即便我用这个抓下来数据了,在yaml区显示的字段名称会和我想要的名称不一样也不行
明白的, 但其实本地模板里 title: {{VALUE:bookTitle}} 把这个 title: 改掉就可以了, 按照您的习惯, 这里应该用 书名:
要不我们先不讨论细节了,
可以试试拿以下脚本完全替换掉 bookfromdouban.js 中的内容
– edit at 2024-12-24 返回数据里添加 key bookname intro authorintro 以适配模板所需字段
/**
*
* Yet another douban book script by Pray3r(z)
* https://kernfunny.org
* 来自 https://github.com/Pray3r/Obsidian-scripts/blob/master/scripts/fetchDoubanBook.js
*
*/
const notice = msg => new Notice(msg, 5000);
const headers = {
"Content-Type": "text/html; charset=utf-8",
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.100.4758.11 Safari/537.36'
};
module.exports = fetchDoubanBook;
async function fetchDoubanBook(params) {
QuickAdd = params;
try {
const query = await QuickAdd.quickAddApi.inputPrompt("🔍请输入要搜索的图书名称或ISBN:");
if (!query) return notice("没有输入任何内容");
const searchResult = await searchBooksByTitle(query);
if (!searchResult?.length) return notice("找不到你搜索的内容");
const selectedBook = await QuickAdd.quickAddApi.suggester(
obj => obj.text,
searchResult
);
if (!selectedBook) return notice("没有选择任何内容");
const bookInfo = await getBookInfo(selectedBook.link);
QuickAdd.variables = {
...bookInfo,
fileName: formatFileName(bookInfo.bookTitle) ?? " ",
// 2024-12-22 补充, 也按照 bookfromdouban.js 的对象 key value 结构, 抄一份数据
author: bookInfo['authors'],
publish: bookInfo['publisher'],
publishyear: bookInfo['publicationYear'],
pagecount: bookInfo['pageCount'],
cover: bookInfo['coverUrl'],
douban_url: bookInfo['bookUrl'],
// 2024-12-22 QuickAdd 的 macro 设置里可能是小写 filename
filename: formatFileName(bookInfo.bookTitle) ?? " ",
// 2024-12-24 添加 key bookname 以适配模板里的写法
bookname: bookInfo['bookTitle'],
intro: bookInfo['summary'],
authorintro: bookInfo['authorIntro'],
};
} catch (error) {
console.error("Error in fetchDoubanBook:", error);
notice("处理请求时发生错误");
}
}
async function searchBooksByTitle(title) {
const searchURL = `https://www.douban.com/search?cat=1001&q=${encodeURIComponent(title)}`;
try {
const response = await fetchContent(searchURL);
return parseSearchResults(response);
} catch (error) {
console.error("Failed to fetch book data:", error);
return null;
}
}
async function getBookInfo(url) {
try {
const response = await fetchContent(url);
return parseBookInfo(response, url);
} catch (error) {
console.error(`Failed to fetch or parse the URL: ${url}`, error);
return { message: 'Failed to parse the content due to an error.' };
}
}
async function fetchContent(url) {
return await request({
url: url,
method: "GET",
cache: "no-cache",
headers: headers,
timeout: 5000
});
}
function parseSearchResults(html) {
const document = new DOMParser().parseFromString(html, "text/html");
const doubanBaseURL = "https://book.douban.com/subject/";
return Array.from(document.querySelectorAll(".result-list .result")).map(result => {
const bookLinkElement = result.querySelector("h3 a");
const bookID = bookLinkElement?.getAttribute('onclick')?.match(/\d+(?=,)/)?.[0];
if (!bookID) return null;
const bookTitle = bookLinkElement.textContent.trim();
const bookInfo = result.querySelector(".subject-cast")?.textContent.trim() ?? "信息不详";
const bookRating = result.querySelector(".rating_nums")?.textContent || "暂无评分";
const ratingNum = bookRating === "暂无评分"
? '' : result.querySelector('.rating-info span:nth-of-type(3)')?.textContent || '评价人数不足';
return {
text: `📚 《${bookTitle}》 ${bookInfo} / ${bookRating} ${ratingNum}`,
link: `${doubanBaseURL}${bookID}`
};
}).filter(Boolean);
}
function parseBookInfo(html, url) {
const doc = new DOMParser().parseFromString(html, 'text/html');
const $ = selector => doc.querySelector(selector);
const $$ = selector => doc.querySelectorAll(selector);
const infoSection = $('#info');
const metaSection = $$('meta');
const bookId = url.match(/\d+/)?.[0] ?? '';
return cleanFields({
bookTitle: extractContent(metaSection, 'og:title', 'content', 'Unknown Title'),
subtitle: extractText(infoSection, /副标题:\s*([\S ]+)/),
authors: formatAuthors(extractMultipleContent(metaSection, 'book:author')),
isbn: extractContent(metaSection, 'book:isbn', 'content', ' '),
coverUrl: extractContent(metaSection, 'og:image', 'content', ' '),
publisher: extractText(infoSection, /出版社:\s*([^\n\r]+)/),
originalTitle: extractText(infoSection, /原作名:\s*([^\n\r]+)/),
translators: extractText(infoSection, /译者:\s*([^\n\r]+)/, '/'),
publicationYear: extractText(infoSection, /出版年:\s*([^\n\r]+)/),
pageCount: extractText(infoSection, /页数:\s*([^\n\r]+)/),
rating: extractText($('#interest_sectl strong.rating_num'), /([\d.]+)/) ?? ' ',
summary: extractIntroText($$, "内容简介"),
authorIntro: extractIntroText($$, "作者简介"),
quotes: extractQuotes($$),
contents: extractText($(`#dir_${bookId}_full`), '<br>'),
tags: extractTags(doc, $$),
bookUrl: url
});
}
function extractContent(elements, property, attr = 'textContent', defaultValue = ' ') {
return Array.from(elements).find(el => el.getAttribute('property') === property)?.[attr]?.trim() ?? defaultValue;
}
function extractMultipleContent(elements, property) {
return Array.from(elements)
.filter(el => el.getAttribute('property') === property)
.map(el => el.content.trim());
}
function extractText(element, regex = null, split = '') {
if (!element) return ' ';
const value = regex ? element.textContent.match(regex)?.[1]?.trim() : element.textContent.trim();
return split && value ? value.split(split).map(item => item.trim()) : value;
}
function formatFileName(fileName) {
return fileName.replace(/[\/\\:]/g, ', ').replace(/["]/g, ' ');
}
function formatAuthors(authors) {
return authors.length ? `"${authors.join(', ')}"` : ' ';
}
function extractIntroText($$, introType) {
const introHeader = Array.from($$("h2")).find(h2 => h2.textContent.includes(introType));
if (!introHeader) return ' ';
return Array.from(introHeader.nextElementSibling?.querySelectorAll("div.intro") || [])
.filter(intro => !intro.textContent.includes("(展开全部)"))
.map(intro => Array.from(intro.querySelectorAll("p"))
.map(p => p?.textContent?.trim() || '')
.filter(text => text)
.map(text => text.replace(/([*_`~-])/g, '\\$1'))
.join("\n")
)
.join("\n")
.trim() || ' ';
}
function extractQuotes($$) {
return Array.from($$("figure")).map(figure => {
const quote = figure.childNodes[0]?.textContent.replace(/\(/g, "").trim() || ' ';
const source = figure.querySelector("figcaption")?.textContent.replace(/\s/g, "") || ' ';
return quote || source ? `${quote}\n${source}`.trim() : null;
}).filter(Boolean);
}
function extractTags(doc, $$) {
const scriptContent = $$("script")[doc.scripts.length - 3]?.textContent;
return scriptContent?.match(/(?<=:)[\u4e00-\u9fa5·]+/g)?.join(', ') || ' ';
}
function cleanFields(fields) {
return Object.fromEntries(
Object.entries(fields).map(([key, value]) => [key, value ?? ' '])
);
}
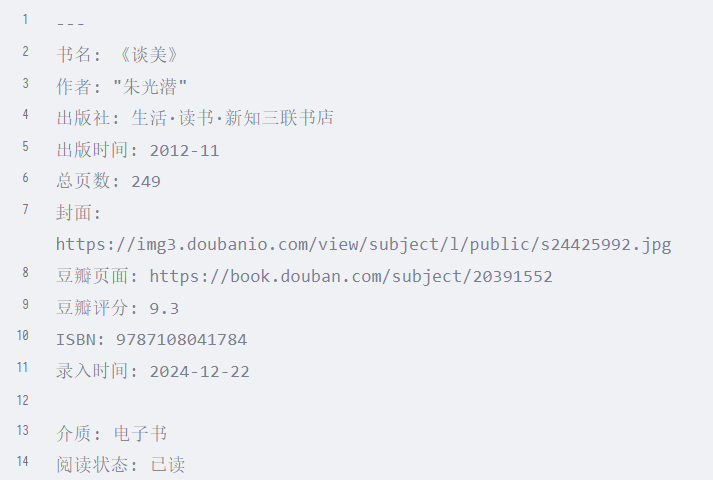
然后, 不动任何 QuickAdd 插件的设置, 就用以前配合 bookfromdouban.js 的那套操作流程, 那个模板 (模板指 这个图里的 别用配豆瓣的那个)
在确认备份过仓库后, 试试这个更新后的 bookfromdouban.js , 能不能管用
注:
交互细节可能会有点差异, 比如以前可能是输 豆瓣网址, 现在是输 ISBN


最后达到的效果应该是差不多
{kind=link}
能不能留一个邮箱,如果您方便的话,我打包数据库给您
感谢您的信任, 说实话, 我对这脚本也一知半解
细节搞不定很有可能, 确实不适合在这里刷屏讨论一堆小问题
… 但我们俩最后得有一个人把成果总结出来记录到这里, 这事先交给我吧