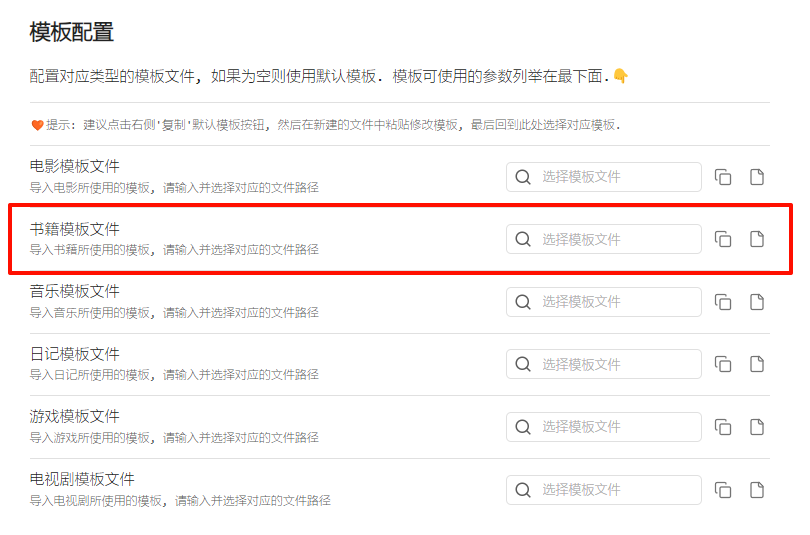
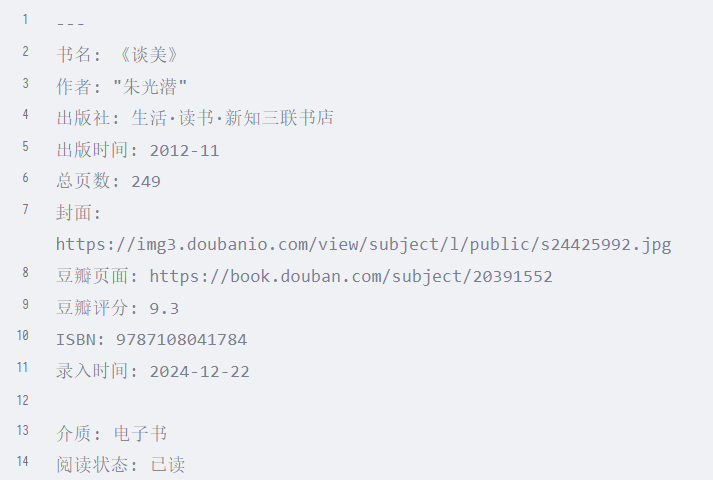
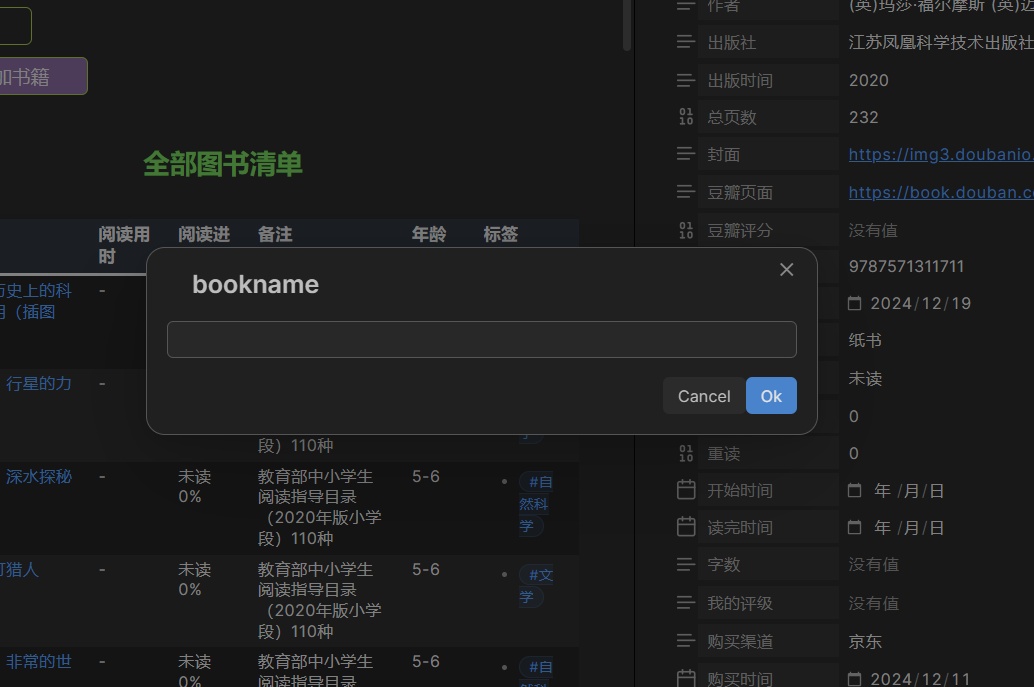
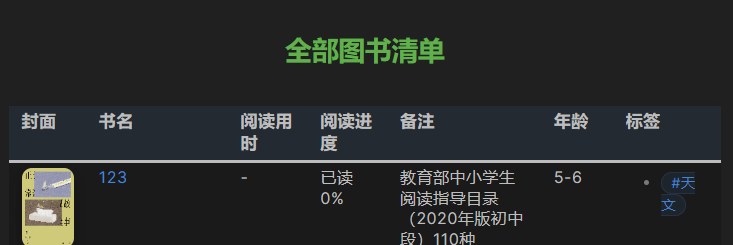
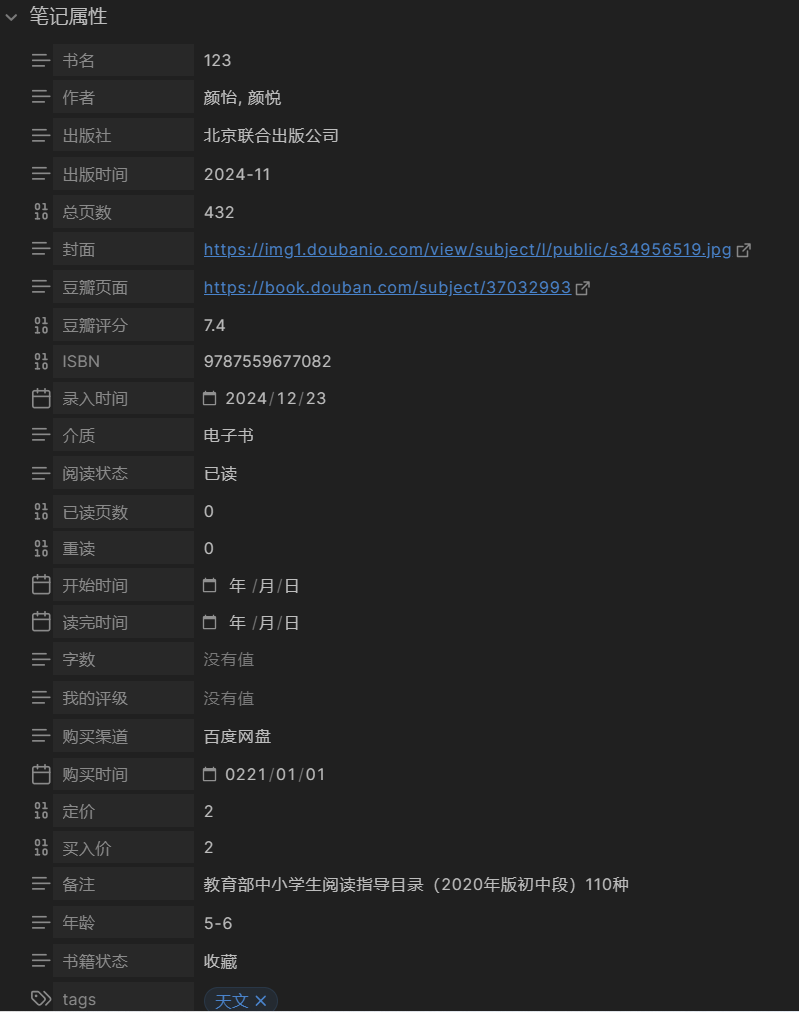
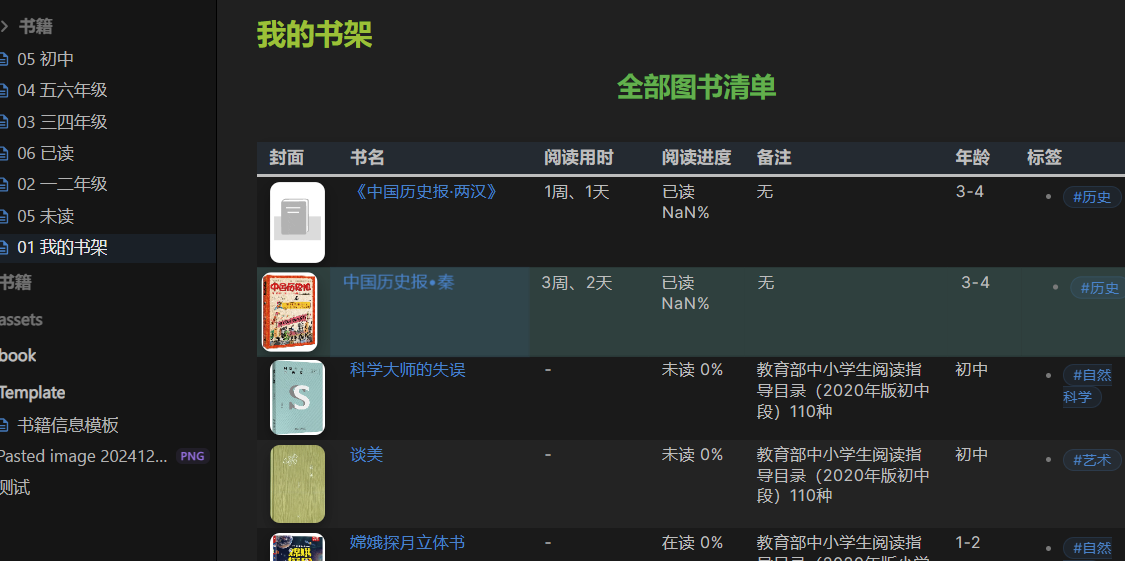
给孩子做了一个图书馆库,专门管理各年级图书,本来都是很顺利很方便的,如图
需要添加新书A的时候通过快捷按钮:从豆瓣添加书籍(实际是调用了bookfromdouban.js)
2024年12月,忽然这个按钮就失效了,我查了下,应该是douban那边调整了,所以无法爬去数据了,OB恰好出了一个豆瓣的插件,我就装上了。
可是,通过douban插件下载到的图书信息和我之前下载的完全不一样,
由于存在偏差,我所有的统计工作就都无法实现,所以跪求大佬,这种情况应该如何处理?
最希望的方式是通过修改js片段实现数据调用,因此附上book from douban.js的代码:
const notice = (msg) => new Notice(msg, 5000);
const log = (msg) => console.log(msg);
module.exports = bookfromdouban;
let QuickAdd;
async function bookfromdouban(params) {
QuickAdd = params;
const isbn_reg = /^(?=(?:\D*\d){10}(?:(?:\D*\d){3})?$)[\d-]+$/g;
const http_reg = /(http:\/\/|https:\/\/)((\w|=|\?|\.|\/|&|-)+)/g;
const http_reg_book = /(http:\/\/book|https:\/\/book|m)((\w|=|\?|\.|\/|&|-)+)/g;
let detailurl;
const query = await QuickAdd.quickAddApi.inputPrompt("请输入豆瓣图书网址或者ISBN:");
if (!query) {
notice("No url entered.");
throw new Error("No url entered.");
}
if (isbn_reg.exec(query)) {
isbn = query.replace(/-/g, "");
detailurl = await getBookByisbn(isbn);
} else {
if (!http_reg.exec(query)) {
new Notice('复制的内容需要包含网址或者ISBN码', 3000);
throw new Error("No results found.");
} else {
detailurl = query.match(http_reg)[0];
}
}
console.log('detailUrl:' + detailurl);
if (http_reg_book.exec(detailurl)) {
let bookdata = await getbookByurl(detailurl);
if (bookdata) {
new Notice('图书数据获取成功!', 3000);
QuickAdd.variables = {
...bookdata
};
}
} else {
new Notice('只能解析book.douban.com相关网址', 3000);
throw new Error("No results found.");
}
}
function isNotEmptyStr(s) {
s = s.trim();
if (typeof s === 'string' && s.length > 0) {
return true;
}
return false;
}
async function getbookByurl(url) {
let page = await urlGet(url);
if (!page) {
notice("No results found.");
throw new Error("No results found.");
}
let p = new DOMParser();
let doc = p.parseFromString(page, "text/html");
let $ = s => doc.querySelector(s);
let $2 = z => doc.querySelectorAll(z);
// 获取书名,尝试新的可能属性和结构来定位元素
let bookname = '';
const titleElement = doc.querySelector('h1[data-doubanid="book-title"]');
if (titleElement) {
bookname = titleElement.textContent.trim();
}
// 获取作者信息,考虑新的作者展示结构(假设可能变为列表形式等情况)
let author = '';
const authorElements = doc.querySelectorAll('.author > a');
if (authorElements.length > 0) {
author = Array.from(authorElements).map(el => el.textContent).join(', ');
}
// 获取内容简介,根据可能变化的包裹元素和类名等调整选择器
let intro = '';
const introElements = doc.querySelectorAll('.book-intro > p');
if (introElements.length > 0) {
introElements.forEach(element => {
intro += element.textContent + '\n';
});
}
intro = isNotEmptyStr(intro)? intro.trim() : ' ';
// 获取作者简介,同样按可能的新结构查找元素
let authorintro = '';
const authorIntroElements = doc.querySelectorAll('.author-intro > p');
if (authorIntroElements.length > 0) {
authorIntroElements.forEach(element => {
authorintro += element.textContent + '\n';
});
}
authorintro = isNotEmptyStr(authorintro)? '> [!tip]- **作者简介**\n>\n' + authorintro.trim() : ' ';
// 原文摘录部分,假设结构可能变化,重新适配选择器
let quote1 = '';
let quote2 = '';
const quoteFigureElements = doc.querySelectorAll('.quote-content');
const quoteSourceElements = doc.querySelectorAll('.quote-source');
if (quoteFigureElements.length > 0 && quoteSourceElements.length > 0) {
quote1 = `${quoteFigureElements[0].textContent.trim()}\n${quoteSourceElements[0].textContent.trim()}`;
if (quoteFigureElements.length > 1 && quoteSourceElements.length > 1) {
quote2 = `${quoteFigureElements[1].textContent.trim()}\n${quoteSourceElements[1].textContent.trim()}`;
}
}
quote1 = isNotEmptyStr(quote1)? '> [!quote]- **原文摘录**\n>\n' + '>>' + quote1 : ' ';
quote2 = isNotEmptyStr(quote2)? '>\n>> ' + quote2 : ' ';
let bookinfo = {};
// 提取页数,根据新的信息展示位置和格式调整正则(假设)
const pagecountMatch = doc.textContent.match(/页数:\s*(\d+)/);
bookinfo.pagecount = pagecountMatch? pagecountMatch[1] : '未知';
// 提取出版社,按可能变化的结构和文本格式调整查找方式(假设)
const publishMatch = doc.textContent.match(/出版社:\s*(.*?)\s*(出版年|ISBN)/);
bookinfo.publish = publishMatch? publishMatch[1].trim() : '未知';
// 提取出版年,同理调整提取逻辑(假设)
const publishyearMatch = doc.textContent.match(/出版年:\s*(.*)/);
bookinfo.publishyear = publishyearMatch? publishyearMatch[1].trim() : '未知';
bookinfo.bookname = bookname.replace(/(^\s*)|\^|\.|\*|\?|\!|\/|\\|\$|\#|\&|\||,|\[|\]|\{|\}|\(|\)|\-|\+|\=|(\s*$)/g, "");
bookinfo.cover = $("meta[property='og:image']")?.content;
bookinfo.type = 'book';
bookinfo.description = $("meta[property='og:description']")?.content;
bookinfo.douban_url = $("meta[property='og:url']")?.content;
bookinfo.author = "'" + author + "'";
