jimu
(吉木)
1
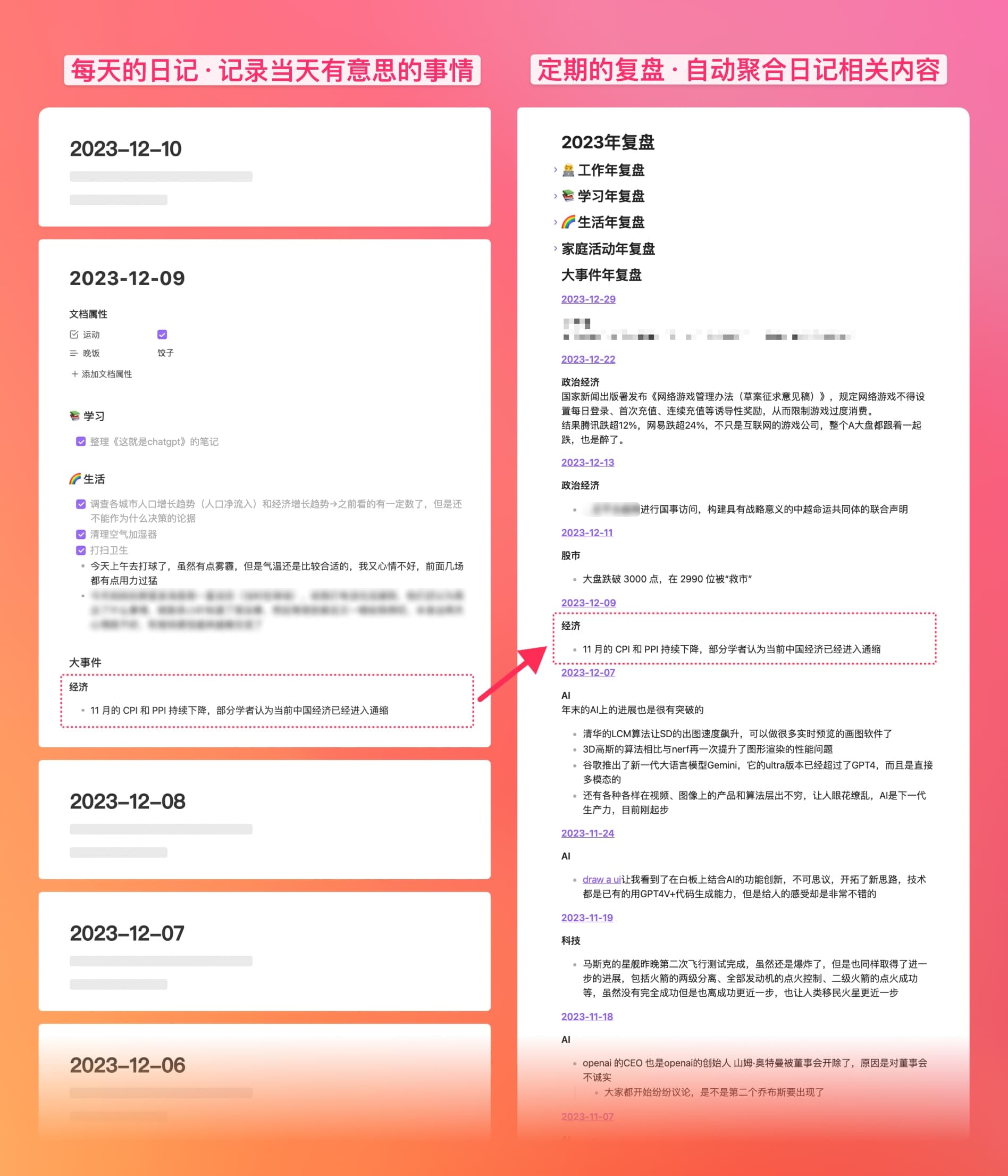
我是22年中开始在 Obsidian 中写日记的,记录了大半年后,发现周期性复盘时仍需要去一篇篇翻看,着实耽误时间,而日记的内容却又是比较固定的分类(工作、学习、生活、大事件、感触),所以就在想怎么能把本周或本月在工作、生活上完成的事情自动聚合在相应分类下,便于复盘时的回顾。
最终,通过 Obsidian 中的 Dataview 插件解决了这个问题。正好最近有朋友也有类似的问题,所以就决定把自己的方法分享出来。
最终效果
每天正常写日记,在复盘页面中自动对日记中的内容进行分类汇总查看。
实现步骤
下面我以月度复盘为例讲一下具体怎么实现的,周度和年度的,都是类似的方法,稍微调整下最后的代码即可
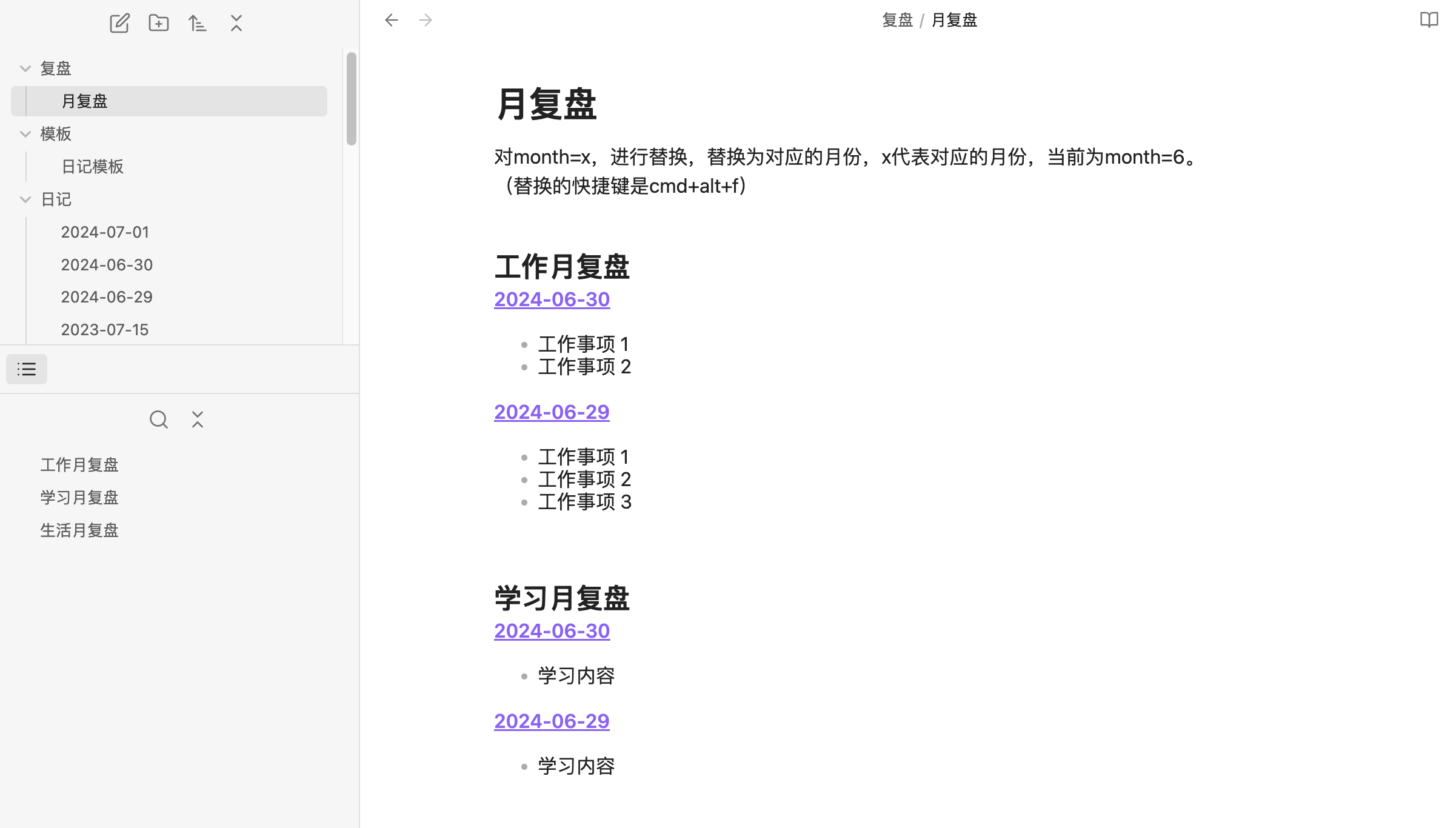
日记的配置
- 创建日记,按不同维度设置标题,比如:工作、生活、学习、大事件…
- 每篇日记的不同维度的标题格式需要保持一致,可以直接设置统一的模板,这样每次创建出来的就
复盘页的配置
-
建立一个复盘笔记
- 每个维度下的内容是通过 DataviewJS 进行查询自动生成的
-
粘贴具体的代码到笔记中
- 一段代码只会检索一个维度下的内容,上方的图中有多个维度,需要粘贴多段代码,配置完后,每次仅需要替换月份即可
- 将下面的代码复制到复盘笔记中,记得把开头改成```dataviewjs
//定义一个月份,查询这个月份的数据
let month=6
let year=2024
//定义一个变量,用于按此变量查询笔记中的具体标题:输入目标小标题(含#),例如:#### 项目进度条
const header = '#### 工作'
// 定义一个用于变量,用于存储指定范围内的笔记:按月份筛选笔记,并按修改时间降序排列
const pages = dv.pages('"日记"').where(b => moment(b.file.name).year()==year&&moment(b.file.name).month()==(month-1)).sort(p=>dv.date(p.file.name),"desc");
// 定义一个正则表达式,用于后续匹配指定笔记中的指定内容:某个笔记中从指定标题到下一个标题/横线/文章结尾的所有内容
const regex = new RegExp(`\n${header}\r?\n(.*?)(\n#### |\n---|$)`, 's')
//对所有查询出来的页面提取指定内容并显示出来
for (const page of pages) {
//根据查询到的笔记获取对应的文件
const file = app.vault.getAbstractFileByPath(page.file.path)
// 读取文件正文
const contents = await app.vault.read(file)
// 获得正文中的指定内容
const summary = contents.match(regex)
//显示指定内容
//显示空结果:if (summary) {
//不显示空结果:if (summary && summary[1].trim()) {
