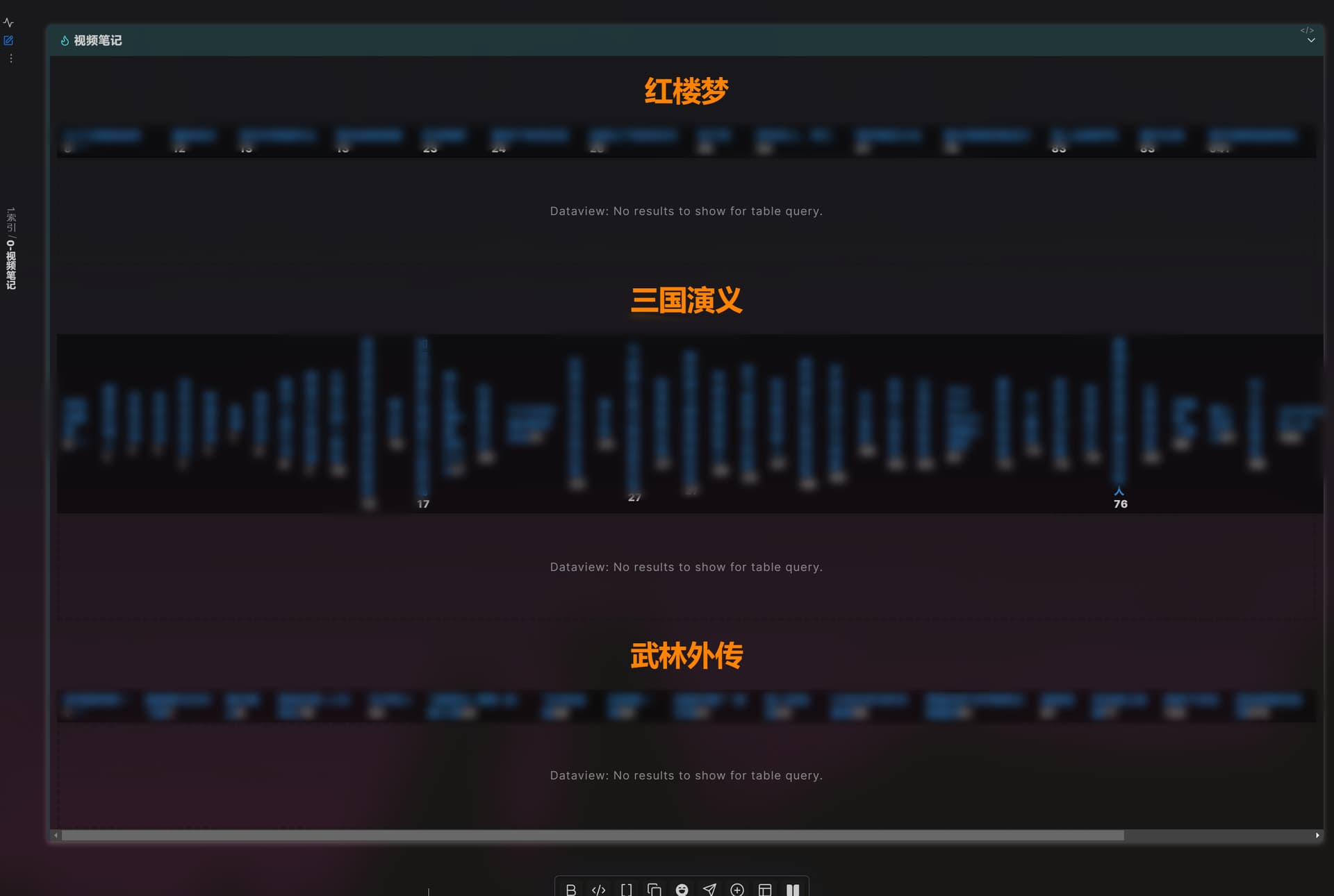
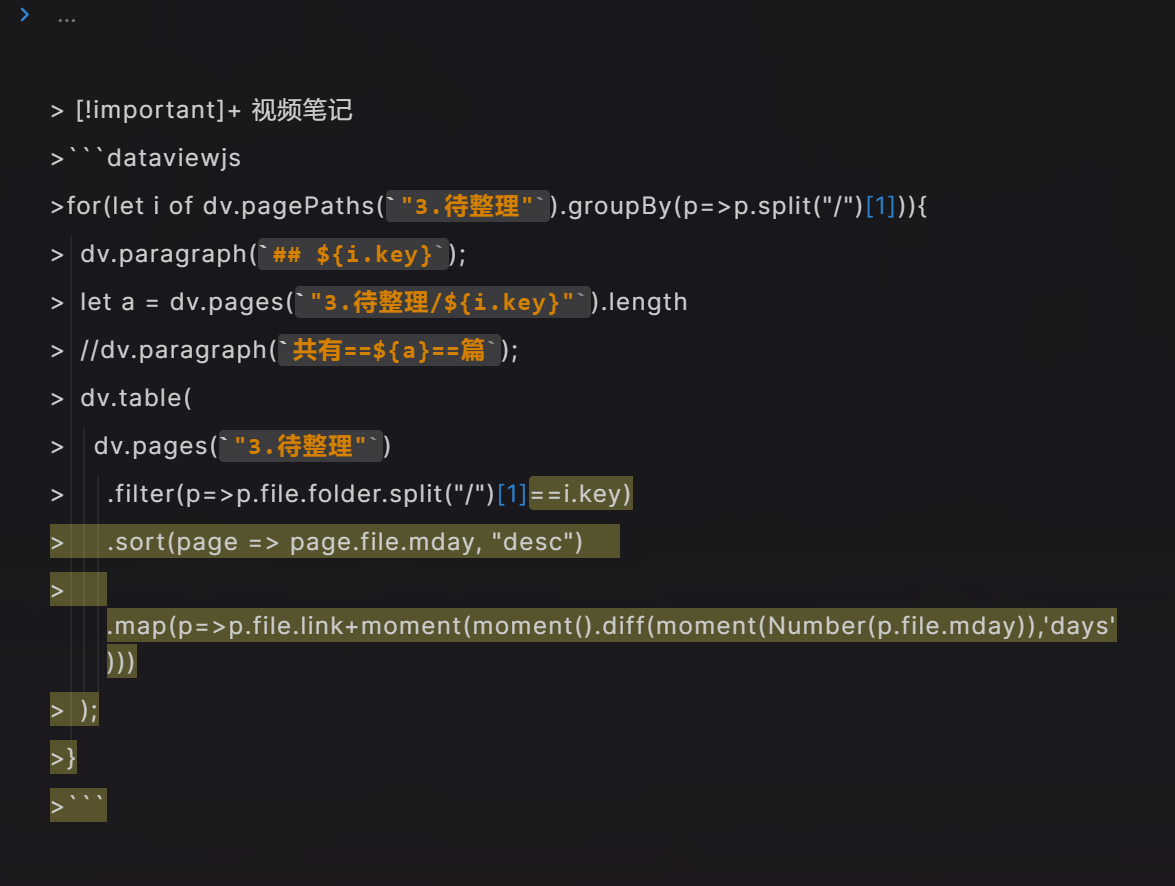
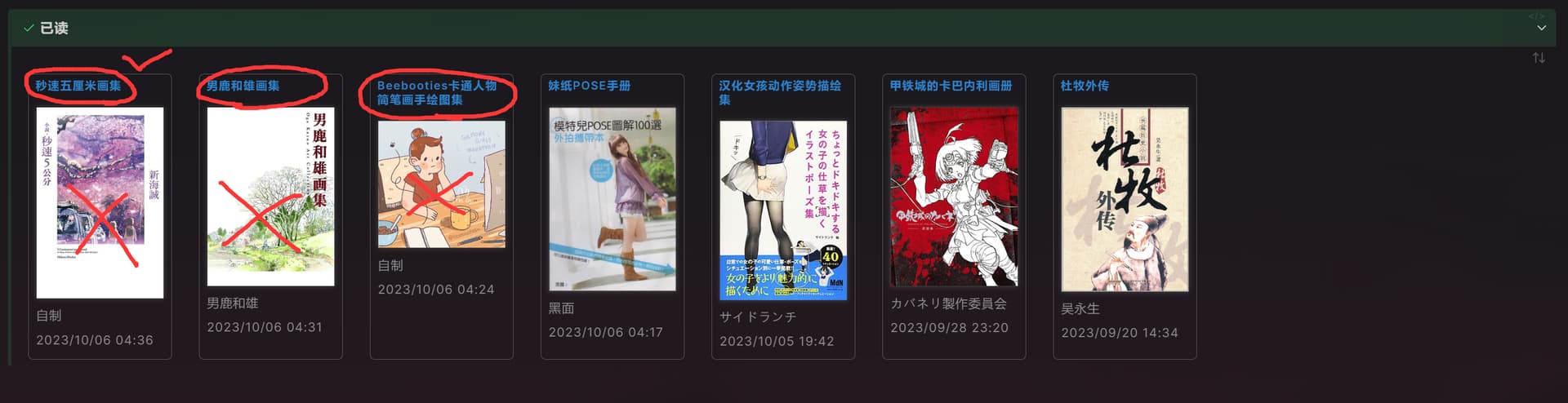
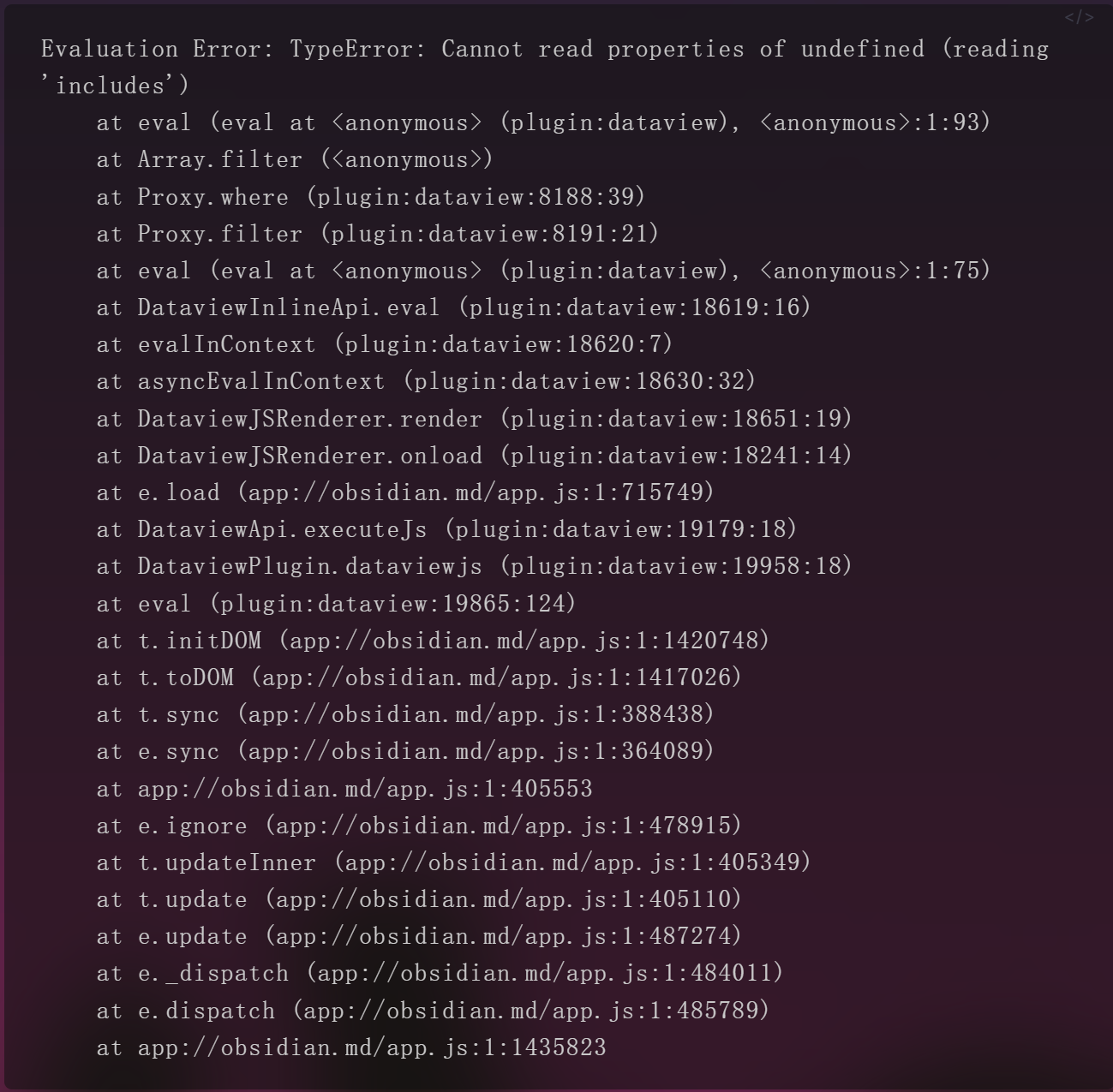
for(let i of dv.pagePaths(`"3.待整理"`).groupBy(p=>p.split("/")[1])){
dv.paragraph(`## ${i.key}`);
let a=dv.pages(`"3.待整理/${i.key}"`).length