bookinfo.isbn = $("meta[property='book:isbn']")?.content;
bookinfo.rating = $("#interest_sectl > div > div.rating_self > strong")?.textContent?? '-';
bookinfo.intro = intro;
bookinfo.authorintro = authorintro;
bookinfo.quote1 = quote1;
bookinfo.quote2 = quote2;
for (var i in bookinfo) {
if (bookinfo[i] === "" || bookinfo[i] === null) {
bookinfo[i] = "未知";
}
}
return bookinfo;
}
async function getBookByisbn(isbn) {
let isbnurl = "https://m.douban.com/search/?query=" + isbn;
let page = await urlGet(isbnurl);
if (!page) {
notice("No results found.");
throw new Error("No results found.");
}
let p = new DOMParser();
let doc = p.parseFromString(page, "text/html");
let $ = s => doc.querySelector(s);
let $2 = z => doc.querySelectorAll(z);
// 获取图书标题,按新的可能结构查找元素(假设)
let title = '';
const titleElements = doc.querySelectorAll('.search-result-item h3');
if (titleElements.length > 0) {
title = titleElements[0].textContent;
}
// 获取图书详情页网址,按新的结构定位链接元素(假设)
let detailUrl = '';
const linkElements = doc.querySelectorAll('.search-result-item a');
if (linkElements.length > 0) {
detailUrl = linkElements[0].href;
if (detailUrl.startsWith('app://')) {
detailUrl = detailUrl.replace('app://', 'https://');
}
}
if (!detailUrl) {
return null;
}
return detailUrl;
}
async function urlGet(url) {
console.log(url);
let finalURL = new URL(url);
const res = await request({
url: finalURL.href,
method: "GET",
cache: "no-cache",
headers: {
"Content-Type": "text/html; charset=utf-8",
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36'
},
});
return res;
}