第三篇:三步走之“知其所以然”
接着前两篇,Step1 – 先预热 : 一文讲透Obsidian插件DataviewJS、Step2-知其然:一文讲透Obsidian插件DataviewJS,继续讨论第三步:知其所以然 。
这次我们回到开篇里的那段代码,通过分析这段代码,一起看看Dataview源码里的设计,追踪函数背后的所以然。
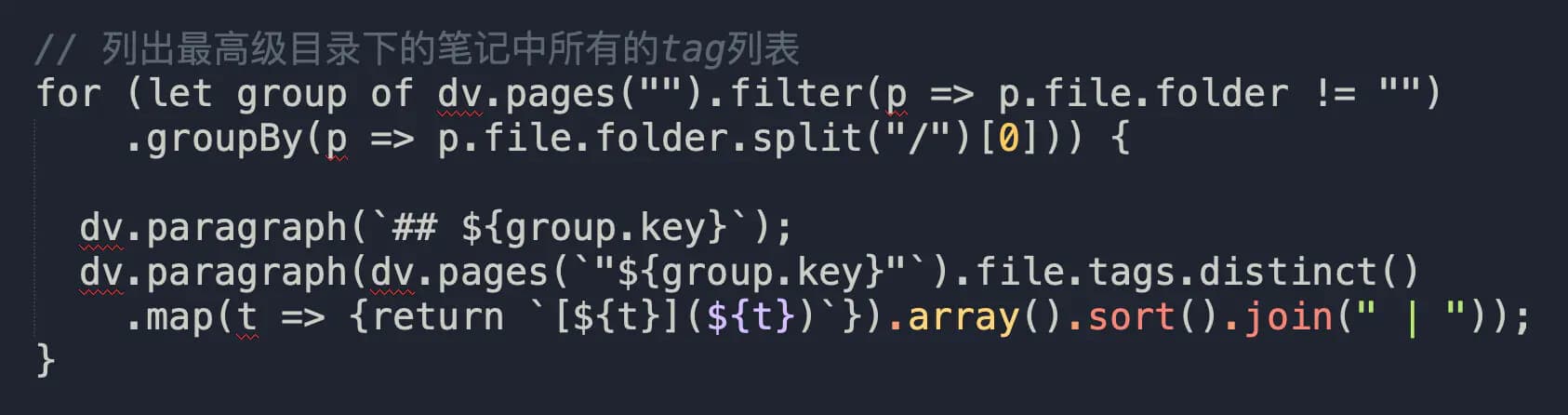
代码
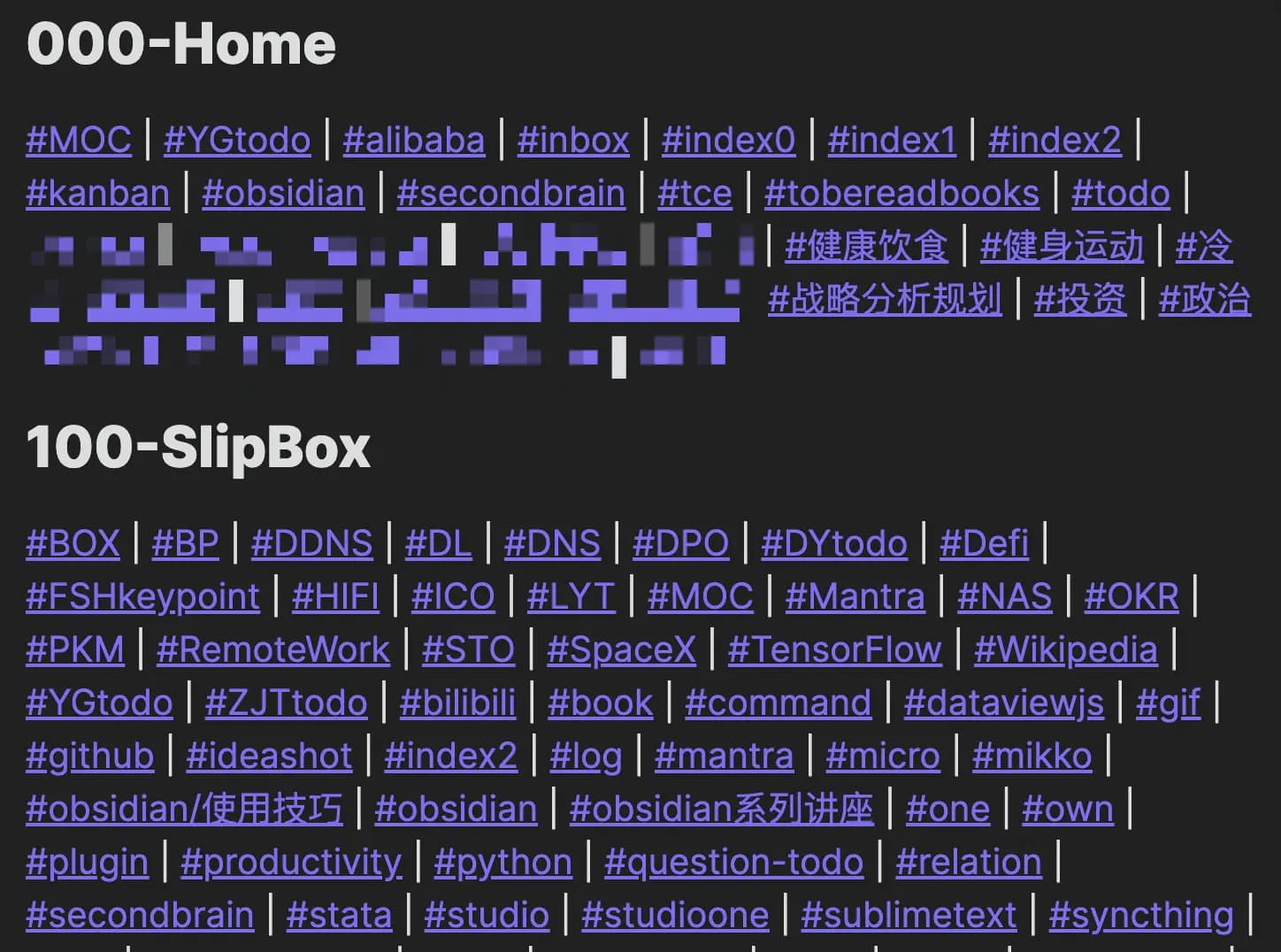
执行结果
正如Dataview的作者所说,Dataview里使用频率最高的是DataviewAPI,使用最多的数据结构是DataArray,作者专门放了两个页面做介绍:CodeReference页面 DataArray页面
dataviewAPI介绍页面
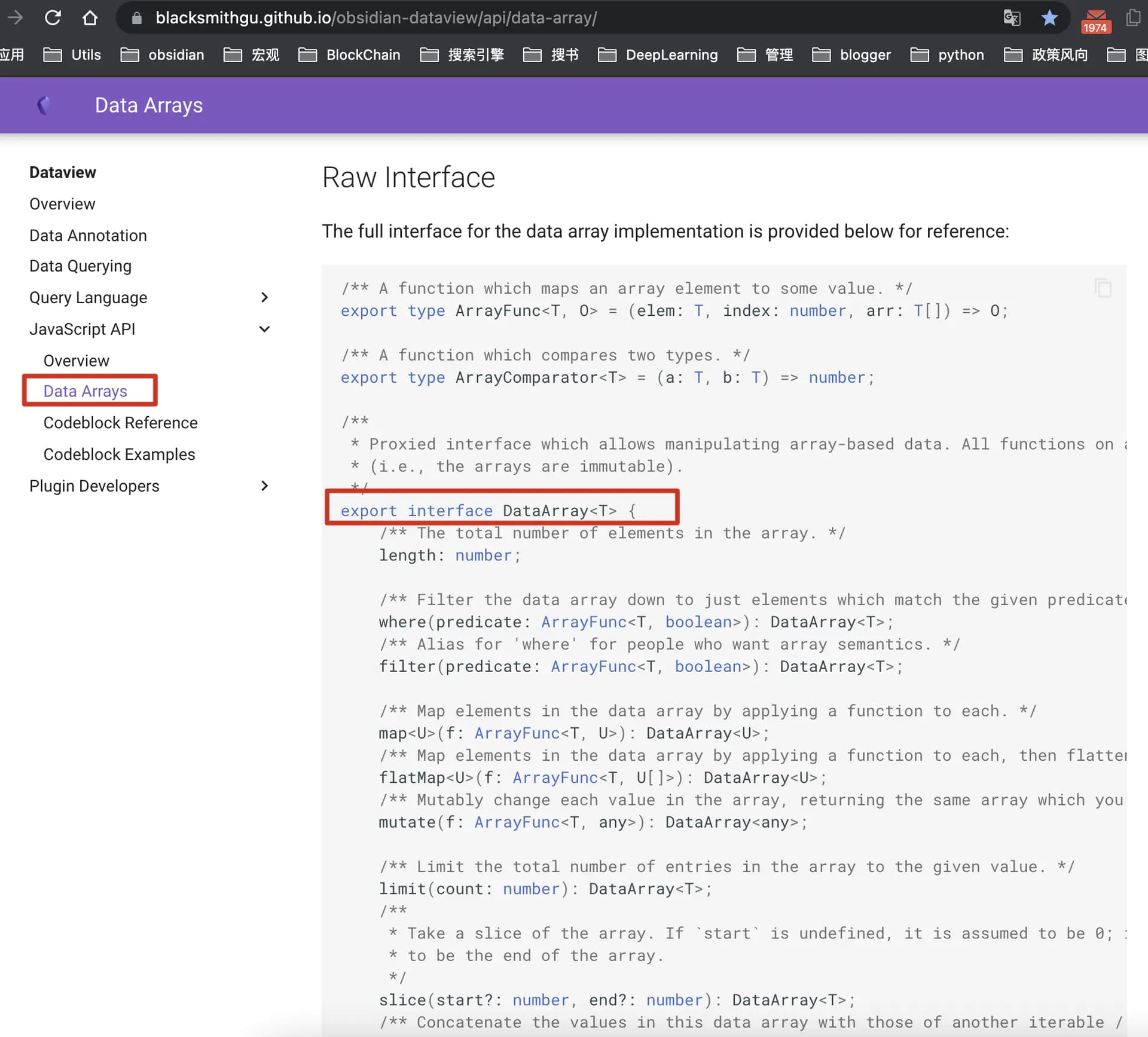
DataArray介绍页面
不过给出的信息还是不够用,很多关于函数、属性和参数的确切的含义搞不清楚,需要通过探究dataview的源代码来弄清。废话不说,先在github上下载dataview的源代码到本地,然后用Sublime text 打开:

下载源代码到本地
“工欲善其事必先利其器”,死磕源码前先做几件事。第一是安装Sublime text,软件免费、很良心,用的时候偶尔会弹出界面提示注册购买,关闭就好,不影响正常使用。