因为dataview相关函数返回的不是原生数组,而是它自己的数组类
```dataviewjs
// 定义一个函数来计算两个字符串的Dice的系数,和之前的一样
function diceCoefficient(str1, str2) {
// 如果两个字符串完全相同,返回1
if (str1 === str2) return 1;
// 如果两个字符串长度小于2,返回0
if (str1.length < 2 || str2.length < 2) return 0;
// 将字符串转换为小写
str1 = str1.toLowerCase();
str2 = str2.toLowerCase();
// 定义一个集合来存储两个字符串的双字母组合
let pairs1 = new Set();
let pairs2 = new Set();
// 遍历两个字符串,将双字母组合加入集合
for (let i = 0; i < str1.length - 1; i++) {
pairs1.add(str1.slice(i, i + 2));
}
for (let i = 0; i < str2.length - 1; i++) {
pairs2.add(str2.slice(i, i + 2));
}
// 定义一个变量来存储两个集合的交集的大小
let intersection = 0;
// 遍历一个集合,判断另一个集合是否包含相同的元素,如果是,交集大小加一
for (let pair of pairs1) {
if (pairs2.has(pair)) intersection++;
}
// 返回Dice的系数,即交集大小除以集合大小之和的一半
return (2 * intersection) / (pairs1.size + pairs2.size);
}
// 在dataviewjs代码块中调用这个函数,比较所有笔记名称和当前笔记名称的相似度,如果大于0.45,就呈现一个表格,表格的每一行是一个笔记的名称和相似度,然后按照相似度降序排列
dv.table(
["与当前文件名相似的笔记", "相似度"],
dv.pages()
.where((p) => p.file.name !== dv.current().file.name && diceCoefficient(p.file.name, dv.current().file.name) > 0.45) // 排除当前笔记的名称
.map((p) => [
p.file.link,
diceCoefficient(p.file.name, dv.current().file.name).toFixed(2),
])
.sort((a) => - parseFloat(a[1])) // 将字符串转换为数字,然后按照相似度降序排列
.limit(15) // 限制结果数量为15条
);
```
@lazyloong 大佬,再请教一个问题, dataview可以获取访问次数最少或最多的前50条笔记吗?找了一下,没看到相关参数
那应该不行,至少我没有见过什么地方记录了访问次数,没有数据自然不能获取,除非你自己在yaml区记录次数,并且做好维护
lz太强了,爬完了所有楼,非常值得学习,但是最近有个需求常常困惑我,就是dataviewjs进行查询后,返回的结果中不会进行渲染图片,或者不会渲染从其他文件中,基于block引用的内容,如![[File#^78gula]]——不会显示这个引用的内容,只会显示名字“File#^78gula”请问lz在使用过程中有遇到这种问题吗?
翻阅了github上等等内容,没有找到解决方案,但是总觉得应该是可以的,如像dv.paragraph(await dv.io.load(“File.md”))是可以实现渲染整个页面的。想请教lz关于这个有没有什么解决方案?
以前有过这样的情况,但是刚才测试的时候发现正常了,我这能正常显示了,比如这样
dv.paragraph(`![[离散随机变量-概率分布#^n70lba]]`)
十分感谢大佬答复,提供了一个好的方法,简单试了下好像有效,接下来我打算试试一下基于此的复杂一点的功能和显示,祝心情愉快 
大大,但是我在尝试的过程中,发现我无法将其和dv.table功能相结合(太菜了)
简单描述一下应用场景:
背景是
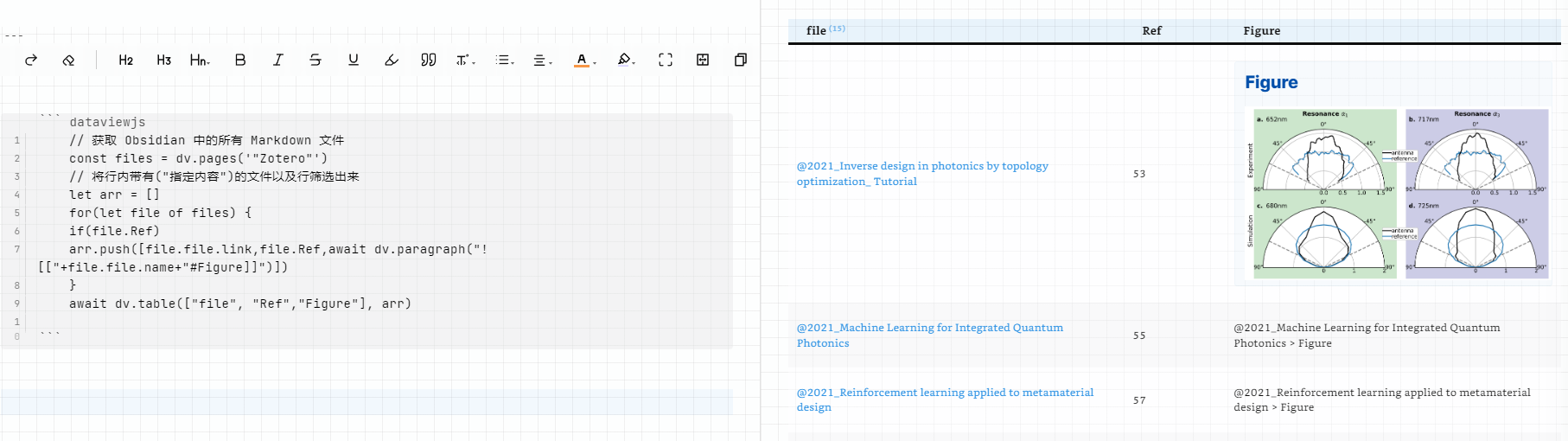
1.在阅读文献过程中,针对每一篇文献做了单独的markdown文件
2.每个markdown下,有个子标题##Figure,存放了关于当篇文献的图片
需求是:
1.对文献进行查找/按照Table排列,如下,希望能够列出 名字;序号;图片
以下dataviewjs代码在学习他人代码后根据自己需求修改的,但问题仍是出现在无法渲染出引用的内容这一部分
// 获取 Obsidian 中的所有 Markdown 文件
const files = app.vault.getMarkdownFiles()
// 将行内带有("指定内容")的文件以及行筛选出来
let arr = files.map(async(file) => {
const content = await app.vault.cachedRead(file)
// 过滤包含"Ref"的文件
let Ref = await content.split("\n").filter(line => line.includes("Ref::"))
return ["[["+file.name.split(".")[0]+"]]",Ref,"![["+file.name.split(".")[0]+"#Figure]]"]
})
Promise.all(arr).then(values => {
const exists = values.filter(value => value[1][0])
dv.table(["file", "Ref","Figure"], exists)
})
dv.paragraph(`![[某篇文献#图片]]`)
这句话,单独使用时是可以渲染出具体内容的,但是这个我无法和dv.table相结合;dv.table后的结果,仍然是![[某篇文献#图片]]的“名字”,而非其“内容”
以上是希望筛选,并且显示##Figure子标题下内容的想法和困难之处
此外,另一个想实现的需求是:有些行或者block,加了关键词,并且引用了其他文件中的部分内容
形式如:
#key aaaa ![[离散随机变量-概率分布#^n70lba]] bbb
希望能够按照行内关键词进行搜索,然后同样以dv.table的形式,显示出这句话
但是遇到的同样问题是和图片一样,得到的结果是 #key aaaa 离散随机变量-概率分布#^n70lba bbb
而非#key aaaa "引用的内容“” bbb
如下图,查找到的这句话中的![[xxxx#^yyyy]]部分就无法显示其内容
```dataviewjs
// 获取 Obsidian 中的所有 Markdown 文件
const files = dv.pages()
// 将行内带有("指定内容")的文件以及行筛选出来
let arr = []
for(let file of files) {
if(file.Ref)
arr.push([file.file.link,file.Ref,await dv.paragraph("![["+file.file.name+"#Figure]]")])
}
await dv.table(["file", "Ref","Figure"], arr)
```
1 个赞
感谢答复,但是出现的一个问题是,似乎只渲染了第一个,其余的仍然没有出现希望的效果…
虽然不知道原理,但经过尝试了一下,
arr.push([file.file.link,file.Ref,await dv.paragraph("![["+file.file.name+"#Figure]]")])
需要将其中的await删除
arr.push([file.file.link,file.Ref,dv.paragraph("![["+file.file.name+"#Figure]]")])
这样就不会出现只渲染第一个的问题
十分感谢大佬的解答!解决了困扰好多天的问题。
仍想打扰请问,能否将这个功能和上述的关键词查找相结合?
如:一句话为:
#test 测试测试测试 ![[其他文件#^n70lba]]
能否实现将多篇md文件中,含有#test的行或者block,进行统一查找且渲染出(如果有引用了其他文章的部分)呢?
请问大佬,这段代码把文本中代码块里出现‘### “的地方的文本也给提取出来了,有办法屏蔽代码块内部的文本不参与提取吗?
```dataviewjs
let files = dv.pages(`"300-系列笔记/310-课程/信号与系统"`)
for(let f of files) {
let content = await app.vault.readRaw(f.file.path)
var regex = /(```[\s\S]*?```)/g;
content = content.replace(regex, " ");
content = content.split('\n')
let headers = content.filter(p=>/#+ (.*?)/.test(p))
dv.paragraph('### '+f.file.link)
dv.paragraph('url:'+f.url)
dv.paragraph(headers.map(p=>p.replace(/#+/g,' '.repeat(p.match(/#+/g)[0].length*2)+'-')+'\n').reduce((a,b)=>a+b,''))
}
```
提取是可以的,但是嵌入块没办法渲染,这好像是ob底层的问题
感谢大大,不知道你是否知晓有一个Obsidian Query Control的插件,它可以将query查找到的内容,以markdown的方式进行渲染出(即能够渲染出嵌入块)。
但是个人的本身需求中,由于需要放入一些其他信息(内联区)/或者使用dv.table进行一下排版等原因,Obsidian Query Control还是不能完美满足。
但由于它实现了渲染嵌入块,让我感觉dataviewjs可能也能够实现——即渲染块+dvjs的自定义筛选排版。
但目前是
Obsidian Query Control实现了(1)渲染块
dvjs实现了(2)自定义筛选排版
两个需求没有在一种方式中结合起来,略有可惜。
既然大大这样说,我感觉凭我的能力短时间无法实现了,打算先放一放这样的需求了  。
。
谢谢大佬,已满足需求。这个帖子太好了,承担了初学者所有的入门疑惑 
Liho
(Liho)
249
您好,我希望得到一点帮助
我想要获取文件的反向链接所在行的内容,如反向链接面板中一样,“让我们参考[[白切鸡]]的做法“ 而不是 “[[白切鸡]]”,并且希望作为dv.table表格的一个字段,目前的思路是获取文件的所有反向链接,再获取这些文件的内容找到链接所在行再返回,但我js接触太浅,参考了一些加载文件内容的dvjs代码但是未能正确实现所要功能,不知道如何实现或者有其他的思路方法,我最终目的是希望通过dvjs获得1个dv表格(包含文件名、反链、反链所在行、标签)