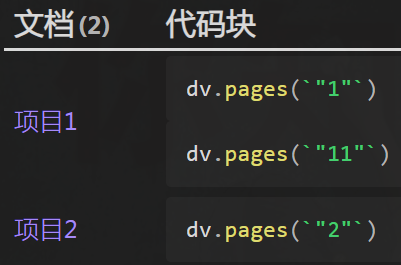
汇总代码块、Callout 等
要点:
- “汇总标题下标题”衍生代码。
- 各截取部分间额外
.concat('\n'),满足格式渲染所需空行。
代码
const dFiles = dv.pages(`"文件目录"`)
Promise.all(dFiles.map(async dFile=> {
const raws = ( await app.vault.readRaw(dFile.file.path) ).split('\n') // 分块
const file = app.vault.getAbstractFileByPath(dFile.file.path)
const codes = app.metadataCache.getFileCache(file).sections.filter(p=> p.type == 'code')
let r = []
for (const sec of codes) {
const { start: s, end: ed } = sec.position
r = r.concat(raws.slice(s.line, ed.line + 1).concat('\n'))
}
return r[0] ? [dFile.file.link, r.join('\n')] : !1 // 仅当有结果时返回
})).then(tdata=> dv.table(['文档', '代码块'], tdata.filter(p=> p)))
- JS 方法:
Promise.all()、.map()、.split()、.filter()、.concat()、.slice()、.join() - Ob API:
app.metadataCache.getFileCache()、app.vault.getAbstractFileByPath()
同理,将 'code' 改为 'callout'(小写),即可汇总 Callout。
效果:
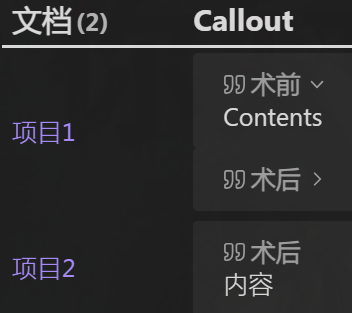
彩蛋:汇总块内容
一些短小的内容不想通过井号标题汇总。
要点:想要哪个为第一列,就用哪个 .map( (x, i) => )。
示例文本
## A
<优点>
- 优点 1
- 优点 2
<缺点>
缺点 1
## B
<优点>优点
<缺点>缺点
代码
const dFile = dv.current()
const file = app.workspace.getActiveFile()
const headers = app.metadataCache.getFileCache(file).headings
