昨天的文章从信息组织学的视角分析了 KG 笔记法简单组织和快速查找的优点,今天这篇文章将从教育心理学的角度谈谈 KG 笔记法的第二个优点——关联已有知识。
正所谓“温故而知新,可以为师矣”,将新知识与已有知识关联起来是增强学习效果的一个重要技巧 (Dunlosky等, 2013)。我们在进行知识管理的时候也是如此——我们希望自己的知识有序化、系统化,相似的知识应该相互关联、融合,而非零散各处。那么,是否所有的笔记方法都能把知识关联起来呢?
散落各处的知识
假设我们现在在读一本粤菜菜谱,菜谱上讲解了正宗白切鸡好吃的原因——酱汁非常影响白切鸡的味道。我们觉得菜谱说得很好,想把这个观点记录下来,该怎么做呢?考虑到大多数人同时会使用分类法(文件夹)、叙词法(标签)、元信息法,再配合 MOC 来组织自己的笔记,因此这里也使用这四种方法:
-
首先,我们会创建一篇新的笔记,起名为《正宗白切鸡好吃的原因》。
-
随后,我们在这篇笔记里记录下相应内容“正宗白切鸡好吃的原因在于酱汁,酱汁非常影响白切鸡的味道……”。
-
记录完成后,我们会给这篇笔记打上“粤菜”、“白切鸡”两个标签,赋予“create time:2022/6/20”等元信息,然后将其放到“饮食”这个文件夹中,同时登记到《白切鸡 MOC》这篇笔记里。
这样做乍一看是没有问题的,非常符合知识管理的理念。但是,当未来我们遇到相似知识的时候,问题就来了。
假设一年过去了,我们读了另一本粤菜菜谱。菜谱里说正宗白切鸡好吃的原因不仅在于酱汁,鸡的种类也很重要。我们觉得这本菜谱说得也有道理,也想把这个观点记下来。但是,因为过去了一年,我们并不记得之前记录了相似的笔记。于是,我们创建了一篇名为《鸡的品种影响白切鸡的味道》的笔记,并在其中记录了具体内容,然后给其打上“粤菜”、“白切鸡”两个标签,赋予“create time:2023/8/10”等元信息,最后将其放到“饮食”这个文件夹中,同时登记到《白切鸡 MOC》这篇笔记里。
过了两天,一个朋友突然给我们发了条微信消息,问我们有哪些因素会影响白切鸡的味道。