if (summary && summary[1].trim()) {
// 显示对应文件链接,或者用这个也行dv.header(2, '[[' + file.basename + ']]')
dv.span("**"+page.file.link+"**")
//显示对应正文内容
dv.paragraph(summary[1].trim())
}
}
- 粘贴之后,对如下的几处地方进行调整,这里以4级标题的工作为例,具体情况请自行修改
其他日记相关文章
7 个赞
查询出来是空的,代码如下
//定义一个月份,查询这个月份的数据
let month=10
let year=2024
//定义一个变量,用于按此变量查询笔记中的具体标题:输入目标小标题(含#),例如:#### 项目进度条
const header = '## 工作日志'
// 定义一个用于变量,用于存储指定范围内的笔记:按月份筛选笔记,并按修改时间降序排列
const pages = dv.pages('"2024年日记"').where(b => moment(b.file.name).year()==year&&moment(b.file.name).month()==(month-1)).sort(p=>dv.date(p.file.name),"desc");
// 定义一个正则表达式,用于后续匹配指定笔记中的指定内容:某个笔记中从指定标题到下一个标题/横线/文章结尾的所有内容
const regex = new RegExp(`\n${header}\r?\n(.*?)(\n# |\n---|$)`, 's')
//对所有查询出来的页面提取指定内容并显示出来
for (const page of pages) {
//根据查询到的笔记获取对应的文件
const file = app.vault.getAbstractFileByPath(page.file.path)
// 读取文件正文
const contents = await app.vault.read(file)
// 获得正文中的指定内容
const summary = contents.match(regex)
//显示指定内容 //显示空结果:if (summary) {
//不显示空结果:if (summary && summary[1].trim()) {
if (summary && summary[1].trim()) {
// 显示对应文件链接,或者用这个也dv.header(2, '[[' + file.basename + ']]')
dv.span("**"+page.file.link+"**")
//显示对应正文内容
dv.paragraph(summary[1].trim())
}
}
jimu
(吉木)
8
可以截几张文件目录结构和日记内容的图,只看dataviewjs 的话很难看出是哪的问题
//定义一个月份,查询这个月份的数据
let month=10
let year=2024
//定义一个变量,用于按此变量查询笔记中的具体标题:输入目标小标题(含#),例如:#### 项目进度条
const header = '## 工作日志'