.filter(p=> p.level == 2).map(p=> p.heading) // 表体第一项
const raws = ( await app.vault.readRaw(dFile.file.path) ).split('\n\n') // 分块
const getTitle = (arr, t)=> arr.filter(p=> p.startsWith(`<${t}>`)).map(p=> p.substring(t.length+2))
const bkt = ['优点', '缺点'].map(p=> getTitle(raws, p)) // 表体二三项
dv.table(['名称', '优点', '缺点'], headers.map((x, i)=> [x, ...bkt.map(p=> p[i])]))
- JS 方法:
.filter()、.map()、.split()、.startsWith()、.substring() - Ob API:
app.metadataCache.getFileCache()、app.workspace.getActiveFile()
注意:
- 该实例为汇总当前文档“二级标题、<优点>、<缺点>”,缺少相应内容报错是正常的,需修改为你的格式。
.filter(p=> p.level == 2)限制表体第一项为二级标题,可自行修改。.split('\n\n')以连续 2 个换行符切片,也即需空段分隔。
自然,如果不是同一块,比如<优点>后的内容间有空行,也是不适用的。.filter(p=> p.startsWith(`<${title}>`))匹配以<块标题>格式开头的项,不明白可以看看示例文本。
效果:

汇总 YAML
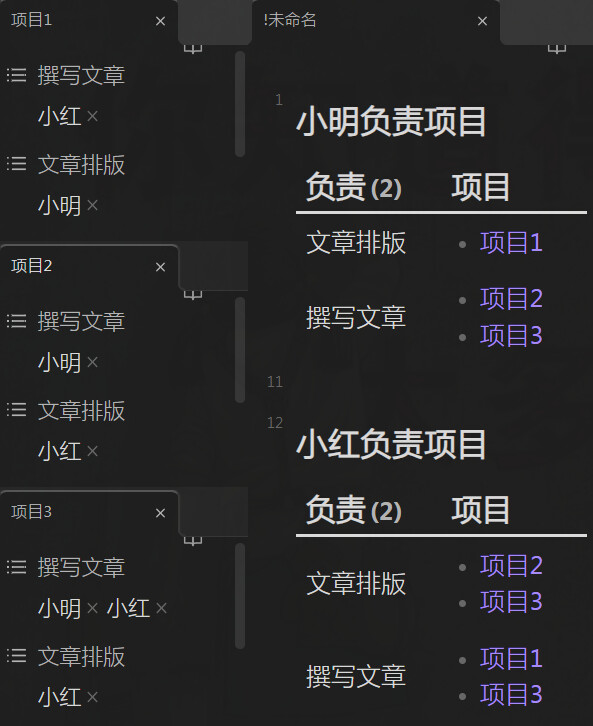
彩蛋:动态查询日期之间或之前,复制结果 MD 表格
要点:
- 需用
Number()将el3.value转为数字。提醒:JS 中'3'+1将输出31,很奇妙吧。 - Moment.js 需在时间加减操作前使用
.clone(),避免影响原值。 - 其余要点可参 b 站视频 Dataviewjs动态查询 及阅读本话题顶部链接的进阶教程自行研究。
代码
const MSG = document.getElementById('MSG')
dv.span('年月日 '); const el1 = dv.el('input')
dv.span(' 到年月日 '); const el2 = dv.el('input')
dv.span(' 或前 '); const el3 = dv.el('input')
dv.span(' 天 ')
el1.style.width = el2.style.width = '80px'
