我库里的笔记一万多条,这段代码貌似渲染比较费时,三分钟往上了,而且导出来仍是空白。 ![]()
你没对第一行做筛选吗
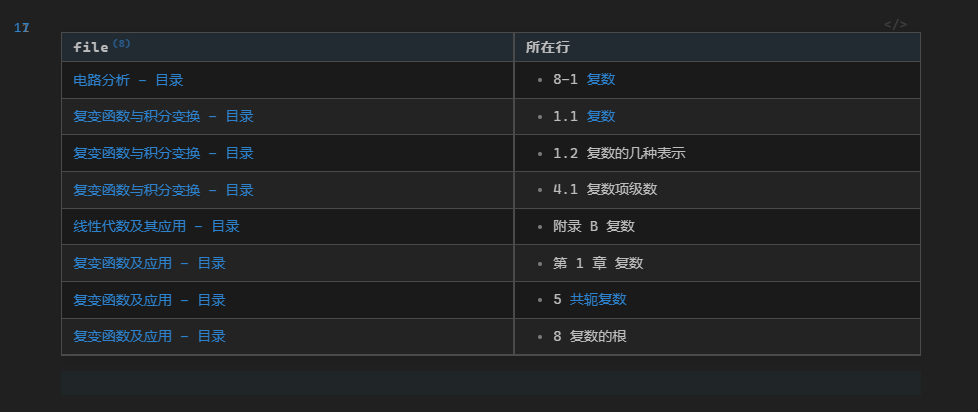
不然试试这个吧
```dataviewjs
let files = dv.pages('#目录')
extractKeywords(['复数'],files)
async function extractKeywords(keywordArr,files) {
let paths = files.map(p=>p.file.path)
files = app.vault.getMarkdownFiles().filter(p=>paths.includes(p.path))
let values = []
for(let file of files) {
let content = (await app.vault.cachedRead(file)).split('\n')
keywordArr.forEach((k)=>{
content.filter(p=>p.includes(k))
?.forEach(p=>values.push([`[[${file.name}]]`,p.trim()]))
})
}
dv.table(["file", "所在行"], values)
}
```

我的使用就是针对整个库进行提取,试了这个新版本的,ob直接崩了(上个版本的ob不会崩,只是渲染费时,至少需要三分钟)
我目前在用的自用版本,渲染较快,基本3秒就能出结果。但渲染就是无法导出来 ![]()
那就奇怪了,我也有2500的文件,全库也不过两三秒就渲染了,那只好请求场外援助了
```dataviewjs
let keyword = '复数'
