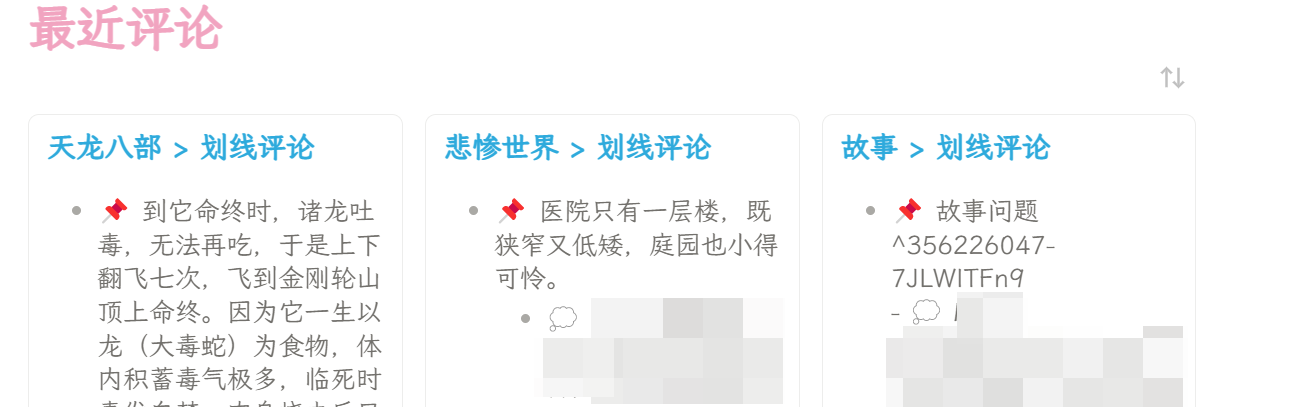
成果2:
但是上面这个代码生成的随机摘抄只有带符号的一段,而我希望能将带有自己评论的、同时存在好几段的摘抄一起随机显示。
因为微信读书插件的笔记是分为高亮划线和划线评论两部分,其中划线评论是以三级标题的形式进行收录,所以我需要能显示三级标题下所有内容的dataviewjs代码,参考这个帖子的代码【求助】如何使用 dataview 插件过滤出某个二级标题下的内容 - 疑问解答 - Obsidian 中文论坛做了改进,能够显示最近的三条划线评论:
const headers = ["文件名", "内容"];
// 目标小标题,支持正则匹配
const targetHeading = /^.{0,9}划线评论.{0,4}$/i;
// 按【路径或文件夹、文件名、标签】筛选并按修改时间降序排列
const pages = dv.pages('!"00Inbox"').filter(p => !p.file.path.includes("龥") && /^(?!.*(排除的关键词2|模板\-)).*/.test(p.file.name)).sort(p=>p.file.mtime,"desc");
const pagesArray = pages.array();
const targetPagesArray = [];
const contentArray = [];
for(let i = 0; i < pagesArray.length;i++) {
const currentFile = pagesArray[i].file;
const sectionCache = app.metadataCache.getFileCache(currentFile);
const headingCache = sectionCache.headings?.filter(h => {
return targetHeading.test(h.heading)
})
if(headingCache?.length > 0) {
const headingRange = {
start: headingCache[0].position.start.offset,
end: headingCache[0].position.end.offset,
};
const heading = headingCache[0].heading;
const content = await dv.io.load(currentFile.path);
if(!content) continue;
const headingInRange = content.slice(headingRange.start, headingRange.end);
const contentInNextRange = content.slice(headingRange.end);
const level = headingInRange.match(/#{1,6}/)[0].length;
const nextHeadingRegex = new RegExp(`(^|\\n)#{1,${level}}\\s`);
const position = contentInNextRange.match(nextHeadingRegex);
let contentRange;
let positionEnd;
if(position) {
positionEnd = headingRange.end + position?.index;
contentRange = content.slice(headingRange.end, positionEnd);
}else {
contentRange = content.slice(headingRange.end);
}
const link = dv.sectionLink(currentFile.name, heading)
contentArray.push({
file: link,
content: contentRange,
})
}
//将结果限制在3条以内
if (contentArray.length >= 3) {
break;
}
}
dv.table(headers, contentArray.map(
p =>
[
p.file,
p.content,
]
))
成果如下: