王婆卖瓜
如果遇到升级1.2.x后 Obsidian-query-control 如果运行不了了,可以看一下
我写的一个debug说明
修改后的插件
王婆卖瓜
如果遇到升级1.2.x后 Obsidian-query-control 如果运行不了了,可以看一下
我写的一个debug说明
修改后的插件
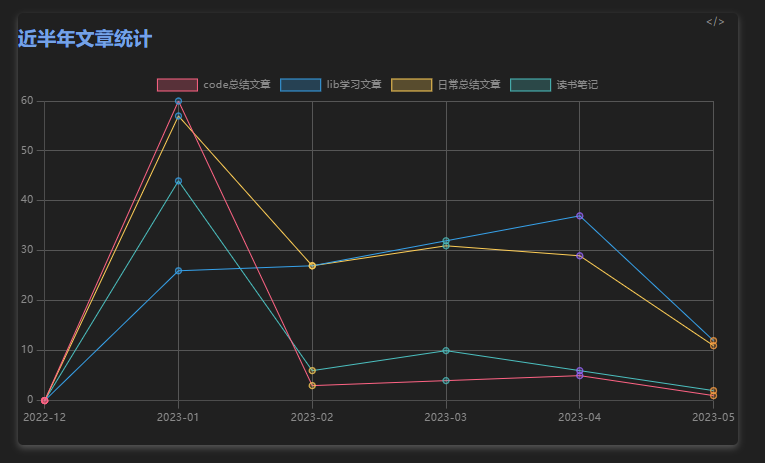
改进了下 ,在一个图表里面展示所有内容
// 得到从当前开始前12个月份的yyyy-mm 数组
var m = Array(6).fill(0)
.map(function(v,i){return i})
.map(p=>new Date(new Date().setMonth(new Date().getMonth()-p))
.toISOString().slice(0,7));
let codes = getCountMaps('code').reverse();
let libs = getCountMaps('lib').reverse();
let dailys = getCountMaps('daily').reverse();
let wereads = getCountMaps('weread').reverse();
dv.header(4, "近半年文章统计");
dv.paragraph(`\`\`\`chart
type: line
labels: [${m.reverse()}]
labelColors: true
series:
- title: code总结文章
data: [${codes}]
- title: lib学习文章
data: [${libs}]
- title: 日常总结文章
data: [${dailys}]
- title: 读书笔记
data: [${wereads}]
\`\`\``)
function getCountMaps(name) {
let codeDataMap = new Map();
// 转成map
const codeMaps = dv.pages(`"${name}"`)
.groupBy(p => String(p.file.cday).slice(0, 7))
init:
for (let i of m) {
for (let ele of codeMaps) {
if(ele.key === i){
codeDataMap.set(i, ele.rows.length);
continue init
}
}
codeDataMap.set(i, 0);
}
// 返回 array 数组
return Array.from(codeDataMap.values());
}
效果图如下
大佬大佬
请教个问题:
我只想提取昨天的日记的某个标题下的内容(日记名是YYYY-MM-DD),但是文件过滤我不会写,来请教一下
块引用
const term = "明日预期"
const files = dv.pages('"02 Diary/Daily"')//这里.where(p => p.file.cday == date(yesterday))好像不行
const b = files.map(async function(p){
var x = await app.vault.readRaw(p.file.path);
x = x.split("\n### ").filter(p=>p.slice(0,term.length)==term)[0]; dv.paragraph(x.slice(term.length)+"\n"); } )
这样应该可以
let file = dv.page(moment().subtract(1,'day').format('YYYY-MM-DD'))
大佬,这个好像会报错唉
但是这个输出信息是对的
块引用
dv.paragraph(dv.page(moment().subtract(1,‘day’).format(‘YYYY-MM-DD’)))
好像是类型 错了, 用dv.page好像就不能用file.map这个函数了?
块引用
Evaluation Error: TypeError: files.map is not a function
dv.page本来返回的也不是数组类型的啊,你不是只要一个文件吗,干嘛要用map函数
是的,谢谢大佬 ![]()
![]()
![]()
大佬大佬,我还有个问题.想做一个图片汇总,我目前打算用标签来做分类,
但是正常的笔记标签和图片就会分开,并不在一行里,检索就没图片了,请问您有啥解决办法或者建议吗?
这个图片汇总是按笔记汇总(用笔记的tag)还是每个图片单独一个tag汇总
每个图片单独一个或几个tag,然后按不同tag汇总
想着每个图片同行放置一个到多个标签,然后检索标签.
那个号今天的回复超上限了 ![]()
![]()
![]()
我尝试用如下代码,结果显示正确但是图片却不显示,大佬您知道是哪里的问题吗?
块引用
const term = “你好”
const files = dv.pages()//.filter(p => p.file.name == moment().subtract(1,‘day’).format(‘YYYY-MM-DD’))
const b = files.map(async function(p){
var x = await app.vault.readRaw(p.file.path);
x = x.split("\n### ").filter(p=>p.slice(0,term.length)==term)[0];
// 使用replace方法,把![]或者![]替换成用反引号包裹的字符串
x = x.replace(/|![[.*?]]/g, function(match) { return\${match}``; });
dv.paragraph(x.slice(term.length));
} )
目前结果就是这样

图片结果无法正常显示
你是说这样吗
```dataviewjs
const term = "日常记录"
const files = dv.page()//.filter(p => p.file.name == moment().subtract(1,‘day’).format(‘YYYY-MM-DD’))
const b = files.map(async function(p){
var x = await app.vault.readRaw(p.file.path);
x = x.split("\n## ").filter(p=>p.slice(0,term.length)==term)[0];
// 使用replace方法,把![[]]或者![[ ]]替换成用反引号包裹的字符串
x = x.replace(/|![[.*?]]/g, function(match) { return match};});
dv.header(3,p.file.link)
dv.paragraph(x.slice(term.length));
})
```
对的,大体就是这个效果,大佬牛批 ![]()
![]()
![]()
![]()
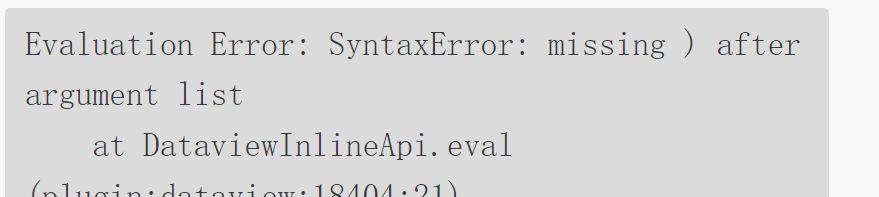
但是有个问题我核对了半天,他始终讲我有问题,代码跑不起来`
块引用
const term = "日常记录"
const files = dv.pages()
const b = files.map(async function(p){
var x = await app.vault.readRaw(p.file.path);
x = x.split("\n## ").filter(p=>p.slice(0,term.length)==term)[0];
x = x.replace(/|![[.*?]]/g, function(match) { return match};});
dv.header(3,p.file.link)
dv.paragraph(x.slice(term.length));
})
他讲你有啥问题啊