let results = await omnisearch.search(keyword)
let vaules = []
for(let r of results) {
for(let m of r.matches) {
let i = m.match.indexOf(keyword)
if(i!=-1) {
let content = await app.vault.readRaw(r.path)
let line = getLineNumber(content, i+m.offset)
vaules.push([`[[${r.path}|${r.basename}]]`, line])
}
}
}
dv.table(['file','line'],vaules)
function getLineNumber(str, pos) {
var lines = str.split("\n")
var count = 0
for (var i = 0; i < lines.length; i++) {
count += lines[i].length + 1 // add 1 for the newline character
if (count > pos) {
return lines[i] // line numbers start from 1
}
}
}
```
可能有些重复的,对了,要安装 Omnisearch 插件
谢谢耐心解答。不过Omnisearch 插件我之前前前后后试用过多次,ob直接卡到崩溃。我的库是一万多条笔记,跟几千条笔记相比,可能是数量过多了,量变已经引起质变
另外您分享的第2个版本,我指定目录后测试,能正常渲染,但结果导出还是空白,捂脸
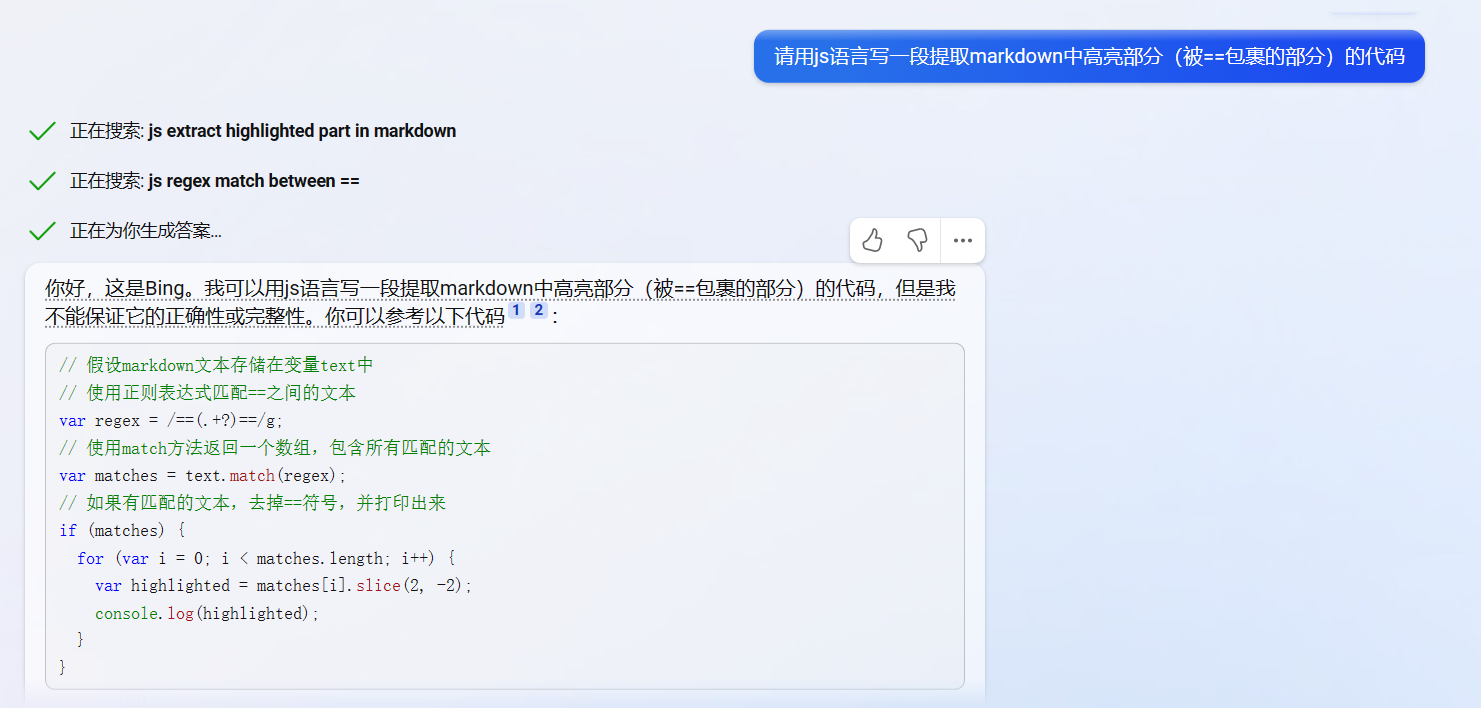
