最近在折腾将weread plugin同步的读书笔记在obsidian的主页随机显示三条摘抄,目前有了一定成果,但是还是有些问题,希望能有大佬帮忙解决一下。
2 个赞
成果1. 参考Obsidian随机生成读书笔记这个帖子里的代码,将生成的读书笔记根据关键词筛选,用dv.paragraph进行展示,因为自动生成的微信读书笔记每一个摘抄都有![]() ,我将原贴的标签#Quote换成
,我将原贴的标签#Quote换成![]() ,就可以了,代码如下:
,就可以了,代码如下:
//使用时修改关键词即可
const term = "📌"
const files = app.vault.getMarkdownFiles()
const arr = files.map(async ( file) => {
const content = await app.vault.cachedRead(file)
const lines = content.split("\n").filter(line => line.contains(term))
return lines })
function generateArray (start, end) { return Array.from(new Array(end + 1).keys()).slice(start) }
Promise.all(arr).then(values => {
//不包含本文件
let noteArr = values.flat().filter(note => !note.includes("const term ="))
//生成一个连续数值的数组
let arrNum = generateArray(0,noteArr.length-1)
let result = [ ]
let ranNum = 3
for (let i = 0; i < ranNum; i++) {
var ran = Math.floor(Math.random() * (arrNum.length - i))
result.push(arrNum[ran])
arrNum[ran] = arrNum[arrNum.length - i - 1]
}
for(let i=0; i< result.length;i++){
let j = result[i]
dv.paragraph(`${noteArr[j]}`)
}
})
成果如下:

1 个赞
成果2:
但是上面这个代码生成的随机摘抄只有带符号的一段,而我希望能将带有自己评论的、同时存在好几段的摘抄一起随机显示。
因为微信读书插件的笔记是分为高亮划线和划线评论两部分,其中划线评论是以三级标题的形式进行收录,所以我需要能显示三级标题下所有内容的dataviewjs代码,参考这个帖子的代码【求助】如何使用 dataview 插件过滤出某个二级标题下的内容 - 疑问解答 - Obsidian 中文论坛做了改进,能够显示最近的三条划线评论:
const headers = ["文件名", "内容"];
// 目标小标题,支持正则匹配
const targetHeading = /^.{0,9}划线评论.{0,4}$/i;
// 按【路径或文件夹、文件名、标签】筛选并按修改时间降序排列
const pages = dv.pages('!"00Inbox"').filter(p => !p.file.path.includes("龥") && /^(?!.*(排除的关键词2|模板\-)).*/.test(p.file.name)).sort(p=>p.file.mtime,"desc");
const pagesArray = pages.array();
const targetPagesArray = [];
const contentArray = [];
for(let i = 0; i < pagesArray.length;i++) {
const currentFile = pagesArray[i].file;
const sectionCache = app.metadataCache.getFileCache(currentFile);
const headingCache = sectionCache.headings?.filter(h => {
return targetHeading.test(h.heading)
})
if(headingCache?.length > 0) {
const headingRange = {
start: headingCache[0].position.start.offset,
end: headingCache[0].position.end.offset,
};
const heading = headingCache[0].heading;
const content = await dv.io.load(currentFile.path);
if(!content) continue;
const headingInRange = content.slice(headingRange.start, headingRange.end);
const contentInNextRange = content.slice(headingRange.end);
const level = headingInRange.match(/#{1,6}/)[0].length;
const nextHeadingRegex = new RegExp(`(^|\\n)#{1,${level}}\\s`);
const position = contentInNextRange.match(nextHeadingRegex);
let contentRange;
let positionEnd;
if(position) {
positionEnd = headingRange.end + position?.index;