为了解答朋友的疑问,我们开始在笔记库里查找相关的笔记:打开“饮食”文件夹,发现里面有百余篇与做菜相关的笔记,得一篇篇翻查;搜索“白切鸡”标签,也返回了几十篇笔记,也得一篇篇翻查;搜索元字段,这似乎并帮不上什么忙;检查《白切鸡 MOC》,发现里面也登记了几十篇笔记……最终我们还是只能寄希望于全文搜索,让软件以“白切鸡”、“味道”这个两关键词进行搜索。但结果还是给我们返回了几十篇笔记。迫不得已,我们只能把两天前记的《鸡的品种影响白切鸡的味道》发过去……
上面这个例子就是我在使用 KG 笔记法之前的真实写照,我相信很多人也遇到过类似的情景。目前主流的笔记方法,并不能很好的将相似的知识关联、融合起来,甚至可能会产生知识知识冗余——同样的内容一年前放到《正宗白切鸡好吃的原因》里,一年后遗忘了可能就会以《白切鸡好吃的关键》为题再记一次。导致这种问题的根本原因在于我们使用的检索标识专指度过低,简单来说就是所用的分类和标签包含范围太大,检索时会返回大量的信息。
说到这里,肯定有人会说使用范围更窄的标签或 MOC 不就行了。确实如此,但问题在于我们给笔记安排标签或 MOC 并不是一蹴而就的,而是不断迭代的:一开始对粤菜不了解的时候,我们对白切鸡的笔记可能只会打上“粤菜”的标签,或是把它放到《粤菜 MOC》中;只有我们对粤菜了解了,对白切鸡熟知了,我们才会选用“白切鸡”标签或《白切鸡 MOC》。所以这里还涉及一个重新打标签或重新登记 MOC 的过程。而这个过程往往又是非常麻烦的:我们需要先逐一翻阅包含“粤菜”标签或是登记在《粤菜 MOC》中的成百上千篇笔记,然后选出与白切鸡有关的几十篇笔记,再为它们重新赋予“白切鸡”标签或登记到《白切鸡 MOC》中。这般高昂的整理成本使得大多数人都不会重新整理标签或 MOC。
受控标题,自然而然的知识融合
那么 KG 笔记法是怎么规避这个问题的呢?方法很简单,借助受控制的标题,我们可以自然地将同一主题的内容汇集到一篇笔记里。并且,当这篇笔记里关于某细分主题的内容足够多时,我们可以方便快速地将这部分内容独立成为一篇新的笔记。
还是刚刚的例子。当我们第一次看到“酱汁非常影响白切鸡的味道”这个观点的时候,由于这个观点的主题是“白切鸡”,因此我们会在《白切鸡》这篇笔记中记录这个观点。同时,因为观点讲述的是“影响味道的因素”这一细分主题,我们会在《白切鸡》这篇笔记中创建“# 影响味道的因素”章节,将观点记录在该章节下。而当我们后来看到“鸡的品种影响白切鸡的味道”这一观点时,记录过程也是类似的:由于这个观点的主题是“白切鸡”,因此我们还是在《白切鸡》这篇笔记中记录这个观点;同时,因为观点讲述的是“影响口味的因素”这一细分主题,我们只需在《白切鸡》这篇笔记中创建“# 建立影响味道的因素”章节,将观点记录在该章节下——而这个步骤我们之前就已经完成了,两个相同主题的观点就会汇集到同篇笔记的同个章节中。综上所述,KG 笔记法可以自然而然的把新知识与已有知识融合起来。
这时肯定有人又会说,这样做的话笔记不就会很长了吗?确实会很长。但因为我们已经通过小标题划分出了细分内容,所以当我们觉得笔记篇幅过大时,可以轻松地将各章节独立成为新的笔记。比如,我们可以将“# 影响味道的因素”这一章节单独出来,形成一篇名为《影响白切鸡味道的因素》的笔记。(当然,由于这个题目并不是一个固定主题短语,因此我不推荐这么做。)
