第二篇:三步走之“知其然”
我们接着上一篇,Step1-先预热:一文讲透Obsidian插件DataviewJS,继续讨论第二步:知其然。 作为热身,我们还是先看一段相对简单一点的代码:
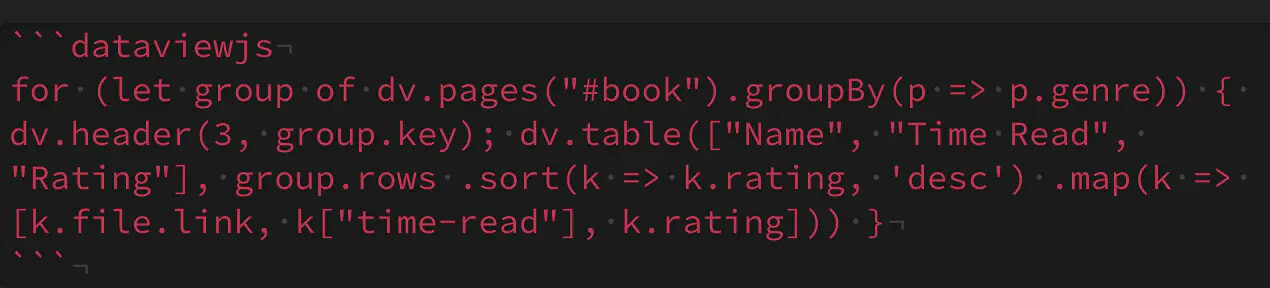
代码片段
这段代码的运行结果是:在笔记库vault中,把标签为“book”的笔记找出来,然后按照书籍的类型进行分组,每组用一个表格的形式展示出来,表格的表头包含“姓名name”、“阅读时间TimeRead”、“评分Rating”,几个字段,表格的内容按照书籍评分降序排列。执行效果如下:
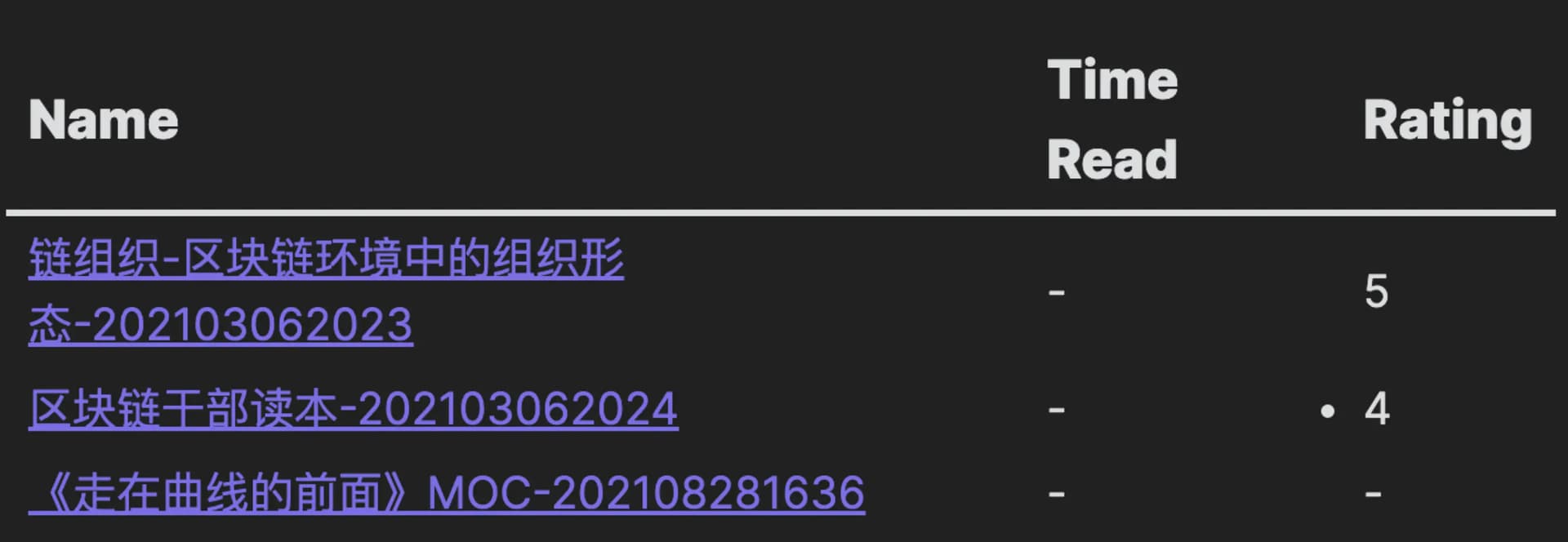
执行结果
分析代码,格式排版很重要,我的习惯是把他们放到代码编辑器里进行排版,这样便于自己阅读和理解,这里选用Sublime Text来编写和阅读代码。具体怎么用,后面找机会单独介绍,排版以后的代码如下:
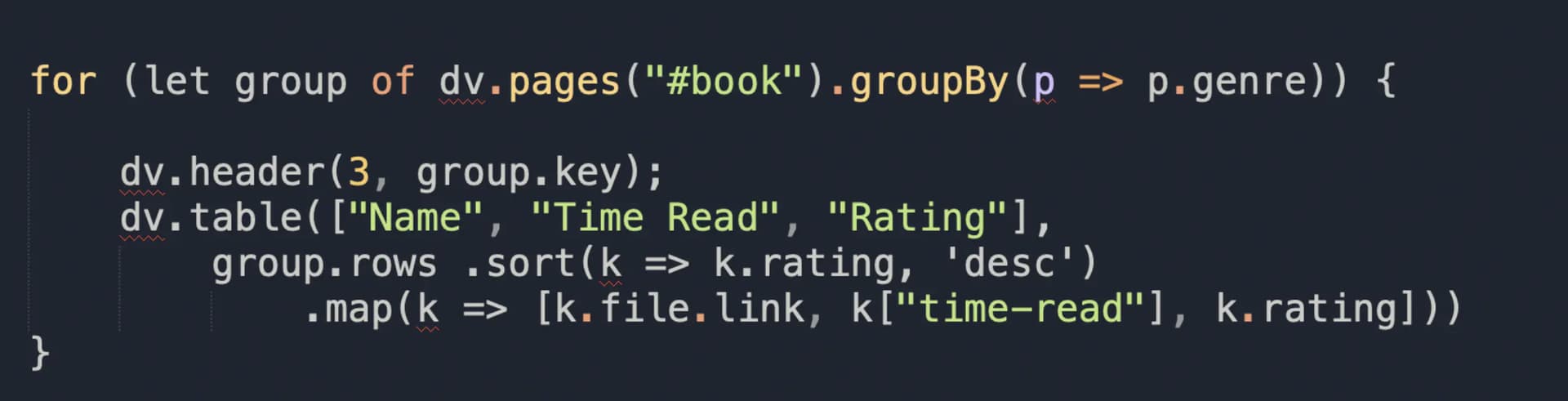
格式化后的代码–可读性强
这么看顺眼多了,也更好理解。整段代码是嵌入在obsidian笔记中的,使用“davaviewjs”做开头,使用“”做结尾,里面放的是javascript代码,准确的说应该是typerscript代码。因为Dataview的作者使用的typerscript来开发的Dataview插件。这个从github上的项目文件后缀就可以看出来,都是以*.ts结尾的。
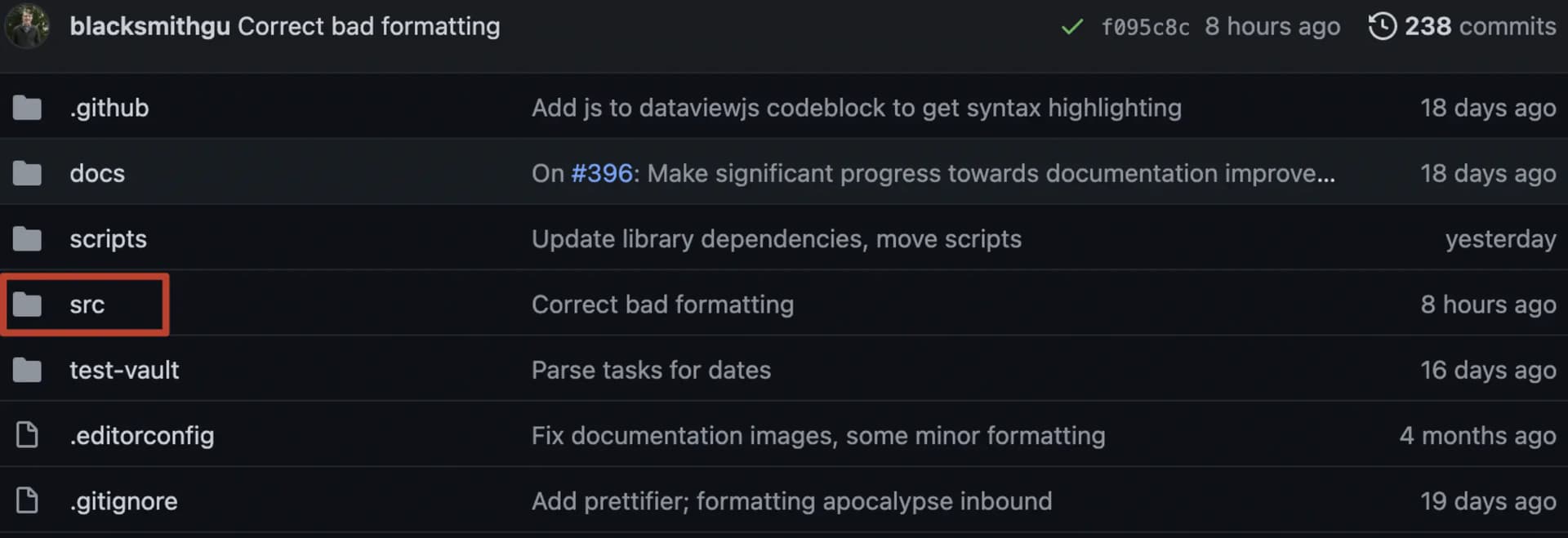
代码源文件src下面包括多个目录,随便打开一个里面的文件都是以*.ts结尾。这里api和data两个目录,后面我们会重点介绍里面几个关键的源代码文件。看源代码可以在浏览器的github里打开直接看,不过我强烈建议把整个源码下载到本地,然后用Sublime Text导入整个项目,借助代码编辑器读源代码的效果会高出数倍。
❶ 首先是一个for语句,在typerscript的for循环语句有两种形式,这里采用的是常用的for…of语法。意思就是在一个集合中逐一取出一个元素进行遍历,针对取出的这个元素,做一些处理动作。for循环体()里的部分是对遍历的集合做一个条件限制。
❷ let 是一个定义变量的关键词,类似javascript里面的var,不过let的用法更灵活,它可以定义任意类型的变量,比如
let aaa : string = "hello"
这里就定义了一个string字符串类型的变量叫aaa。还可以定义别的,比如
let dance = function(name : string) {return "Look! ${name} is dancing!"}
这里let就定义了一个函数变量dance,这个函数定义用到了function关键词,在()里定义了一个需要输入的参数name,而且明确name的类型为string字符串,在{}里定义了函数要做的动作,return是关键词,表示整个函数运行完后返回的结果。这里函数返回的是一个字符串,一句话:XXX在跳舞,这里的XXX因为在"“内,所以使用了简写的方式,使用${}的方式直接调用了参数name的值,比如函数是dance(“Jack”),那么结果输出就是:“Look! Jack is dancing!””。当然typerscript在定义函数时有好几种不同的方式,比如刚才的定义也可以写成:
let dance => (name : string): "Look! ${name} is dancing!"
看上去是不是简洁了很多,这是使用=>定义函数的方式,在typescript的代码里十分常见,要习惯。其实,typerscript和JavaScript相比,代码定义更严格,它是对JavaScript的扩充,针对泛型的使用更高频,代码更简洁,但有时候过度简洁读起来不是特别好理解。比如还是这句,如果用泛型来定义可以写成:
let dance<T> => (args : T) : T
这里使用泛型的好处就是可以不用事先确定参数的类型和返回的类型,函数的适用范围更灵活,后面我们讲解dataviewAPI的部分源码时会经常碰到这样的情况。一般我们写程序,比如java等,编程的过程都是针对值进行编程,typerscript前进了一步,它能够针对类型进行编程。比如还是这个例子,我们可以定义一个自定义的新类型danceType,让它把这种函数形态给记录下来以后随时使用:
type danceType<T> = (args : T) => T
type是一个关键词,可以理解为给一个自定义的数据类型起了一个别名,这个就是给一个自定义的函数类型的一个数据类型,起了个别名叫danceType。或者举个简单的例子:
type mystr = string
就是给string类型另外起了一个别名叫mystr,实际上还是同一个类型。要义就是通过这种方式对类型进行编程了。结合上泛型,就变得十分灵活,不过可读性也确实烧脑了。读源码的时候这种类型+泛型的代码很多,需要熟悉和习惯。后面我会留一些配套的文章,供大家慢慢学习熟悉。
❸ 继续看例子:for的()里的意思,使用let定义了一个group变量,因为group放在了for…of中间,所以group就是of后面跟着的那个集合中取出的一组元素,确切的说就是
dv.pages("#book").groupBy(p => p.genre)