// 定义一个用于变量,用于存储指定范围内的笔记:按月份筛选笔记,并按修改时间降序排列
const pages = dv.pages('"日记/2024年日记/2024年10月日记"').where(b => moment(b.file.name).year()==year&&moment(b.file.name).month()==(month-1)).sort(p=>dv.date(p.file.name),"");
// 定义一个正则表达式,用于后续匹配指定笔记中的指定内容:某个笔记中从指定标题到下一个标题/横线/文章结尾的所有内容
const regex = new RegExp(`\n${header}\r?\n(.*?)(\n# |\n---|$)`, 's')
//对所有查询出来的页面提取指定内容并显示出来
for (const page of pages) {
//根据查询到的笔记获取对应的文件
const file = app.vault.getAbstractFileByPath(page.file.path)
// 读取文件正文
const contents = await app.vault.read(file)
// 获得正文中的指定内容
const summary = contents.match(regex)
//显示指定内容 //显示空结果:if (summary) {
//不显示空结果:if (summary && summary[1].trim()) {
if (summary && summary[1].trim()) {
// 显示对应文件链接,或者用这个也dv.header(2, '[[' + file.basename + ']]')
dv.span("**"+page.file.link+"**")
//显示对应正文内容
dv.paragraph(summary[1].trim())
}
}
vvzeng
12
我的日记在文件夹20-Diary下,内容在类似2024-10-10文档标题## 工作模型下,但是结果还是没法显示。帮忙看下问题在哪里。多谢
//定义一个月份,查询这个月份的数据
let month=10
let year=2024
//定义一个变量,用于按此变量查询笔记中的具体标题:输入目标小标题(含#),例如:#### 项目进度条
const header = '## 工作模型'
// 定义一个用于变量,用于存储指定范围内的笔记:按月份筛选笔记,并按修改时间降序排列
const pages = dv.pages('"20-Diary"').where(b => moment(b.file.name).year()==year&&moment(b.file.name).month()==(month-1)).sort(p=>dv.date(p.file.name),"");
// 定义一个正则表达式,用于后续匹配指定笔记中的指定内容:某个笔记中从指定标题到下一个标题/横线/文章结尾的所有内容
const regex = new RegExp(`\n${header}\r?\n(.*?)(\n## |\n---|$)`, 's')
//对所有查询出来的页面提取指定内容并显示出来