dv.paragraph(`共有==${a}==篇`);
let div = dv.container.createEl('div')
dv.api.table(
dv.pages(`"3.待整理"`)
.filter(p=>p.file.folder.split("/")[1]==i.key)
.sort(page =>page.file.mday,"desc")
.map(p=>p.file.link+''),[],
div,
dv.component,
dv.currentFilePath
)
a = div.querySelectorAll('.table-view-th')
a.forEach(p=>p.style.writingMode = "vertical-rl")
a = div.querySelector('.dataview.dataview-error-box')
a.style.display='none'
}
let y = 2023
let m = Array(12).fill(0).map((v,i)=>{return i});
let d = [31,29,31,30,31,30,31,31,30,31,30,31]
for(let i of m)
{
let n = Array(d[i]).fill(0).map((v,i)=>i+1);
let a = Array(d[i]).fill(0);
for(let j of dv.pages(`""`)
.filter(p=>moment(Number(p.file.cday)).year()==y
&& moment(Number(p.file.cday)).month()==i)
.groupBy(p=>moment(Number(p.file.cday)).date()))
a[j.key-1] = j.rows.length;
if(a.every(p=>p==0))
continue
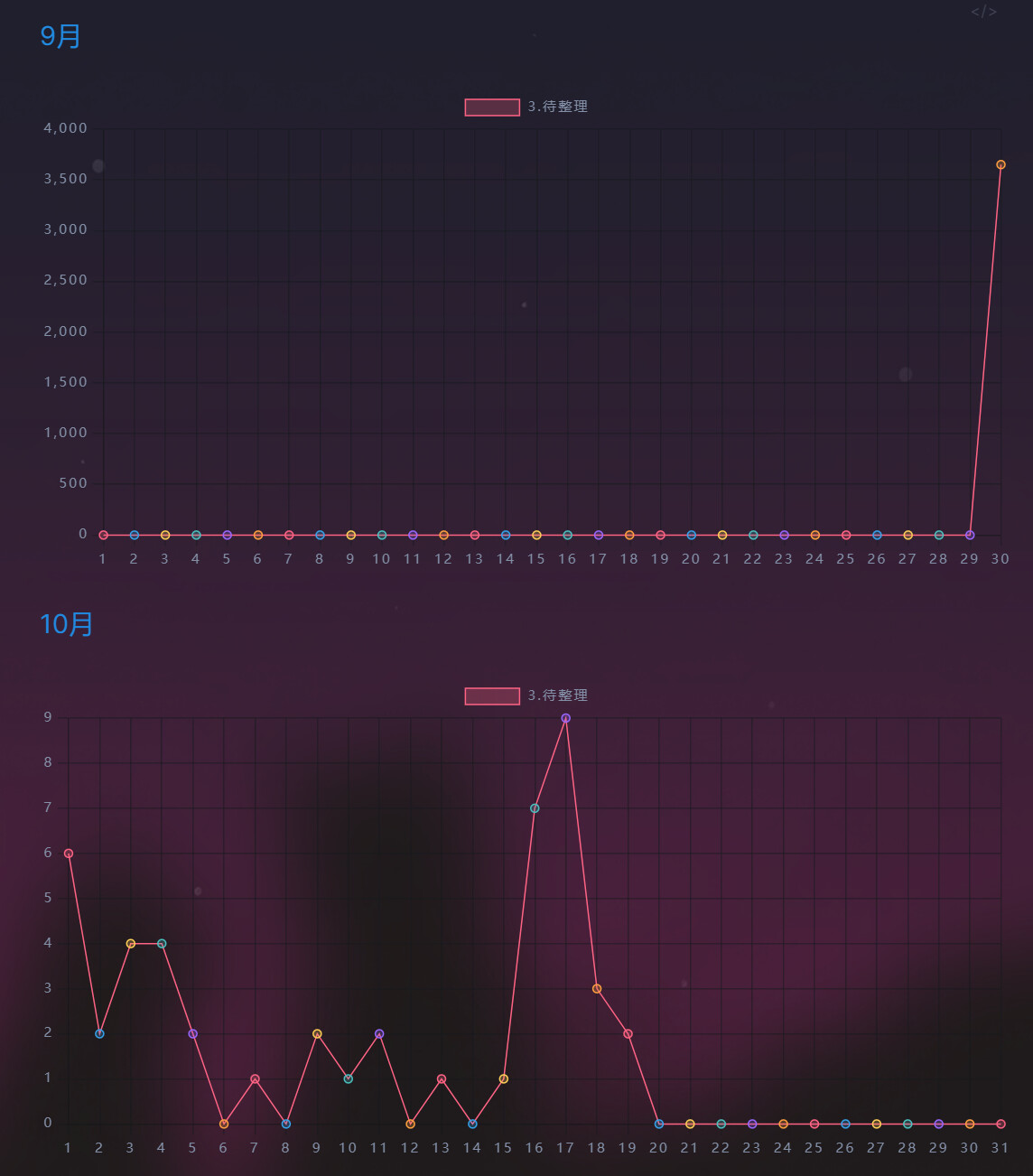