el3.style.width = '30px'
el1.onfocus = el2.onfocus = el3.onfocus = ()=> MSG.innerText = ''
const extract = async (dFiles)=> {
dv.el('button', '查找').onclick = ()=> qjt(); let md_table
dv.el('button', '复制结果').onclick = ()=> { new Notice('copy!'); navigator.clipboard.writeText(md_table) }
const table = dv.el('div')
function qjt() {
table.empty(); let tdata = [] /*清除旧数据*/
const d1 = moment(el1.value); const d2 = moment(el2.value)
const d3 = d1.clone().subtract(Number(el3.value)+1, 'd')
tdata = dFiles.filter(p=> el3.value
? moment(p.file.name).isBetween(d3, d1)
: moment(p.file.name).isBetween(d1.clone().subtract(1, 'd'), d2.clone().add(1, 'd'))
)
MSG.innerText = `共 ${tdata.length} 个`
tdata = tdata.map(p => [p.file.link, p.起床时间]) /*表体*/
dv.api.table( ['日期', '起床时间'], tdata, table, dv.component ) /*加表头成表*/
return md_table = dv.markdownTable( [`日期(${tdata.length})`, '起床时间'], tdata )
}; qjt()
}; extract(dv.pages(`"文件目录"`)) /*输出*/
- JS 方法:
.getElementById()、navigator.clipboard.writeText()、.clone()、Number()、.filter()、.map() - Moment.js:
moment()、.isBetween()、.subtract(1, 'd')、.add(1, 'd') dv.span()、dv.el()、dv.markdownTable()属于 Dv 插件。
效果 GIF
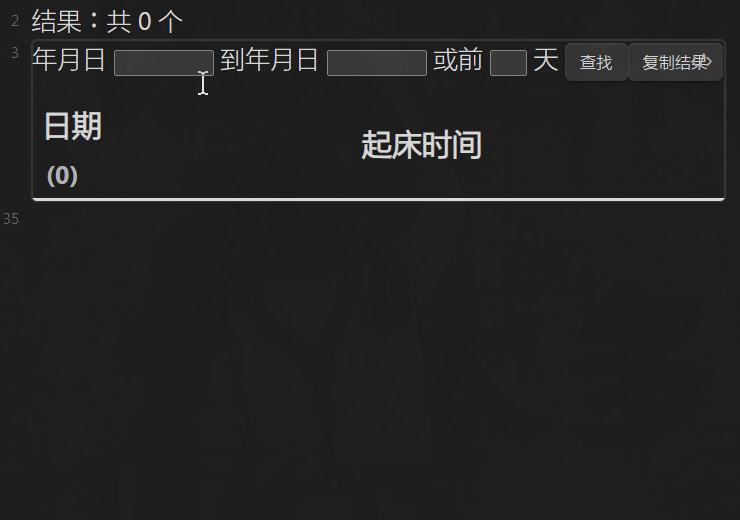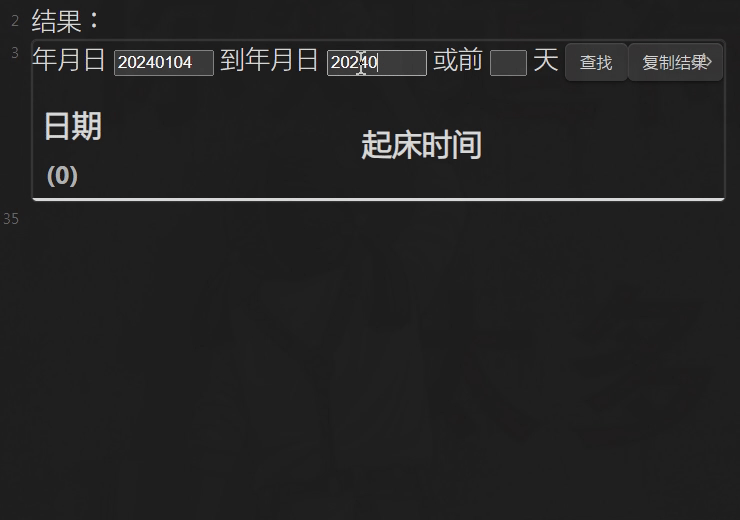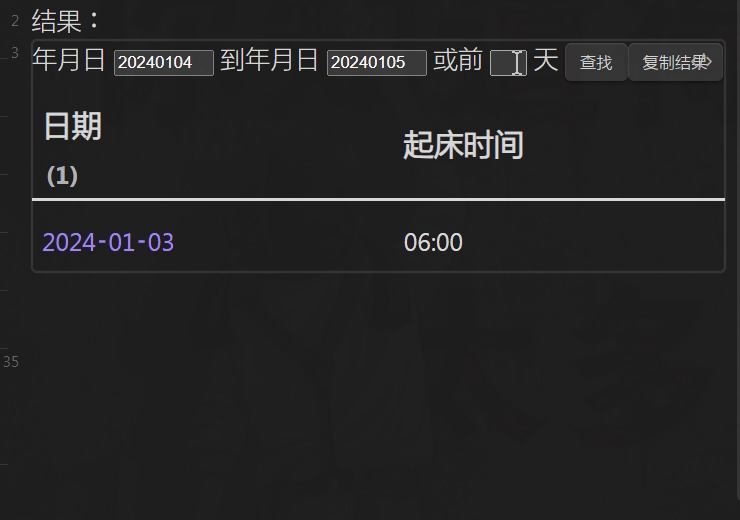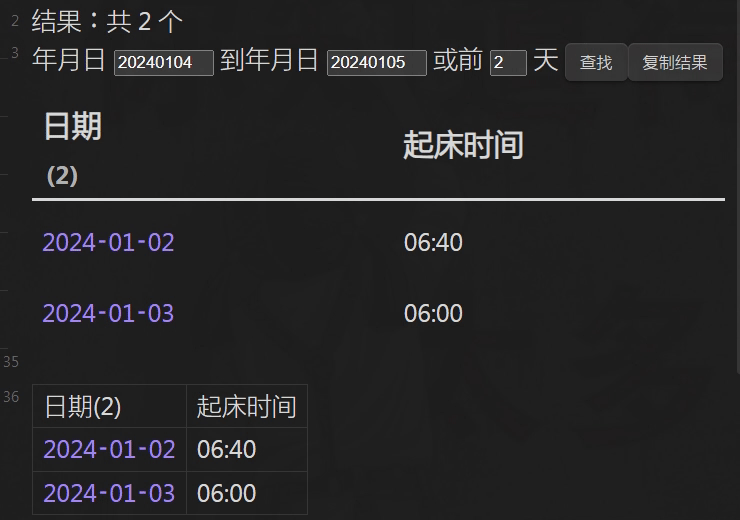
注意:
- 需自行在同文档 DvJS 代码块外任意位置写上
<span id='MSG' />,也即效果 GIF 中的 。
。
遇报错(setting 'innerText'),先确认写上,鼠标不放在此 span 上,刷新代码块。 - 以第 3 栏优先,3 栏都有值同 1、3 栏有值,执行“前几天”查询。
- 按引入帖要求,读取档名解析为时间,非读取元数据。若想改为读取元数据,可参“汇总近一周新建文档”自行修改。
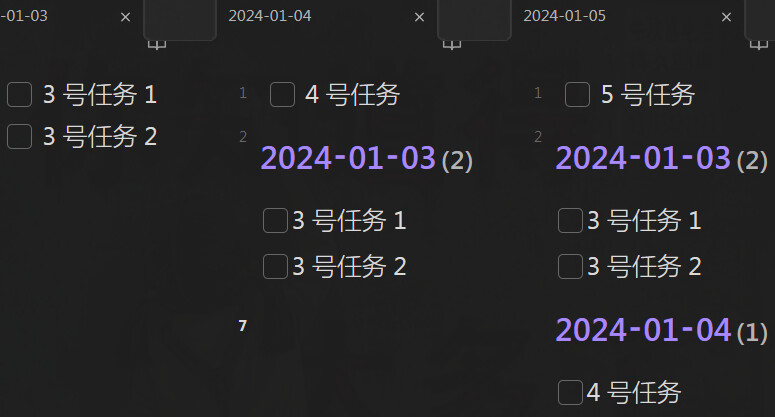
汇总 TASK
汇总日期前未完成任务
要点:通过 moment().unix() 读取档名解析为秒,进而进行比较。
代码
const dFiles = dv.pages(`"文件目录"`).filter(dFile=>
moment(dFile.file.name).unix() < moment(dv.current().file.name).unix()
)
dv.taskList(dFiles.file.tasks.filter(p=> !p.completed))
- JS 方法:
.filter() - Moment.js:
moment()、unix()
注意:
- 任务本身不存储时间,故无法直接按照任务本身创建时间筛选。通过手动添加内联注释进而筛选为另一种方法,可自行研究。
- 按引入帖要求,读取档名解析为时间,非读取元数据。若想改为读取元数据,可参“汇总近一周新建文档”自行修改。
效果:仅会汇总文件目录下当前文档日期前的未完成任务。
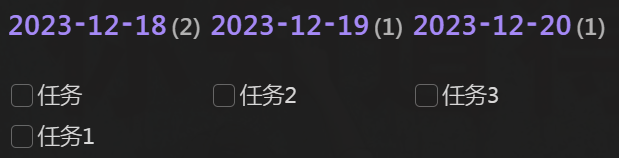
彩蛋:横排汇总近三日任务
配合 CSS,得以只需简单的代码,见原帖:Dataview 如何展示最近几天的待办事项 #13。
注意:原帖只用到了 Dataview。当然,想用 DvJS 也是可以的。
效果:
学习 DvJS,不耽于 DvJS。
本话题旨在大家看完后都能写出自己的 DataviewJS,额外需求仍请另建话题。
若出现不显示或报错,先尝试刷新代码块或重启 Ob,并认真阅读各“注意”下的说明。提醒:
- JS 负责生成元素,也即创建内容本身。
- CSS 负责改变样式,也即改变元素的呈现方式。
所以,一般诸如表格间距过大、表格内容行距过大、表格内容有的换行有的不换行等空白字符和换行显示问题(CSS white-space 属性),等问题,可能需要排查主题或 CSS,而非 DataviewJS。
闲聊:
