想法
近期本人在尝试用obsidian实现时间管理,最主要的就是想在日记、周复盘、月复盘等笔记中统计显示各任务的阶段时间花销,并按照工作、学习、阅读等进行分类显示。
自己的尝试
近期自己在网络上找到了Dataviewjs的两个代码片段,分别实现了两个功能:
- 第一个功能是查询当前页面中的任务,并计算任务时间花销,然后以表格的形式展示。我自己进行了部分修改以符合我的任务记录习惯(个人不太喜欢- 的task任务格式记录)。我的任务记录格式是以无序列表的形式记录的,同时记录了任务的开始时间和结束时间,并按照项目和领域进行分类,如下:
- (start::15:55)-(end::15:57) (description::撰写报告) (project::#工作) (area::[[项目建设]])
- (start::16:00)-(end::17:15) (description::阅读书籍) (project::#学习) (area::[[阅读]])
第一段代码实现了上述任务时间统计的功能,代码和效果如下:
const tasks = dv.current().file.lists.map(task => {
const start = new Date(`1970-01-01T${task.start}`);
const end = new Date(`1970-01-01T${task.end}`);
const duration = (end - start) / (1000 * 60 * 60); // 转换为小时
return {
description: task.description,
duration: duration.toFixed(2), // 保留两位小数
start: task.start,
end: task.end,
project: task.project,
area: task.area
};
});
dv.table(
["Description", "Duration (hours)", "Start", "End", "Project", "Area"],
tasks.map(task => [
task.description,
task.duration,
task.start,
task.end,
task.project,
task.area
])
);
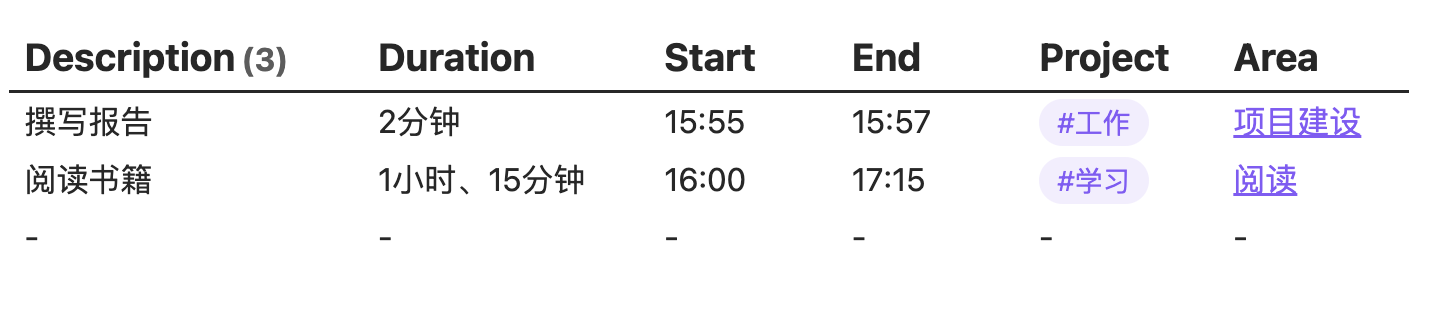
但是这里存在一个问题,就是它会查询当前页面中所有的无序列表,不论是否为我记录的任务,都一股脑的显示到了表格中,就像上图表格中的最后一行中一样,显示的全部都是短横杠,因为这压根不是一个任务,只是我在当前页面中随便输入的一段文字。
所以我就想能否将我的任务记录在特定标题之下,比如## 时间日志,然后用Dataviewjs实现查询该特定标题下的任务,再去计算并统计任务时间,于是我找到了第二个代码片段。
- 第二个代码实现查询库中所有文件中,特定标题下的内容。代码如下:
//输入目标小标题(含#),例如:#### 项目进度条
const header = '#### 项目进度条'
// 按【路径或文件夹、文件名、标签】筛选并按修改时间降序排列
const pages = dv.pages('"00数据管理" or ""').filter(p => p.file.name.includes("") && !p.file.path.includes("template")).filter(p => p.file.name.includes("") || p.file.name.includes("")).sort(p=>p.file.mtime,"desc");
// This regex will return text from the Summary header, until it reaches
// the next header, a horizontal line, or the end of the file
const regex = new RegExp(`\n${header}\r?\n(.*?)(\n#+ |\n---|$)`, 's')
for (const page of pages) {
const file = app.vault.getAbstractFileByPath(page.file.path)
// Read the file contents
const contents = await app.vault.read(file)
// Extract the summary via regex
const summary = contents.match(regex)
//显示全部包括空结果if (summary) {
//不显示空结果if (summary && summary[1].trim()) {
if (summary && summary[1].trim()) {
// Output the header and summary
dv.header(2, page.file.link)
//或者dv.header(2, '[[' + file.basename + ']]')
dv.paragraph(summary[1].trim())
}
}
上述代码来源于论坛的这个话题:【已解决】如何使用 dataview 插件过滤出某个二级标题下的内容 - #8,来自 autumn_1992
代码虽然实现了查询特定标题在的内容,但如何将上述两个功能结合在一起,我就搞不来了,求助于AI,回答的代码尝试后通常都是报错。
上述两个功能有办法合并吗?或者是可以通过其他方式来实现?
在此向论坛内的各位大佬求助,感谢。