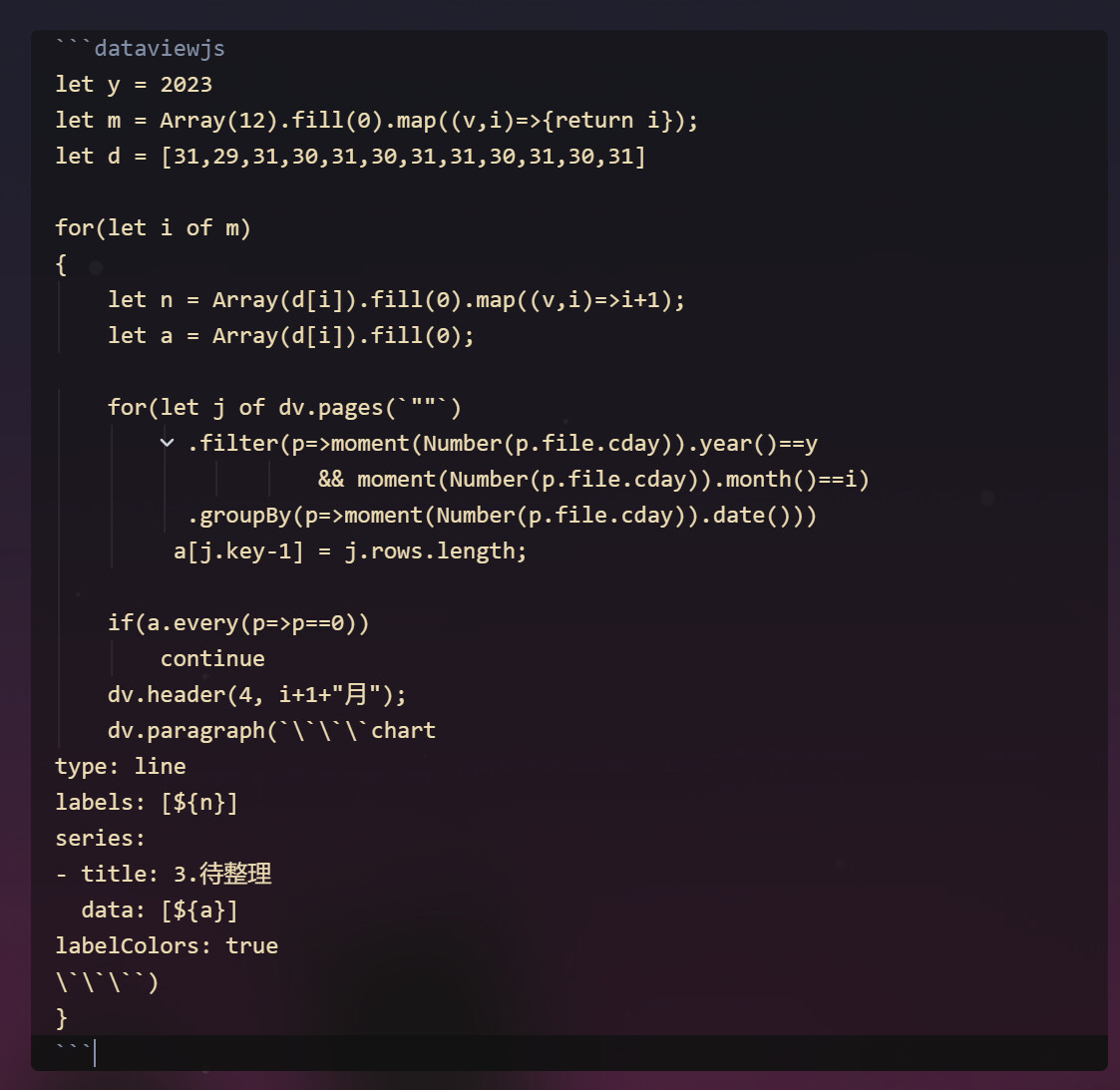
dv.header(4, i+1+"月");
dv.paragraph(`\`\`\`chart
type: line
labels: [${n}]
series:
- title: 3.待整理
data: [${a}]
labelColors: true
\`\`\``)
}
let y = 2023
let m = 10
let d = moment(`${y}-${m}`).daysInMonth()
let n = Array(d).fill(0).map((v,i)=>i+1);
let a = Array(d).fill(0);
for(let j of dv.pages(`""`)
.filter(p=>p.file.cday.year==y
&& p.file.cday.month==m)
.groupBy(p=>p.file.cday.day))
a[j.key-1] = j.rows.length;
if(!a.every(p=>p==0)){
dv.header(4, m+"月");
dv.paragraph(`\`\`\`chart
type: line
labels: [${n}]
series:
- title: 3.待整理
data: [${a}]
labelColors: true
\`\`\``)}