我的每篇日记里都有一个二级标题 ”## 任务“,请问我怎么使用 dataview 把这个二级标题下的所有内容过滤出来?谢谢!![]()
![]()
不知道如何用dataview。
但是用这个插件可以达到你说的目的。
在设置中把标签更改为## 任务就可以了。
1 个赞
任务里面都是待办事项吧,你也可以看看这个教程。
1 个赞
代码如下
```dataview
task
where meta(section).subpath = "1-6级标题名称"
```
3 个赞
谢谢你的回复。请问我想获取标题下的所有内容(内容不仅是待办事项),这个代码怎么写? 
请问解决了吗,我也有这个需求
汇总【指定小标题下的全部内容】,包括task、普通文本等
```dataviewjs
//输入目标小标题(含#),例如:#### 项目进度条
const header = '#### 项目进度条'
// 按【路径或文件夹、文件名、标签】筛选并按修改时间降序排列
const pages = dv.pages('"00数据管理" or ""').filter(p => p.file.name.includes("") && !p.file.path.includes("template")).filter(p => p.file.name.includes("") || p.file.name.includes("")).sort(p=>p.file.mtime,"desc");
// This regex will return text from the Summary header, until it reaches
// the next header, a horizontal line, or the end of the file
const regex = new RegExp(`\n${header}\r?\n(.*?)(\n#+ |\n---|$)`, 's')
for (const page of pages) {
const file = app.vault.getAbstractFileByPath(page.file.path)
// Read the file contents
const contents = await app.vault.read(file)
// Extract the summary via regex
const summary = contents.match(regex)
//显示全部包括空结果if (summary) {
//不显示空结果if (summary && summary[1].trim()) {
if (summary && summary[1].trim()) {
// Output the header and summary
dv.header(2, page.file.link)
//或者dv.header(2, '[[' + file.basename + ']]')
dv.paragraph(summary[1].trim())
}
}
```
7 个赞
非常感谢!功能得到了实现!
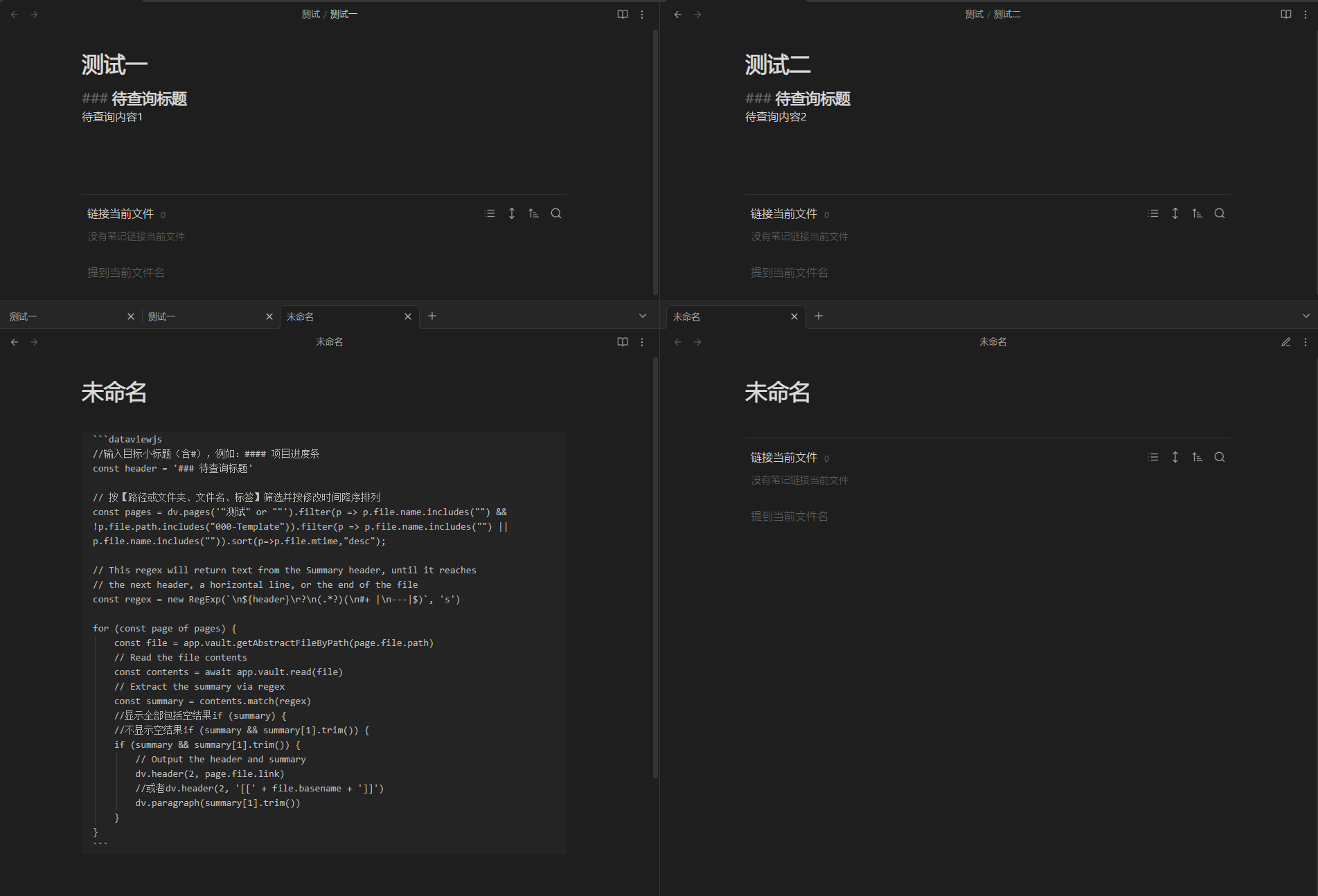
试下在测试文件的首行插入一个空行
汇总【指定小标题下的全部内容】,包括task、普通文本等
2023-05-29更新:对代码做了完善,支持正则匹配,等等
```dataviewjs
const headers = ["文件名", "内容"];
// 目标小标题,支持正则匹配
const targetHeading = /^.{0,9}目标小标题(不含#).{0,4}$/i;
// 按【路径或文件夹、文件名、标签】筛选并按修改时间降序排列