contentRange = content.slice(headingRange.end, positionEnd);
}else {
contentRange = content.slice(headingRange.end);
}
const link = dv.sectionLink(currentFile.name, heading)
contentArray.push({
file: link,
content: contentRange,
})
}
//将结果限制在3条以内
if (contentArray.length >= 3) {
break;
}
}
dv.table(headers, contentArray.map(
p =>
[
p.file,
p.content,
]
))
成果如下:
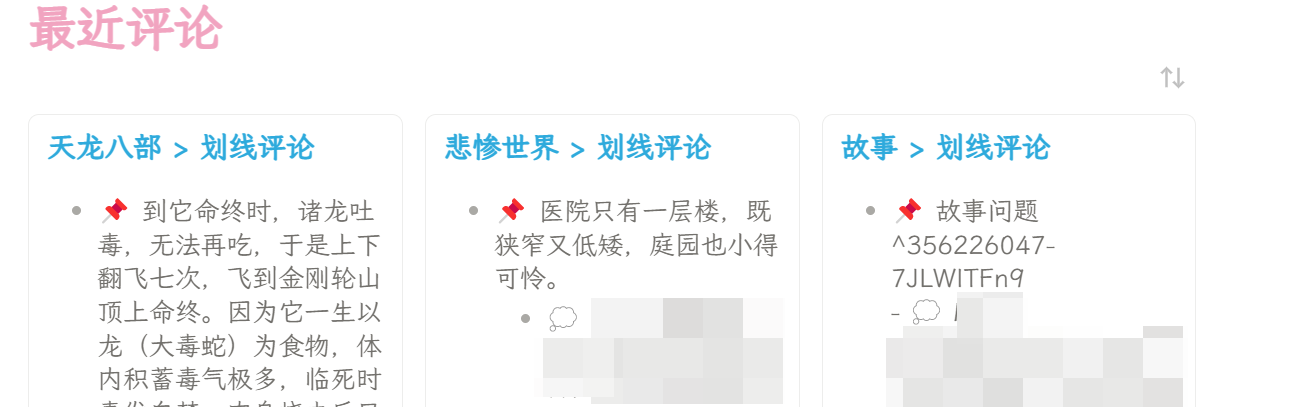
1 个赞
成果3:
但是,上面这段代码只有最近三条,而我的本意是希望能随机三条,所以我又在此基础上修改了代码(这一个我不确定是自己改的还是抄的别人的了,暂且认为是自己改的吧),进行了随机显示:
const headers = ["文件名", "内容"];
// 目标小标题,支持正则匹配
const targetHeading = /^.{0,9}划线评论.{0,4}$/i;
// 按【路径或文件夹、文件名、标签】筛选并按修改时间降序排列
const pages = dv.pages('!"00Inbox"').filter(p => !p.file.path.includes("龥") && /^(?!.*(排除的关键词2|模板\-)).*/.test(p.file.name)).sort(p=>p.file.mtime,"desc");
const pagesArray = pages.array();
const targetPagesArray = [];
const contentArray = [];
// 获取所有符合条件的小标题
for(let i = 0; i < pagesArray.length;i++) {
const currentFile = pagesArray[i].file;
const sectionCache = app.metadataCache.getFileCache(currentFile);
const headingCache = sectionCache.headings?.filter(h => {
return targetHeading.test(h.heading) })
if(headingCache?.length > 0) {
const headingRange = {
start: headingCache[0].position.start.offset,
end: headingCache[0].position.end.offset,
};
const heading = headingCache[0].heading;
const content = await dv.io.load(currentFile.path);
if(!content) continue;
const headingInRange = content.slice(headingRange.start, headingRange.end);
const contentInNextRange = content.slice(headingRange.end);
const level = headingInRange.match(/#{1,6}/)[0].length;
const nextHeadingRegex = new RegExp(`(^|\\n)#{1,${level}}\\s`);
const position = contentInNextRange.match(nextHeadingRegex);
let contentRange;
let positionEnd;
if(position) {
positionEnd = headingRange.end + position?.index;
contentRange = content.slice(headingRange.end, positionEnd);
}else {
contentRange = content.slice(headingRange.end);
}
const link = dv.sectionLink(currentFile.name, heading)
contentArray.push({
file: link,
content: contentRange,
})
}
}
// 随机选择三个小标题下的内容
const randomContentArray = [];
const selectedIndices = [];
while (randomContentArray.length < 3 && selectedIndices.length < contentArray.length) {
const randomIndex = Math.floor(Math.random() * contentArray.length);
if (!selectedIndices.includes(randomIndex)) { randomContentArray.push(contentArray[randomIndex]);
selectedIndices.push(randomIndex);
}
}
dv.table(headers, randomContentArray.map(
p => [
p.file,
p.content,
]
)
)
但是,这段代码依旧有问题,只能显示每一个读书笔记文件的第一个划线评论,没办法显示后续的“划线评论”三级标题的内容,所以我结合chatgpt进行了修改,代码如下:
const headers = ["文件名", "内容"];