for (const page of pages) {
//根据查询到的笔记获取对应的文件
const file = app.vault.getAbstractFileByPath(page.file.path)
// 读取文件正文
const contents = await app.vault.read(file)
// 获得正文中的指定内容
const summary = contents.match(regex)
//显示指定内容 //显示空结果:if (summary) {
//不显示空结果:if (summary && summary[1].trim()) {
if (summary && summary[1].trim()) {
// 显示对应文件链接,或者用这个也dv.header(2, '[[' + file.basename + ']]')
dv.span("**"+page.file.link+"**")
//显示对应正文内容
dv.paragraph(summary[1].trim())
}
}
jimu
(吉木)
15
20-diary 这个文件夹是在根目录下么,如果上层还有文件夹需要都写出来,如 dv.pages(‘“xxx/20-Diary”’)
vvzeng
16
我修改成了汇总多个月份的代码:
// 定义年份和月份范围,查询这个范围内的数据
let startMonth = 0; // 1月
let endMonth = 11; // 12月
let year = 2023;
// 定义一个变量,用于按此变量查询笔记中的具体标题:输入目标小标题(含#),例如:#### 项目进度条
const header = '## 💼工作模型';
// 定义一个用于变量,用于存储指定范围内的笔记:按月份筛选笔记,并按修改时间降序排列
const pages = dv.pages('"20-Diary"')
.where(b => {
const fileDate = dv.date(b.file.name);
return fileDate && fileDate.year === year && fileDate.month >= startMonth && fileDate.month <= endMonth;
})
.sort(p => p.file.ctime, 'desc');
// 定义一个正则表达式,用于后续匹配指定笔记中的指定内容:某个笔记中从指定标题到下一个标题/横线/文章结尾的所有内容
const regex = new RegExp(`\n${header}\\r?\\n(.*?)(\\n##|\\n---|\\$)`, 's');
// 对所有查询出来的页面提取指定内容并显示出来
for (const page of pages) {
// 根据查询到的笔记获取对应的文件
const file = app.vault.getAbstractFileByPath(page.file.path);
// 读取文件正文
const contents = await app.vault.read(file);
// 获得正文中的指定内容
const summary = contents.match(regex);
// 显示指定内容
if (summary && summary[1].trim()) {
// 显示对应文件链接
dv.span("**" + `[[${page.file.path}]]` + "**");
// 显示对应正文内容
dv.paragraph(summary[1].trim());
}
}
1 个赞
感恩(´ᴗ`ʃƪ)楼主,这是基于您的代码,在deepseek的帮助下的一个周回顾的版本,做完了分享给大家
dv.paragraph(`**当前周数:${moment().format('YYYY-第WW周')}**`)
// 获取本周的开始和结束日期(周一到周日)
const startWeek = moment().startOf('week').add(1, 'day'); // 假设周从周一开始
const endWeek = moment().endOf('week').add(1, 'day');
// 定义一个变量用于查询笔记中的具体标题(例如:## 计划)
const header = '## 计划'
// 筛选本周的笔记并按日期降序排列
const pages = dv.pages('"日记本"')
.where(b => {
const noteDate = moment(b.file.name);
return noteDate.isBetween(startWeek, endWeek, null, '[]'); // 包含起止日期
})
.sort(p => dv.date(p.file.name), "desc");
// 匹配标题内容的正则表达式
const regex = new RegExp(`\n${header}\r?\n(.*?)(\n## |\n---|$)`, 's')
// 显示结果
for (const page of pages) {
const file = app.vault.getAbstractFileByPath(page.file.path)
const contents = await app.vault.read(file)
const summary = contents.match(regex)
if (summary && summary[1].trim()) {
dv.span("**"+page.file.link+"**")
dv.paragraph(summary[1].trim())
}
}
- 使用
moment().startOf('week')和moment().endOf('week')获取周范围
- 通过
isBetween()方法判断日期是否在当周
- 添加了时区自适应(使用本地时区)
- 调整了周计算逻辑(默认按ISO周,周一到周日)
注意:
- 如果希望周日作为一周开始,可以移除
add(1, 'day')
- 确保日记文件名使用标准日期格式(如"YYYY-MM-DD")
- 结果会显示包含本周所有日记中"## 计划"章节的内容
- 日期范围包含当周第一天和最后一天
如果不需要显示周数,把开头第一行删掉。
实测:
1 个赞
实际操作之后发现,如果要从周一显示到周天,那么,startweek的地方的
.add(1, 'day')
要删掉