const pages = dv.pages('!"00数据管理"').filter(p => !p.file.path.includes("龥") && /^(?!.*(排除的关键词2|模板\-)).*/.test(p.file.name)).sort(p=>p.file.mtime,"desc");
const pagesArray = pages.array();
const targetPagesArray = [];
const contentArray = [];
for(let i = 0; i < pagesArray.length;i++) {
const currentFile = pagesArray[i].file;
const sectionCache = app.metadataCache.getFileCache(currentFile);
const headingCache = sectionCache.headings?.filter(h => {
return targetHeading.test(h.heading)
})
if(headingCache?.length > 0) {
const headingRange = {
start: headingCache[0].position.start.offset,
end: headingCache[0].position.end.offset,
};
const heading = headingCache[0].heading;
const content = await dv.io.load(currentFile.path);
if(!content) continue;
const headingInRange = content.slice(headingRange.start, headingRange.end);
const contentInNextRange = content.slice(headingRange.end);
const level = headingInRange.match(/#{1,6}/)[0].length;
const nextHeadingRegex = new RegExp(`(^|\\n)#{1,${level}}\\s`);
const position = contentInNextRange.match(nextHeadingRegex);
let contentRange;
let positionEnd;
if(position) {
positionEnd = headingRange.end + position?.index;
contentRange = content.slice(headingRange.end, positionEnd);
}else {
contentRange = content.slice(headingRange.end);
}
const link = dv.sectionLink(currentFile.name, heading)
contentArray.push({
file: link,
content: contentRange,
})
}
//将结果限制在50条以内
if (contentArray.length >= 50) {
break;
}
}
dv.table(headers, contentArray.map(
p =>
[
p.file,
p.content,
]
))
5 个赞
谢谢,解决了,原来是这样 ![]()
如果只提取里面的标题,该怎么解决呢,比如提取:今日任务 下面的所有二级标题?