它是那种在你不知不觉使用中情不自禁想掏腰包给开发者的软件,就像是obsdian一样,虽然免费,但易用性和带来的价值都让你情不自禁买个supporter支持一下。感慨一下,有时真是非常感谢这个开放的时代,在互联网上可以方便的找到自己想要的内容,没有做不到,只有想不到。sublime text官网
Sublime text下载下来后,不能直接用于typerscript的编写,需要安装node.js包,在Sublime text中下载安装typerscript插件和配置好编译器环境,在网上随便搜索一下相关文章就能找到,这里不赘述,附上常用的Sublime text插件包:sublime text 插件主页
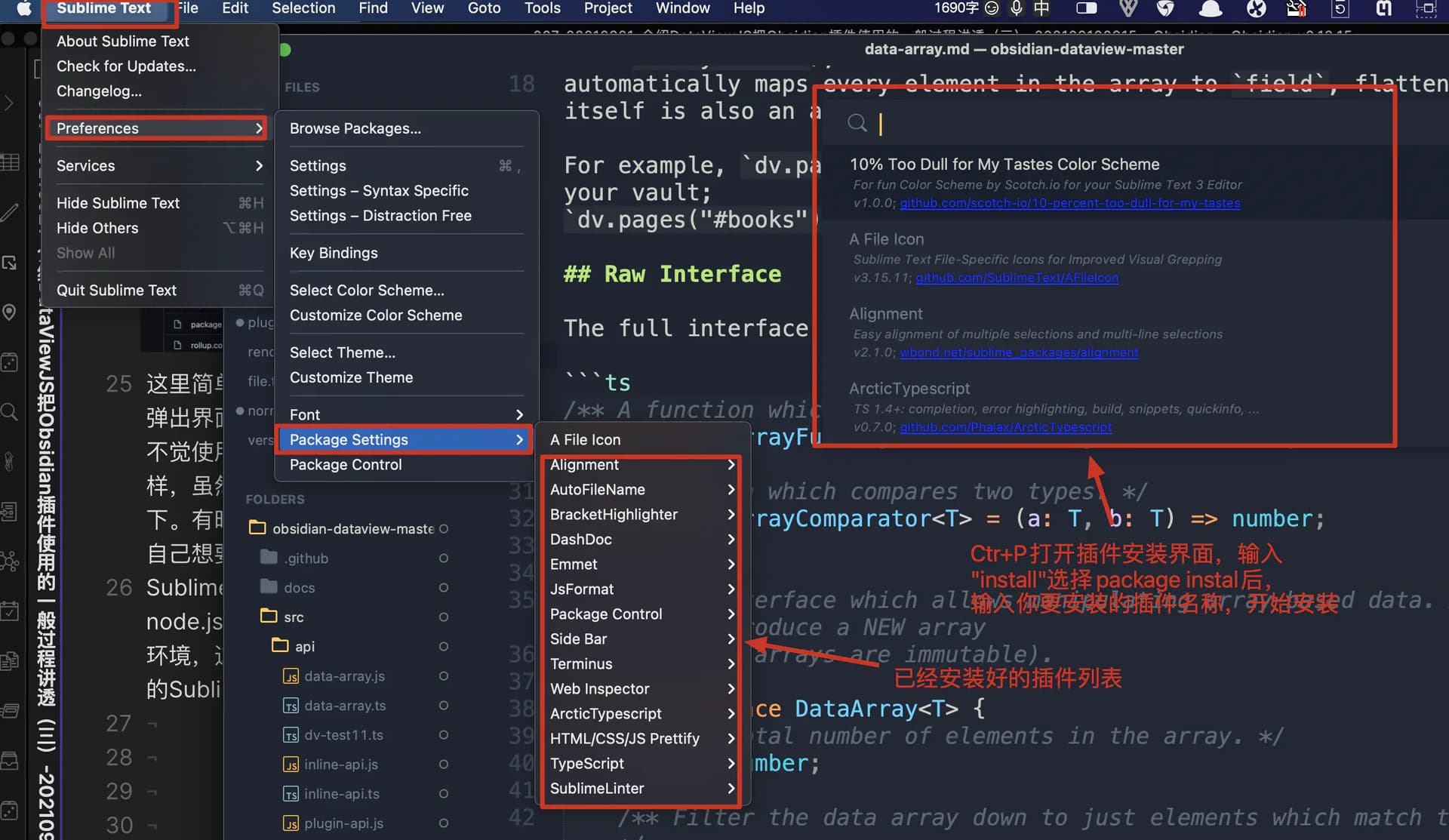
sublime text 插件包
在sublime text中打开dataview源代码的文件夹,导入项目:
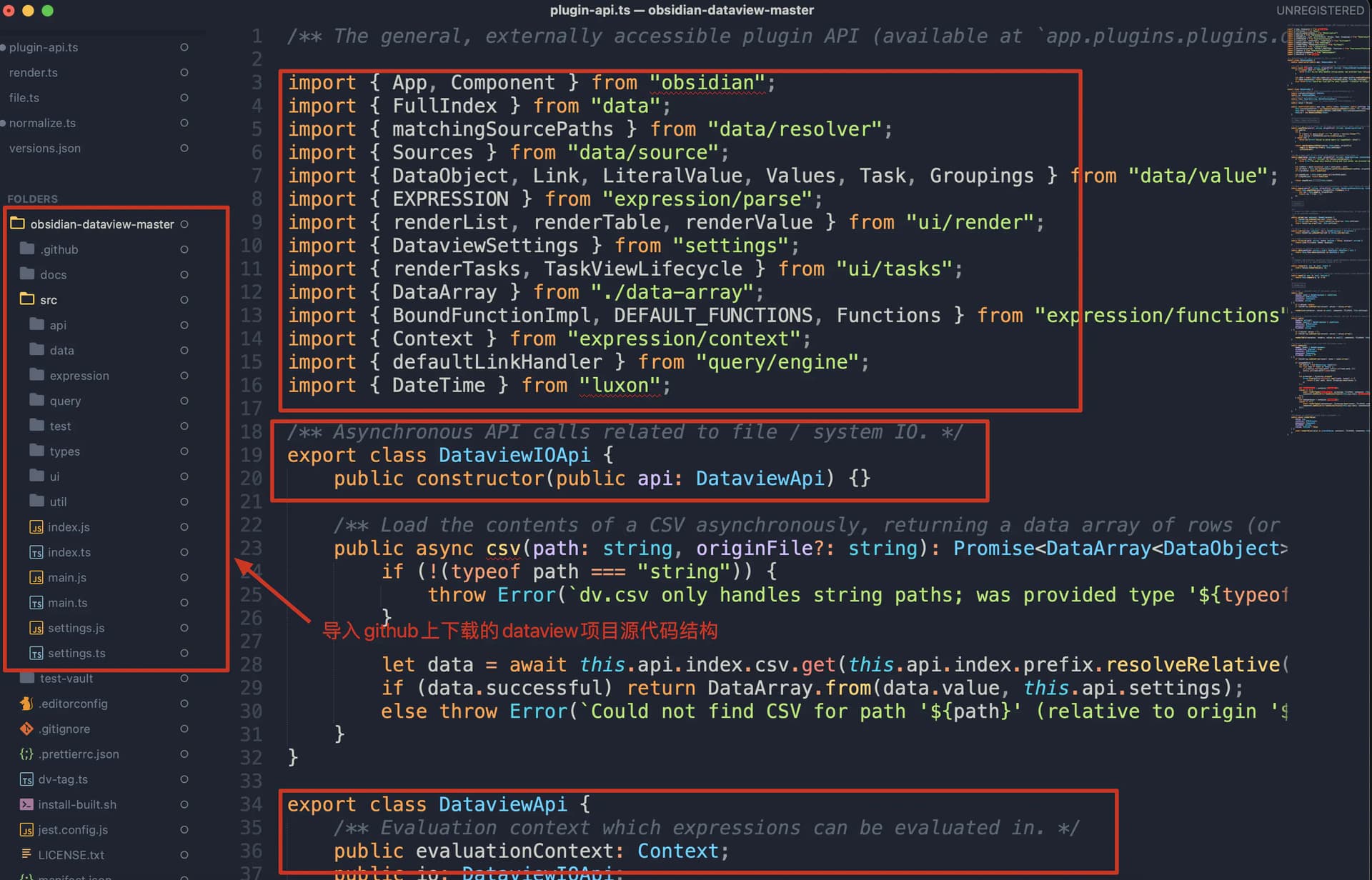
在sublime text中导入源代码
第二,看看这篇typerscripit速成教程,都是干货,不绕,实用,基本上两个小时就可以上手:
typerscript两小时速成教程(干货)
两小时速成教程
第三,写代码的时候遇到不熟悉的API,除了google一下之外,强烈建议装一个Dash软件,帮助快速检索各类api,每个api都有详细的介绍和范例,随用随查非常方便:dash官网

Dash使用
第四,针对难点突击一下,比如泛型和type的使用属于typerscript的高阶内容,这篇文章非常好,大家可以看看,临阵磨下刀:typerscript泛型使用的深入学习
难点:泛型与Type
这个是介绍typerscript里interface的用法,也不错:tyerscript的interface使用
难点:接口用法
好了,铺垫够了,我们开始代码的探索之旅:
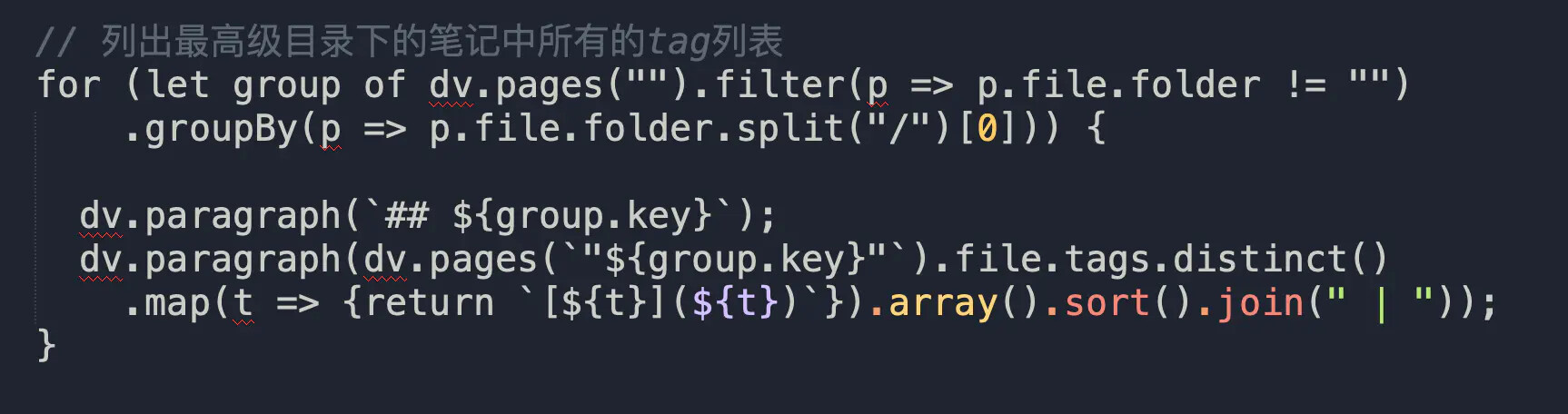
代码
这段代码使用频率很高,执行结果是:按照一级目录分组列出每个目录下所有笔记包含的标签情况,标签是经过去重的。每当我有新建标签冲动的时候,都会到这里查下,判断是否真的有必要再新建一个标签,因为标签过多会导致信息检索变得混乱,所以维持一个必要的最小标签集,尽量不要滥用它。
代码整体上依然是一个for...of循环,里面用了group,这些内容上一节都有介绍,不清楚的可以翻看。这次我们重点看看代码背后的东西究竟是什么。
首先是dv,dv是一个在obsidian运行时里的一个实例对象,我们对笔记的所有操作都要通过dv来进行。所以代码里到处都是dv.XXX,就是这个原因。
dv作为一个实例对象定义哪些属性和函数,我们看下源码。其实在github上也可以看到源码,我们要在多个源文件中来回跳着看,用github不方便,建议用Sublime text来阅读源码,里面提供了很多追踪代码要用的快捷方式,很方便。
github里直接打开源代码
这是使用github在浏览器里查看源码的情况,不推荐。
这是使用Sublime text查看源码的情况,推荐。
dv对应的源码位置在DataviewAPI.ts里:

DataviewAPI源代码
这个DataviewAPI.ts文件首先import一大推其他命名空间的库,这些库导入之后,就可以在编码时使用本文件之外定义的各种类、函数等等。这个ts文件重点定义了两个类DataviewApi和DatavieIOApi。使用频率最高的是DataviewApi下面的几个函数pages()、page()、pagePaths()。所以当我们写下dv.pages()时,就知道dv实际上是DataviewApi的一个实例对象,通过实例化后的对象来调用函数pages(),做笔记的一些操作。继续看pages()的代码:


pages函数源代码
pages()函数有两个可选形参,都是字符串类型,表示可以传入文件的标签或者目录或者文件路径,函数返回一个DataArray对象,这个对象使用一个嵌套式的泛型结构,数据类型是一个Record类型的对象,其中每个Record对象由key和value两部分组成,key为string类型,value为LiteraValue类型。那么究竟这个DataArray是个什么结构,我们继续跟进去看看它的源码:
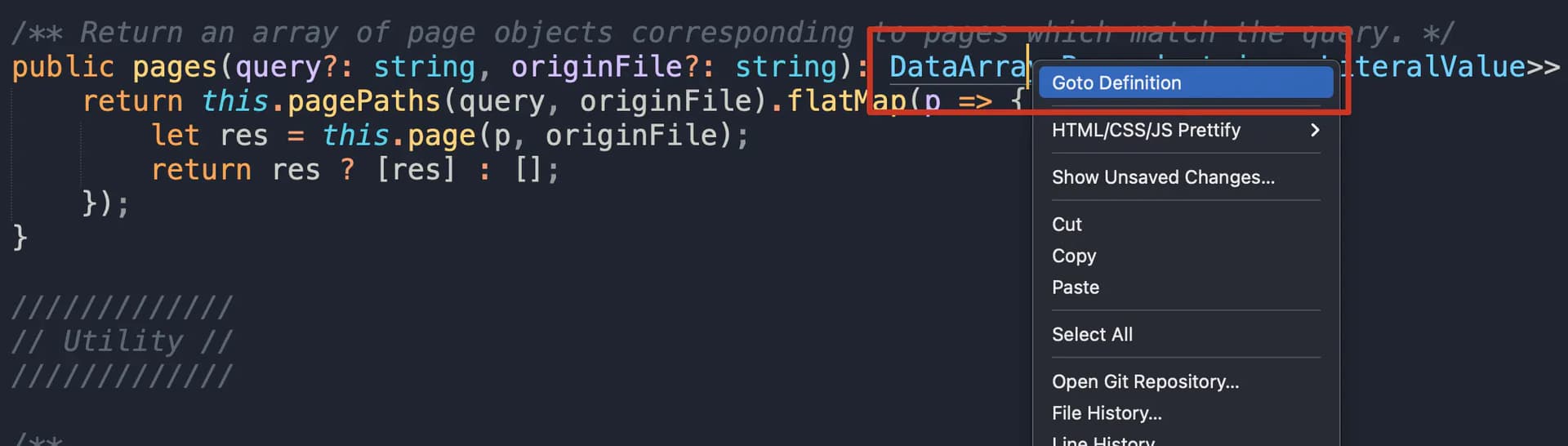
向下追踪DataArray的定义源代码
这个操作在Sublime text中很方便,在DataArray上右键打开点击goto Defination就直接进入DataArray的源码了:
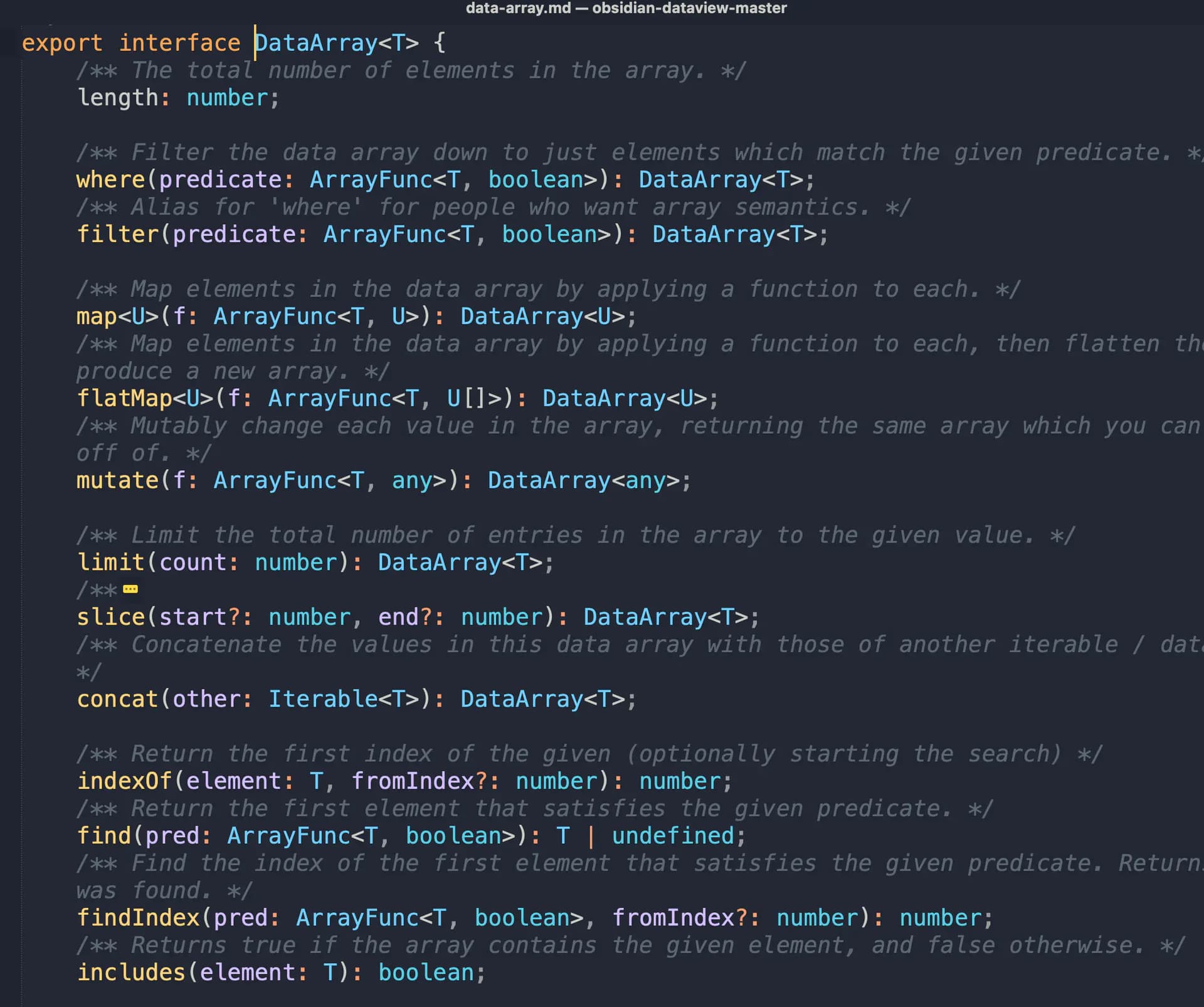
DataArray源代码
可以看到,DataArray这是一个接口,里面定义了一个length的属性,表示这个数据数组的长度。其他的都是针对这个数组的一些操作函数,包括了耳熟能详的where(),filter()、groupBy()、sort()、map()、distinct()、sort()、array()、find()等等操作,每个函数返回的类型也不一样,要具体看。
我们结合代码看下:
dv.pages("").filter(p => p.file.folder != "").groupBy(p => p.file.folder.split("/")[0])
dv.pages("")用“”做参数,表示选择obsidian vault笔记库中的所有笔记,类似SQL:select * from 笔记库。然后用filter()函数进行过滤,()里面是过滤条件。为什么这么写,我们看下filter的源码:

filter函数源代码
filter传入了一个ArrayFunc类型的对象,返回一个DataArray对象,两个都用到了泛型参数。继续进去看ArrayFunc源码:

ArrayFunc定义源代码
ArrayFunc是一个自定义的数据类型,它是一个函数类型,有三个参数:一个泛型T的对象参数elem,一个number类型的index参数表示索引号,一个泛型一维数组arr[],函数返回值是0。
也就是说filter函数的形参可以传入一个函数表达式,返回的结果是一个DataArray对象。
filter(p => p.file.folder != "")
()里的内容是typerscript中函数赋值的写法,把p作为一个参数传给后面的表达式中进行运算。在这的上下文就等价于:
//函数定义并赋值
function fn(darr :DataArray) {
return darr.file.folder != "";
}
//返回一个DataArray对象
fliter(fn(p));
这个p是dv.pages()函数返回的DataArray对象。
我们再进入源码追溯filter(fn(p))的调用链,看看它是怎么一步步返回一个DataArray对象的:
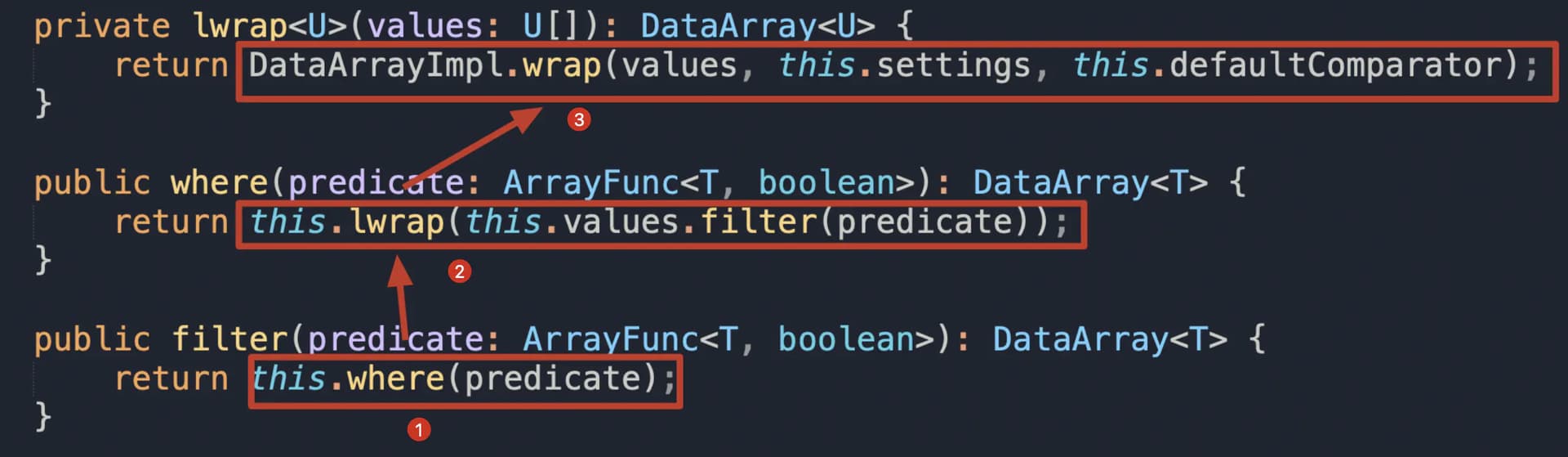


追溯filter的调用链
如上所示一共有六个步骤,顺着调用链一步步向上追踪到最底层,发现filter函数先是new了一个DataArrayImpl的实例(DataArrayImpl是DataArray接口的实现类,用来实例化DataArray用的,我们使用的每一个dv,都是通过DataArrayImpl实例化产生的),在new()一个DataArrayImpl的过程中,先执行static方法,进行参数初始化,然后调用private构造器函数constructor(),生成一个实例对象。这个构造过程,就把dv.pages(“”)返回的笔记集合p作为一个形参传入到filter函数里,实例化之后的DataviewImpl会在调用filter()函数时执行第六步:

关键一步
这里的values就是在实例化阶段,传入的参数:笔记集合p转换成的一个数组,注意!这里的values是一个纯数组,所以这里调用this.values.filter()函数,是数组的filter函数,即Array.protype.filter(),而不是DataArray中定义的那个filter,千万不要搞混。
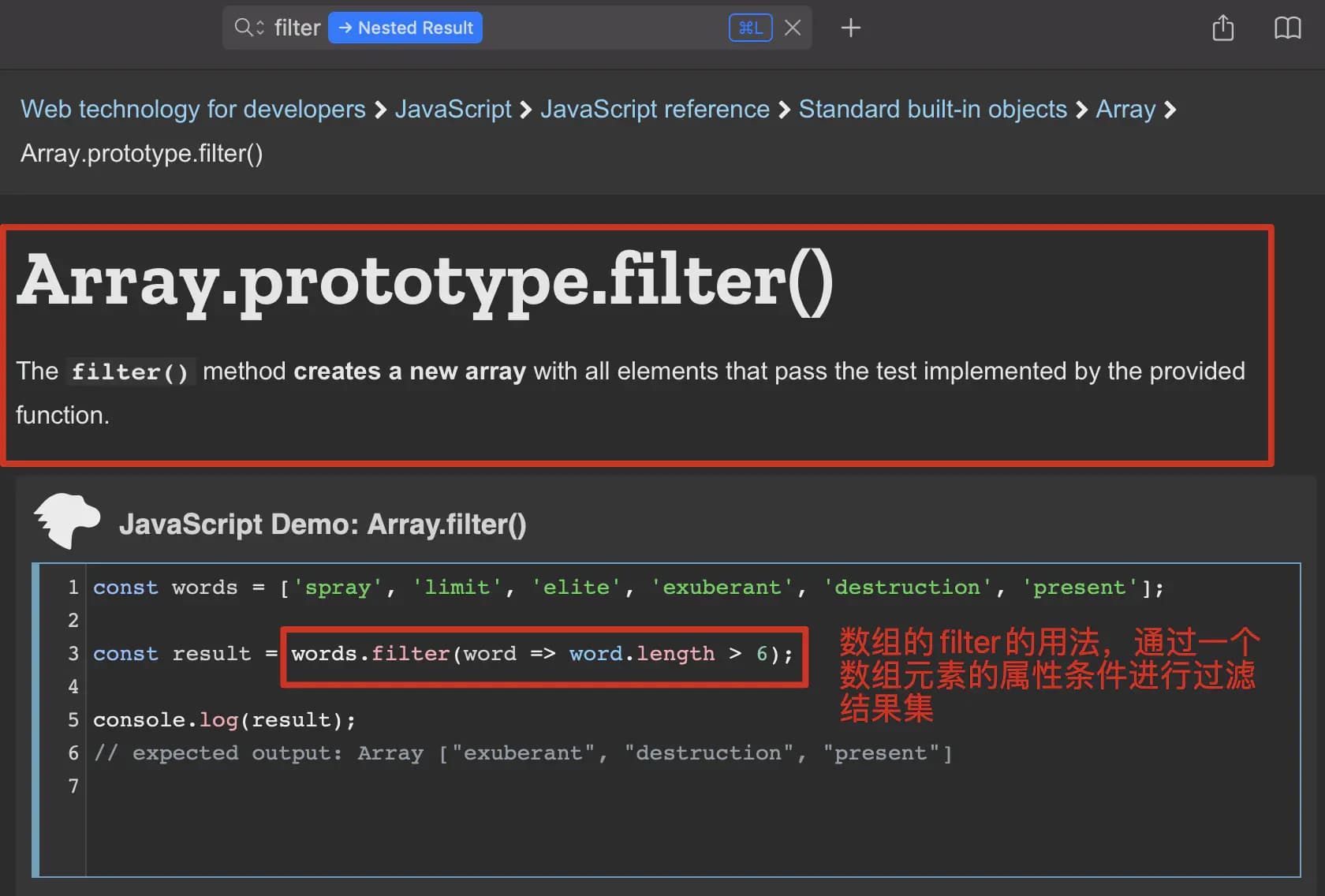
注意是js数组自带的filter函数
调用效果是:根据传入数组里某个元素的条件表达式来过滤数组,最终生成一个全新的数组。
小结一下:
dv.pages("").filter(p => p.file.folder != "")
上述表达式运行的效果是:
首先,let p = dv.pages(""),p作为参数传入filter的调用链中,在DataArray实例化阶段被转换成数组pages[];最后,在调用链的where()里,pages[]数组调用了Array.prototype.filter()函数,即:pages[].filter(),这个filter函数从pages[]数组里取出某个page元素,用"page.file.folder != 0"这个条件表达式过滤数组pages[],最后把符合条件的page重新生成一个新数组返回。返回的新数组作为DataArray一个构造参数,最终生成一个新的DataArray对象,整个过程结束。
虽然有些绕,但看懂这个表达式,其他类似的表达式都可以用相同的思路去刨根问底,所以这番折腾是有价值的。后面groupBy的逻辑类似,不展开,可以自己试着去弄明白背后的过程。类似的,
dv.pages("${group.key}").file.tags.distinct()
到这里的分析逻辑和上面filter的类似,distinct返回的也是一个DataArray对象,这里面保存了分组去重之后的tags合集。
.map(t => {return '[${t}](${t})'}).array().sort().join(" | ")
map常常用来构造dv.table里二维数组的内容,这里使用map构造了一个标签链接的字符串形式的内容,也不做展开了。
到此为止,追踪源代码的方法也做了介绍,大家可以自己尝试去理解看到的脚本内容,理解这些对自己写出脚本也是非常有帮助的。
最后,说下dataview的调试,我的习惯是在sublime text里写代码,这里有语法高亮和函数提示,不容易出语法错误。调试的时候把代码复制到obsidian中,为了验证代码的问题,在不同的位置可以加一些断点监测的语句,由于obsidian中无法使用console.log()来打印结果信息,可以用dv.list()来代替,总的来说obsidian中的dataview调试环境还是非常不友好的,和IDE环境的智能提示以及debug都没法比,希望以后新的版本可以不断改良,否则一些较复杂的脚步运行出错后,调试起来实在是让人抓狂。
这个dataview系列的三篇文章到此就结束了,希望大家通过这几篇介绍掌握熟悉obsidian第三方开源插件的一般方法,给自己的生产力跃升插上翅膀!