你说的导出结果是什么意思,导出pdf吗
是的,用ob自带的导出功能导出PDF,或者用webpage-html-export插件,导出html格式
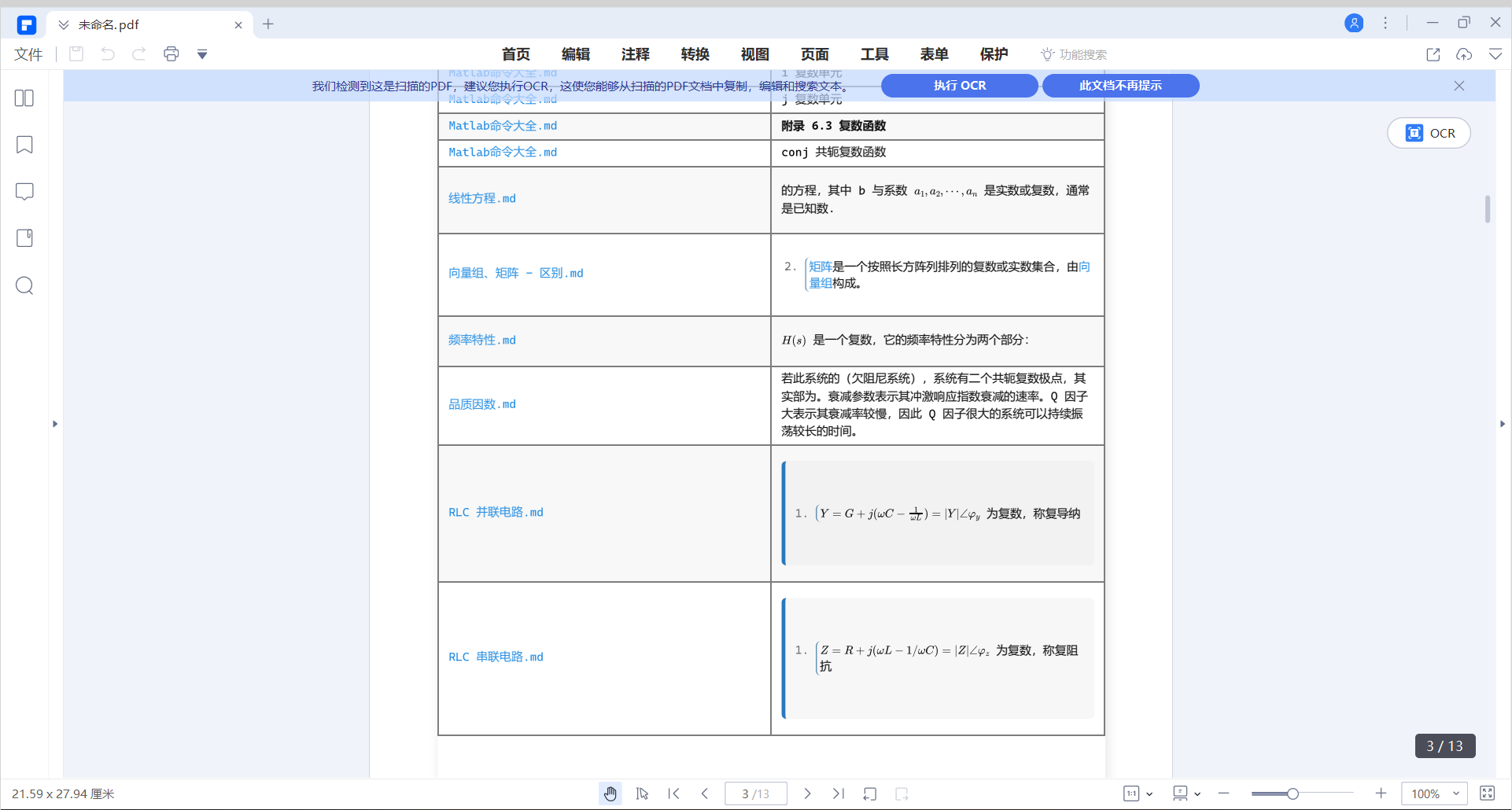
经测试,跟库的笔记数量有关。
换到小库时,我自用的代码、您提供的第2版,都能正常导出pdf、html
捂脸
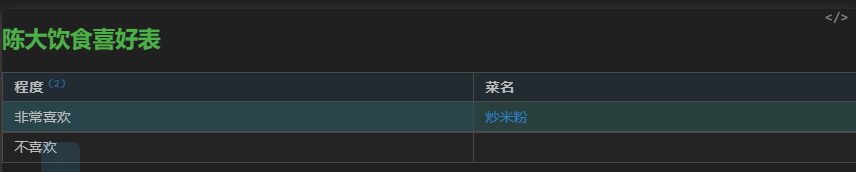
let files = dv.pages().filter(p=>p.菜名) console.log(files) let d=[] for(let p of files) { p.file.link.display=p.菜名 d.push({link:p.file.link,name:p.菜名,非常喜欢:p?.非常喜欢,不喜欢:p?.不喜欢}) } let target = '陈大' dv.header(2,target+'饮食喜好表') dv.table( ['程度','菜名'], [['非常喜欢',d.map(p=>{if(p.非常喜欢?.split('、').includes(target)) return p.link}).filter(p=>p).join('、')], ['不喜欢',d.map(p=>{if(p.不喜欢?.split('、').includes(target)) return p.link}).filter(p=>p).join('、')]] )
@lazyloong 大佬,针对上述代码, 下面这个疑问能帮忙解答一下不?
yaml值如下:
非常喜欢: 小明随机内容A、小华随机内容B
不喜欢: 大柱子随机内容C
也就是在名字后面,还有随机内容,请问应该怎样修改代码,才能识别内容并提取汇总呢?