想问一下,能不能加个标签功能,我想过滤出符合标签的所有文章的各级标题标题
你好,首先非常感谢你所写的内容。我已经在使用你所写的代码了,有个小问题想请教一下,在OB的预览视图下,会呈现出
Evaluation Error: SyntaxError: Unexpected token ‘&’
at DataviewInlineApi.eval (plugin:dataview:18404:21)
at evalInContext (plugin:dataview:18405:7)
at asyncEvalInContext (plugin:dataview:18412:16)
at DataviewJSRenderer.render (plugin:dataview:18436:19)
at DataviewJSRenderer.onload (plugin:dataview:18020:14)
at e.load (app://obsidian.md/app.js:1:631581)
at DataviewApi.executeJs (plugin:dataview:18954:18)
at DataviewPlugin.dataviewjs (plugin:dataview:19559:18)
at eval (plugin:dataview:19478:124)
at app://obsidian.md/app.js:1:1189428
这样的问题。请问应当如何解决?
dv.pages 支持按标签筛选的
根据报错提示,是代码中某个地方 多出了或缺失了 & 符号
小白,哪个地方写标签?谢谢啦
我是把这一行中的const targetHeading = /^.{0,9}目标小标题(不含#).{0,4}$/i; 目标小标题(不含#) 这几个给替换成目标值了。
我是纯文本复制粘贴到word里,然后再复制粘贴进OB中,是代码中少了些什么?另外,我发现它可能会出现一个问题,就是查询到的结果显示出来是OB中下一个文件夹的内容。比如说我这里本来是想要查看【01-读书笔记】文件夹中本年度第28周的内容。但实际是显示出来是【02-日记】文件夹中本年度第27周的内容。不知道是哪里出了问题?
const headers = ["文件名", "内容"];
// 目标小标题,支持正则匹配
const targetHeading = /^.{0,9}工作.{0,4}$/i;
// 按【路径或文件夹、文件名、标签】筛选并按修改时间降序排列
const pages = dv.pages('!"01-读书笔记"').filter(p => !p.file.path.includes("第27周") && /^(?!.*(排除的关键词2|模板\-)).*/.test(p.file.name)).sort(p=>p.file.ctime,"desc");
const pagesArray = pages.array();
const targetPagesArray = [];
const contentArray = [];
for(let i = 0; i < pagesArray.length;i++) {
const currentFile = pagesArray[i].file;
const sectionCache = app.metadataCache.getFileCache(currentFile);
const headingCache = sectionCache.headings?.filter(h => {
return targetHeading.test(h.heading)
})
if(headingCache?.length > 0) {
const headingRange = {
start: headingCache[0].position.start.offset,
end: headingCache[0].position.end.offset,
};
const heading = headingCache[0].heading;
const content = await dv.io.load(currentFile.path);
if(!content) continue;
const headingInRange = content.slice(headingRange.start, headingRange.end);
const contentInNextRange = content.slice(headingRange.end);
const level = headingInRange.match(/#{1,6}/)[0].length;
const nextHeadingRegex = new RegExp(`(^|\\n)#{1,${level}}\\s`);
const position = contentInNextRange.match(nextHeadingRegex);
let contentRange;
let positionEnd;
if(position) {
positionEnd = headingRange.end + position?.index;
contentRange = content.slice(headingRange.end, positionEnd);
}else {
contentRange = content.slice(headingRange.end);
}
const link = dv.sectionLink(currentFile.name, heading)
contentArray.push({
file: link,
content: contentRange,
})
}
//将结果限制在7条以内
if (contentArray.length >= 7) {
break;
}
}
dv.table(headers, contentArray.map(
p =>
[
p.file,
p.content,
]
))