const targetHeading = /^.{0,9}划线评论.{0,4}$/i;
const pages = dv.pages('!"00Inbox"').filter(p => !p.file.path.includes("龥") && /^(?!.*(排除的关键词2|模板\-)).*/.test(p.file.name)).sort(p=>p.file.mtime,"desc");
const pagesArray = pages.array();
const contentArray = [];
for (let i = 0; i < pagesArray.length; i++) {
const currentFile = pagesArray[i].file;
const sectionCache = app.metadataCache.getFileCache(currentFile);
const headingCache = sectionCache.headings?.filter(h => targetHeading.test(h.heading));
if (headingCache?.length > 0) {
const content = await dv.io.load(currentFile.path);
if (!content) continue;
for (let j = 0; j < headingCache.length; j++) {
const headingRange = {
start: headingCache[j].position.start.offset,
end: headingCache[j].position.end.offset,
};
const heading = headingCache[j].heading;
const headingInRange = content.slice(headingRange.start, headingRange.end);
const contentInNextRange = content.slice(headingRange.end);
const level = headingInRange.match(/#{1,6}/)[0].length;
const nextHeadingRegex = new RegExp(`(^|\\n)#{1,${level}}\\s`);
const position = contentInNextRange.match(nextHeadingRegex);
let contentRange;
let positionEnd;
if (position) {
positionEnd = headingRange.end + position.index;
contentRange = content.slice(headingRange.end, positionEnd);
} else {
contentRange = content.slice(headingRange.end);
}
const link = dv.sectionLink(currentFile.name, heading);
contentArray.push({
file: link,
content: contentRange,
});
}
}
}
const randomContentArray = [];
while (randomContentArray.length < 3 && contentArray.length > 0) {
const randomIndex = Math.floor(Math.random() * contentArray.length);
randomContentArray.push(contentArray[randomIndex]);
contentArray.splice(randomIndex, 1);
}
dv.table(headers, randomContentArray.map(p => [p.file, p.content]));
问题:
上面的成果3的第二段代码终于实现了我一开始的目的,即随机显示三条所有三级标题“划线评论”下的内容,但是我通过检查发现,左侧显示的双链链接与右侧显示的文本内容对不上,如下图,但我已经没有办法去修改了,想求助一下这个要怎么改才能对应上呢?
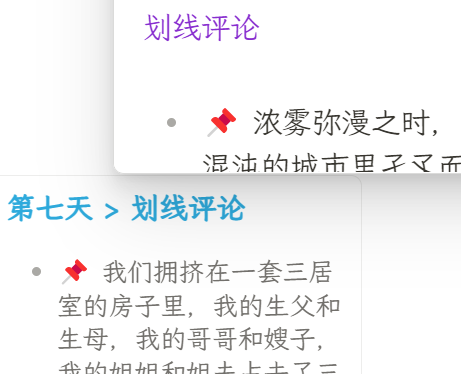
备注:
成果3的两条代码生成的内容格式比较丑,会有文本溢出现象,如果使用的是minimal 主题的话,可以通过在文件开头加上
cssClasses: cards
来将结果渲染为卡片形式,这样文本就不会溢出了。
博主,能否实现随机摘取整个库中2个![]()
![]() 之间的语句,显示出来
之间的语句,显示出来
你这两个心之间的文段是就在一个段落里呢?还是其中包含有空行、标题之类的东西?
如果是前者的话,你可以用成果一的代码,把![]() 替换成心应该可以,虽然显示的文字大概是整个段落的内容;如果是后者的话,可能比较困难,我暂时没有头绪,看还有没有大佬能解决吧。
替换成心应该可以,虽然显示的文字大概是整个段落的内容;如果是后者的话,可能比较困难,我暂时没有头绪,看还有没有大佬能解决吧。
没太搞懂随机显示三条读书笔记有啥意义?随机显示了,真的会去仔细看?
会啊,我每次点进obsidian都是准备做笔记或者写日记了,顺便花点时间看看以前的笔记又不费多少时间,总比藏在文件夹里吃灰强。flomo不也可以导入读书笔记再每日回顾吗,跟这个功能差不多,还是会员独享呢。
一个段落里面,2个![]() 之间
之间
博主~ 我也用了这个摘抄!但完全没有代码基础,可以问下我只想简单显示三天,但想显示来源于哪个文件,可以怎么改一下代码吗?就比如这段摘抄来自于哪天(日记里)或者哪本书(以书名为标题的文件)
如果有时间看一下万分感谢!

好的好的~ 感谢回复,我研究一下!