随机内容有可能跟在 菜名 后面吗?
用 - 分割
```dataviewjs
let target = '陈大'
dv.header(2,target+'饮食喜好表')
dv.table(
['程度','菜名'],
fun(target,['非常喜欢','不喜欢'],'菜名')
)
function fun(target,yamls,yaml) {
let files = dv.pages().filter(p=>p[yaml])
let d=[]
for(let p of files) {
p.file.link.display = p[yaml]
d.push({link:p.file.link,
name:p[yaml],
...Object.fromEntries(yamls.map(y=>[y,p[y]?p[y].split('-'):undefined]))})
}
return yamls.map(y=>[y,d.map(p=>{if(p[y]?.[0]?.split('、').includes(target)) return function(link){console.log(link);link.display=`${link.display}(${p[y][1]})`;return link}(p.link)}).filter(p=>p).join('、')])
}
```
也是研究video后辈同行啊,想当年还是mendeley和evernote结合
是我想要的效果,太赞了,谢谢!
@lazyloong 请教一下,dvjs可以获取并列出 具有相同/相似名称的笔记吗?谢谢
当然可以,前提是你能用代码语言精确地定义什么叫相似
不会编程,请问有类似的样例可以参考下么?例如前10个字符相同,就判定为相似
@lazyloong 我手上有一个代码,作用是:获取与当前笔记名相似的笔记。使用正常,但按相似度降序排列,一直不生效,能否请大神 帮忙修正一下?谢谢
// 定义一个函数来计算两个字符串的Dice的系数,和之前的一样
function diceCoefficient(str1, str2) {
// 如果两个字符串完全相同,返回1
if (str1 === str2) return 1;
// 如果两个字符串长度小于2,返回0
if (str1.length < 2 || str2.length < 2) return 0;
// 将字符串转换为小写
str1 = str1.toLowerCase();
str2 = str2.toLowerCase();
// 定义一个集合来存储两个字符串的双字母组合
let pairs1 = new Set();
let pairs2 = new Set();
// 遍历两个字符串,将双字母组合加入集合
for (let i = 0; i < str1.length - 1; i++) {
pairs1.add(str1.slice(i, i + 2));
}
for (let i = 0; i < str2.length - 1; i++) {
pairs2.add(str2.slice(i, i + 2));
}
// 定义一个变量来存储两个集合的交集的大小
let intersection = 0;
// 遍历一个集合,判断另一个集合是否包含相同的元素,如果是,交集大小加一
for (let pair of pairs1) {
if (pairs2.has(pair)) intersection++;
}
// 返回Dice的系数,即交集大小除以集合大小之和的一半
return (2 * intersection) / (pairs1.size + pairs2.size);
}
// 在dataviewjs代码块中调用这个函数,比较所有笔记名称和当前笔记名称的相似度,如果大于0.45,就呈现一个表格,表格的每一行是一个笔记的名称和相似度,然后按照相似度降序排列
dv.table(
["与当前文件名相似的笔记", "相似度"],
dv.pages()
.where((p) => p.file.name !== dv.current().file.name && diceCoefficient(p.file.name, dv.current().file.name) > 0.45) // 排除当前笔记的名称
.map((p) => [
p.file.link,
diceCoefficient(p.file.name, dv.current().file.name).toFixed(2),
])
.sort((a, b) => parseFloat(b[1]) - parseFloat(a[1])) // 将字符串转换为数字,然后按照相似度降序排列
.limit(15) // 限制结果数量为15条
);
1 个赞