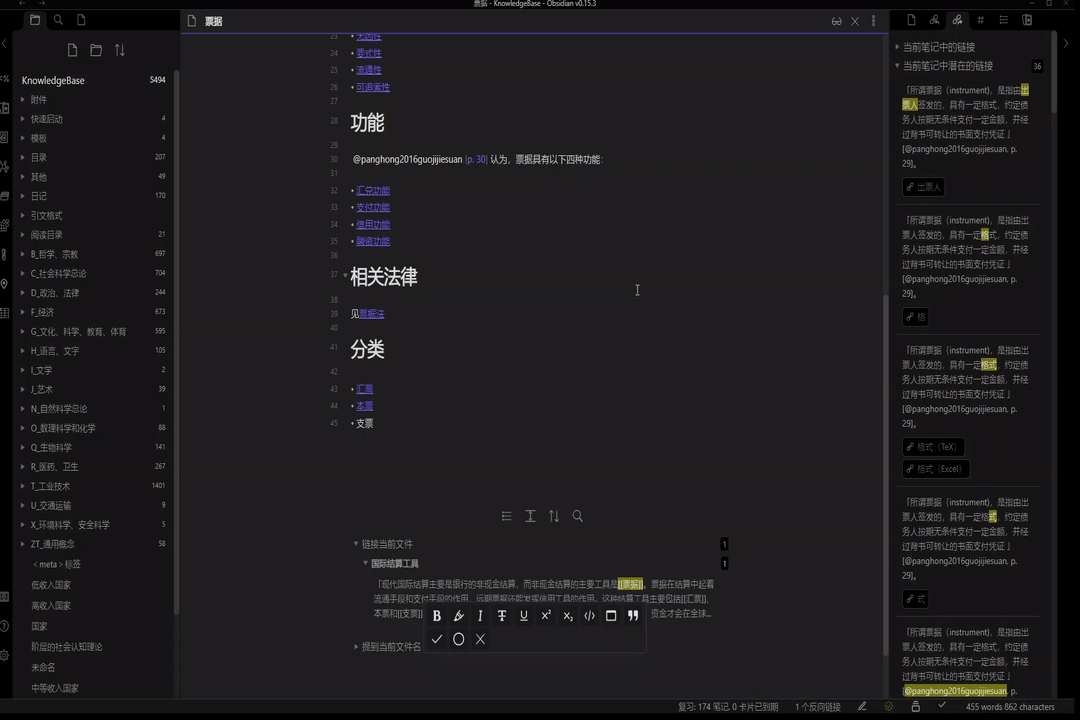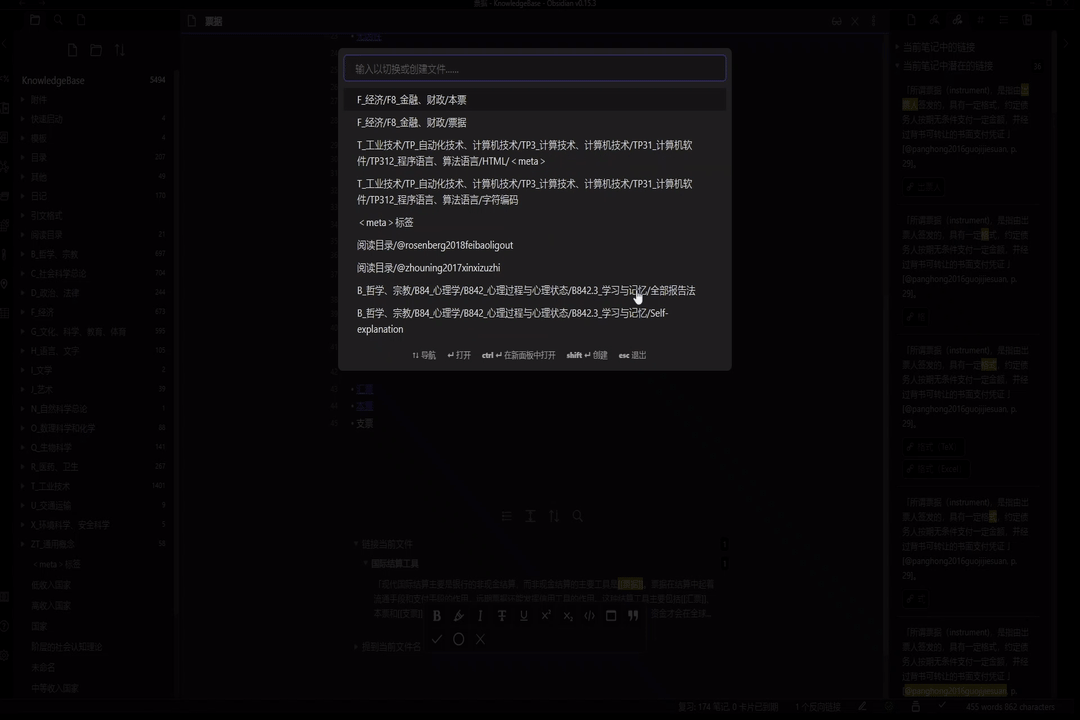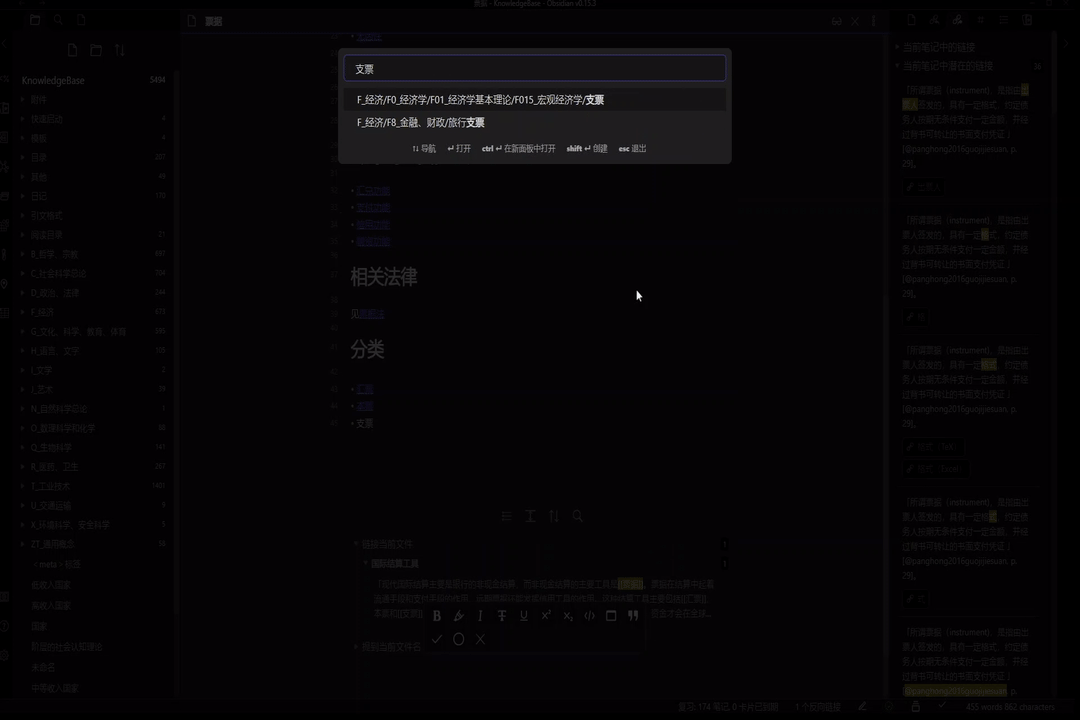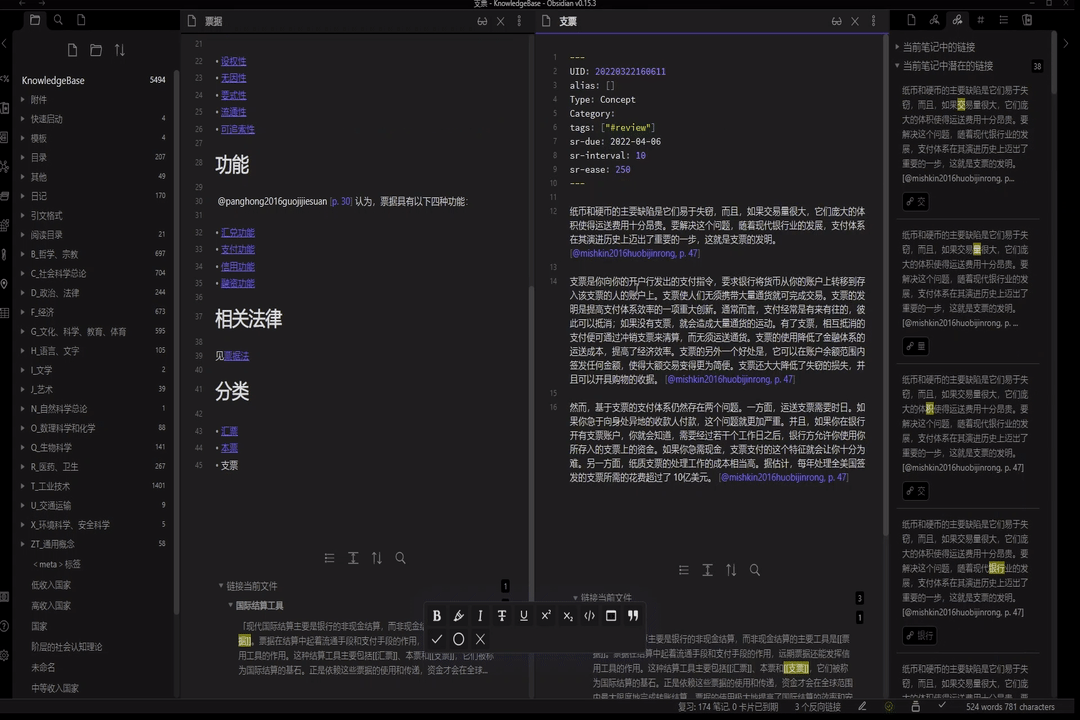
举一个实际的例子。以我最近在学的国际结算相关知识为例。当我想记下书中关于支票的内容时,由于内容是关于“支票”这一主题的,我只要创建一篇名为《支票》的笔记,将内容记录于其中即可。而当我在 Obsidian 的快速切换输入“支票”二字并回车之后,Obsidian 给我打开了《支票》这篇笔记——原来我在一年前看货币金融学教材的时候,就已经记录了与“支票”这一主题相关的内容。接下来需要我要做的就是比较不同书籍中这些内容的异和同。
不再沉默的潜在链接
受控标题的另一大好处在于可以充分利用双链笔记软件的潜在链接功能,让软件自动嗅探知识间的关联。
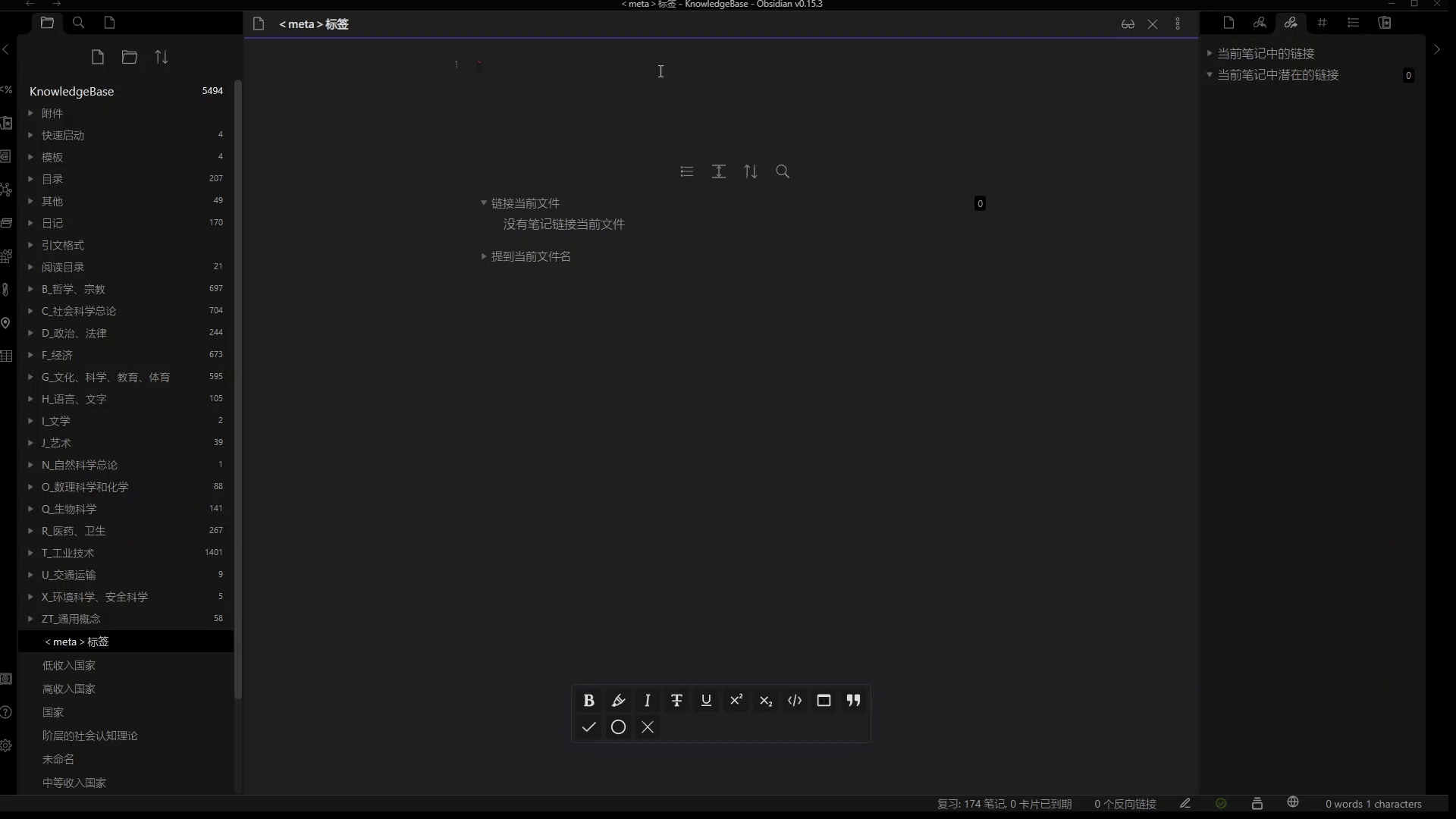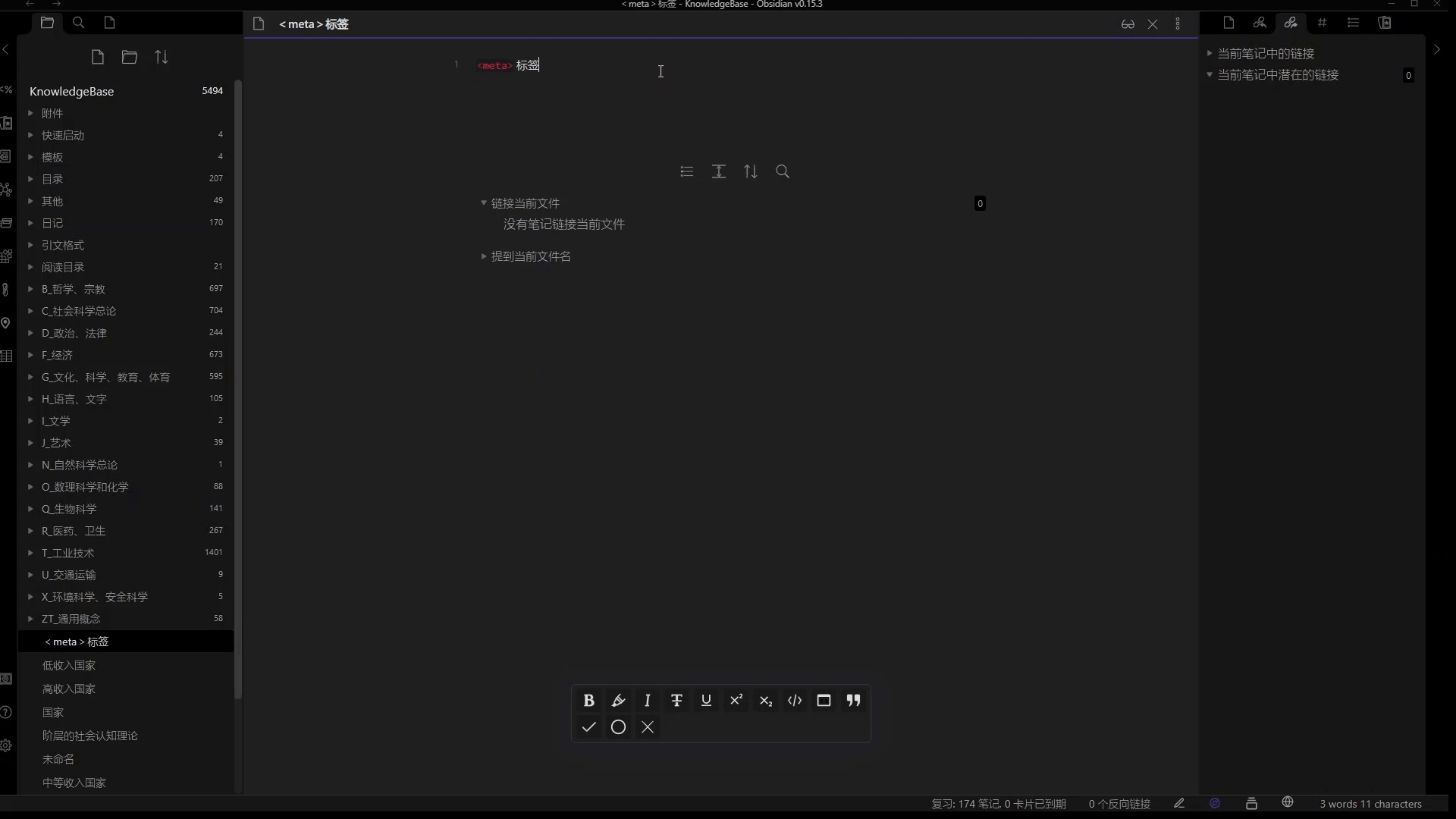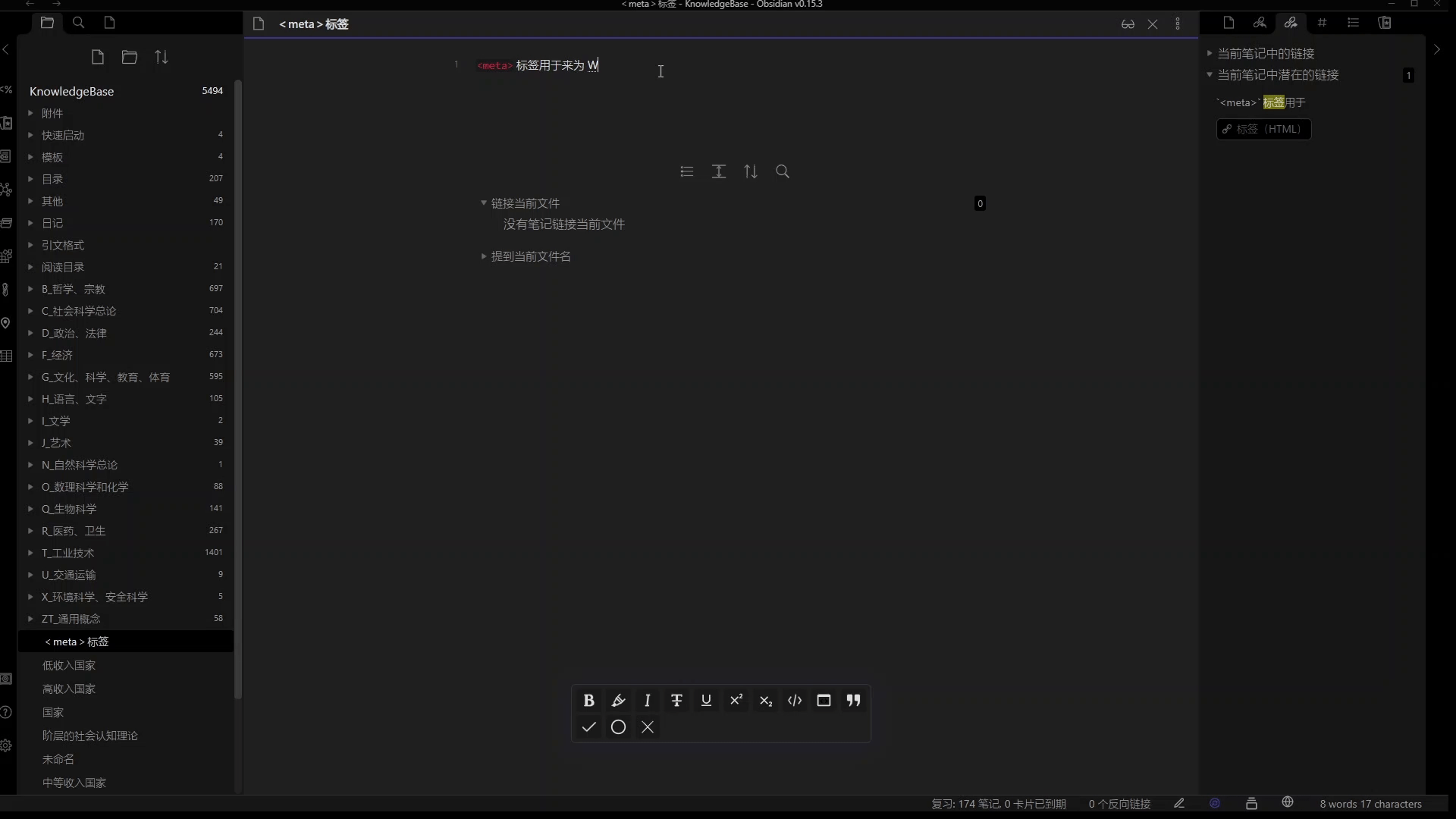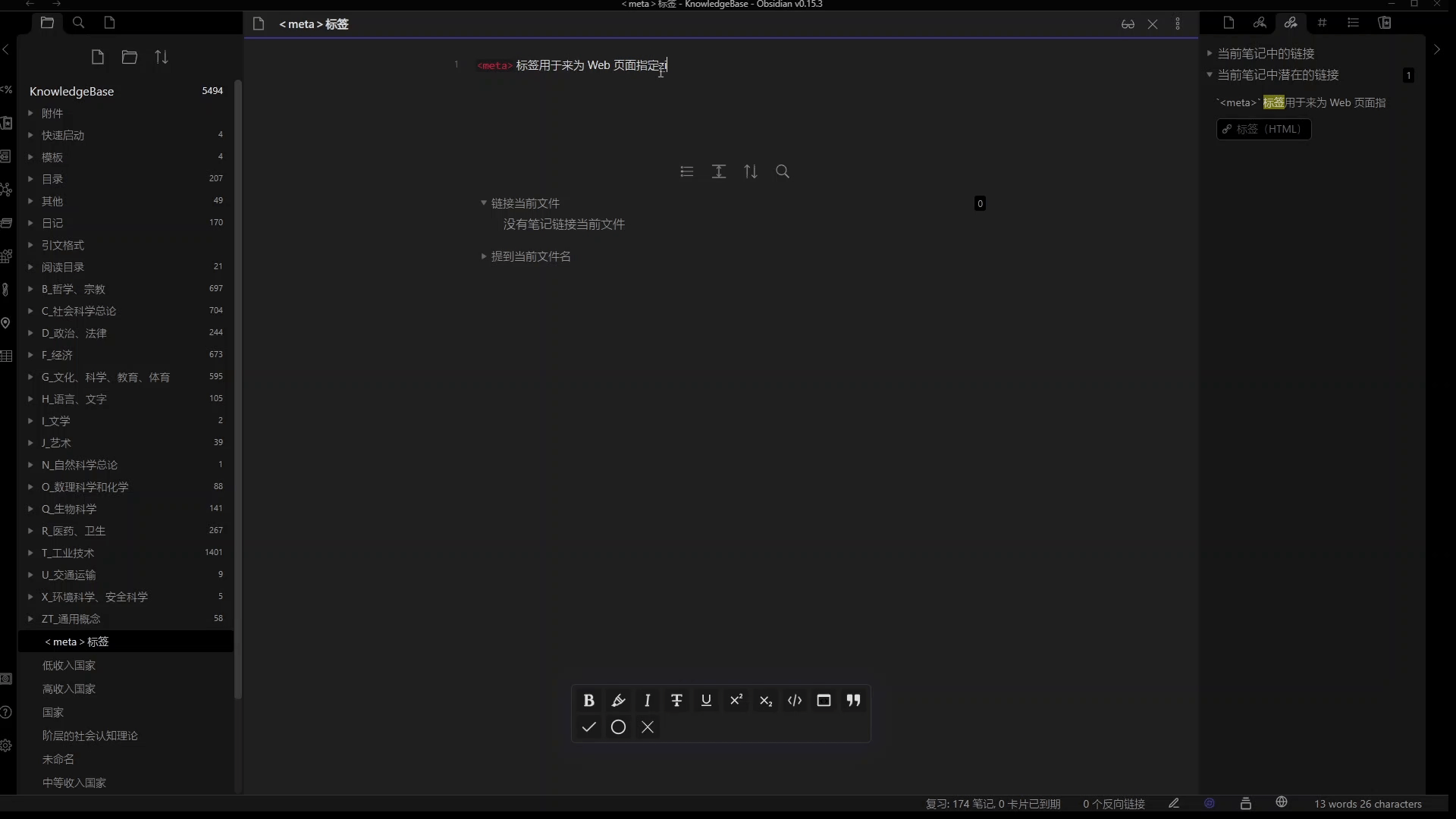
举个例子,比如我在学 html 的时候,我在《标签》这篇笔记中记录了该标签的作用:“标签用来为 Web 页面指定字符编码”。而就在我输入最后一个字后,Obsidian 的出链面板马上就提示了“字符编码”是一条潜在链接。我当时非常奇怪,并不记得“字符编码”是什么。但顺着链接点开笔记一看,原来这是我大一计算机基础课程里的计算机字符编码的内容。这样,时隔多年的知识就被 Obsidian 联系起来了,我既复习了原先学过的字符编码的知识,又将标签这个新知识与旧知识关联了起来,更好的理解了标签的作用。
为什么只有受控标题才有如此效果呢?原因很简单,因为受控标题去除了自然语言的歧义性,这使得标题可以在日常记录中大量复现。比如,如果我们以《标签的用法》作为标题,那么软件自然无法嗅探,因为我们可能在笔记中会用“标签的作用”来表达相同的内容。但如果我们仅使用《标签》,那么无论是“标签的用法”,还是“标签的作用”,都能匹配到这个标题。
结尾
在使用 KG 笔记法的这段时间中,我真正在 Obsidian 中感受到了一种融会贯通的感觉。不同学科的知识都能在 Obsidian 的帮助下产生关联,这让我能很好地将当前所学的新知识与已有的旧知识来联系起来,让我温故而知新。同时,相同主题的内容也能汇集在一篇笔记中,让我在学术研究时能更方便地比较不同学者对于同一问题的观点,提升科研效率。
Dunlosky, J., Rawson, K. A., Marsh, E. J., Nathan, M. J., & Willingham, D. T. (2013). Improving Students’ Learning With Effective Learning Techniques: Promising Directions From Cognitive and Educational Psychology. Psychological Science in the Public Interest, 14(1), 4–58. https://doi.org/10.1177/1529100612453266