大神,如果我想要dataviewjs,在一个不确定文件夹下面,获取出所有的未完成任务列表(不包含有些是空的任务),获取出的列表要有链接,请问可以实现么?
啥叫不确定文件夹,都不确定是哪个文件夹怎么获取
我会定义一个文件夹,const一下,主要是获取不包含空值,并且列表要有链接,这里一直搞不定
确定是列表吗,dvjs获取的任务自带链接,但是单纯的列表没有,需要一点花活
我自己获取出来的任务,都带上了note的名字,我就只需要单纯把所有任务,直接排列就好了,不需要note的名字
const folder = ''
let files = dv.pages(`"${folder}"`)
dv.taskList(files.file.tasks.filter(p=>!p.completed && p.text!=''))
1 个赞
我尝试了一下一个简单的方法,不需额外的代码实现。只需要把dataview的代码换成:
("[](<"+file.name+">)") as "封面"
ob自动把[](文件名)识别成内链,且()内容不显示,dataview刚好可以给到file.name参数。
1 个赞
大佬太强了,学到好多)
我有一个需求是汇总所有日记(全部放在"02-Daily Notes"文件夹内)中指定二级标题下的所有三级标题。比如对于某日记date.md如下:
## [[Project 1]]
### job 1
...
### job 2
...
## [[Project 2]]
### work 1
...
### work 2
...
我希望当我给定Project 1,能够仅提取job 1和job 2(不包括其他正文和次级标题内容),最后能汇总到类似下面格式的表格中:
文件名 job
date.md - job 1
- job2
date2.md -job
...
看了很多帖子感觉dataviewjs是可以实现的,但大概是自己前端实在太菜,别人的代码拿来一改就不行了TUT,折腾了好多天都没什么结果,还望大佬赐教)
dataviewjs确实可以实现,要放在以前,我肯定会用正则硬去匹配标题,但是现在我发现ob其实可以直接获取文件对应的标题 ![]()
let files = dv.pages(`"02-Daily Notes"`)
let targetHeader = '[[Project 1]]'
let headers = files.map(p => {
let tf = app.vault.getAbstractFileByPath(p.file.path)
let header = app.metadataCache.getFileCache(tf)
.headings
if (!header) return
let h = []
let b = false
for (let i of header) {
if (b && i.level == 3) h.push(i.heading)
if (b && i.level == 2) b = false
if (i.heading == targetHeader && i.level == 2) b = true
}
return h.length == 0 ? false : [p.file.link, h]
})
.filter(p => p)
dv.table(['file', 'headers'], headers)
1 个赞
啊确实,我就是一直在改正则,出各种问题……原来可以提取出来,多谢大佬!
再打扰一下,如果类似上面的需求,想要从某个指定二级标题下提取内容,但是提取的是其他类型,比如todo task,是不是就只能使用正则了呢
不用啊,dv.pages(“02-Daily Notes”)取的文件数据里就有tasks,lists之类的数据
谢谢大佬,我是想能否把特定标题下取出的task放进table里并保留task格式,dv.table产生的效果似乎只能是bullet格式
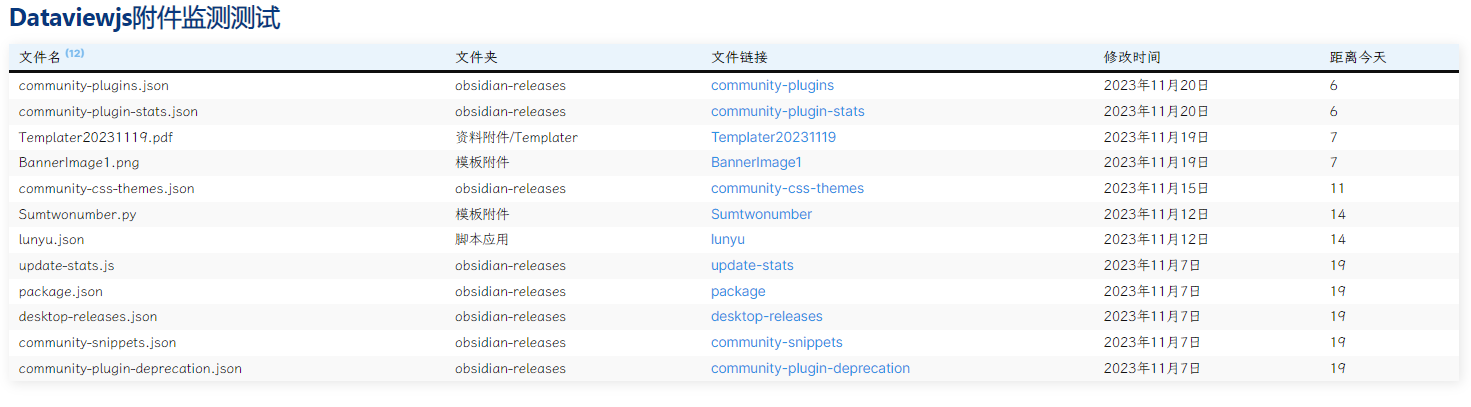
我在用dataviewjs做一个简单的附件变化监视,现在使用的脚本列在下面:
const afiles = await app.vault.getFiles();
const files = dv.array(afiles);
dv.table(["文件名","文件夹","文件链接","修改时间"], files.filter(p=> p.extension != 'md').sort(p=>moment(p.stat.mtime),'desc').map(p=>[p.name,p.parent.name,dv.fileLink(p.path,false,p.basename),moment(p.stat.mtime).format("LL")]))
有几个问题请假一下:
-
在dataviewjs中使用
app.vault.getFiles获取所有文件后,如何把文件的完整目录提取出来,因为file.parent只能是接近文件的目录,比如a/b/c.md,用file.parent只能得到b,不能得到a/b -
如果用dataviewjs中使用
app.vault.getAllLoadedFiles获取所有文件(含目录),如何重写以上代码,因为我发现file.stat.mtime等都不能用了。
如果你已经获取出了dv下的tasks数据(而不是用正则套出来的文本),可以参照一下这份代码
```dataviewjs
let files = dv.pages(`"600-日常/日记"`).filter(p=>p.file.tasks.length!=0)
dv.table(['file','tasks'],files.map(p=>{
let div = dv.container.createEl('div');
dv.api.taskList(p.file.tasks, 0, div, this.component, this.currentFilePath);
return [p.file.link,div];
}))
重点是下面的map部分
1 个赞
1、file.parent.path 得到 "a/b",file.parent.name 得到 "b"
2、用 dv.page(f.path)(f 是 getAllLoadedFiles 得到列表的元素) 就可以了,不过 dv 只有 md 文件的数据,不是 md 文件的话只会返回 undefined。
1 个赞
好像看错了,幻视成是 file.file.mtime 了,还以为要获取 dv 的对应索引数据呢,file.stat.mtime 为什么不能用了呢,我看文件夹也是有这个属性的啊
感谢!
-
用file.parent.path解决了
a/b的问题; -
因为我要检索的是附件(非md文件),用dv.page(file.path)肯定不行啊
我看成 file.file.mtime 还以为你不知道呢 ![]() ,如果只检索附件为啥要用 getAllLoadedFiles,用 app.vault.getFiles().filter(p=> p.extension != ‘md’) 不就够了吗
,如果只检索附件为啥要用 getAllLoadedFiles,用 app.vault.getFiles().filter(p=> p.extension != ‘md’) 不就够了吗