所代表的一组元素集合,是一个数据结构。这里要弄清含义,就需要看看github上作者给出的DataviewAPI了,里面给出了常用的一些函数的说明,位置在首页的概述部分:
打开后,可以看到一些常用的函数:
DataviewAPI页面
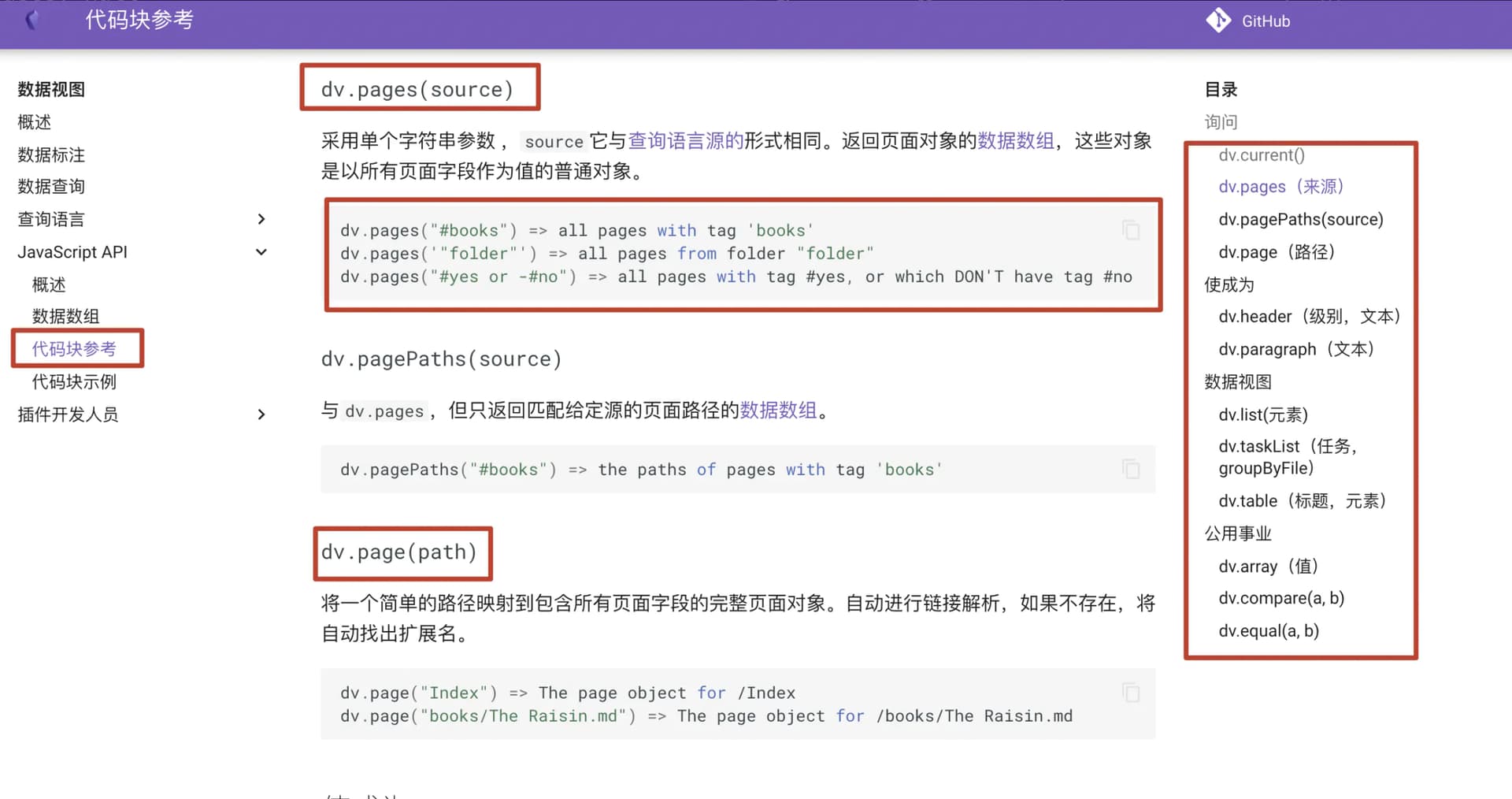
API中文翻译

API英文原文
我的英文不好,所以经常是用翻译软件,中英文来回切换着看,这样效率更高一些。
从API文档里可以看到,dv是在obsidian笔记中调用Dataview的一个代名词,一般的函数都是从dv.XXX开始的。dv.pages(source),这个函数可以根据传入参数source的不同返回符合参数条件的笔记集合,主要支持两种方式:按标签和按笔记所在的目录或者路径,这些条件可以通过与或非进行条件组合。从作者给的例子里可以看出函数返回的是一个笔记的集合pages,里面会有一篇一篇的笔记page。实际上从这个API文档中我们得到的确切信息不足,比如返回的结果到底是什么类型,看不出来,只能猜出大概的意思是一个笔记的集合,但是具体的数据类型并不清楚,这种不清晰会给我们后续理解代码带来很大的障碍,编程不是感觉怎么怎么样,而且确切的推理和推导过程,计算机代码是严丝合缝的,不是靠猜的。要想做到这点,就需要更进一步追踪进去看源代码了,这个我们放到后面第三步再说,这里先意会吧。其他函数的意思大家自己去看API,不再逐个做解释。
typescript支持函数嵌套的写法,前一个函数返回的对象可以继续调用他所支持的函数继续一层层调用下去,所以会出现很多个函数.函数.函数这样一直连续调用一长段,很正常,习惯就好。在这里dv.pages()函数返回笔记页面构成的集合对象后,继续调用了一个groupBy函数进行分组,groupBy()内部的写法是一个典型的泛型参数传参的写法,这个后面我们看源代码的时候在继续深究,这里只需要明白,groupBy()函数是将前面的笔记集合中的元素,用genre分类属性作为对笔记集合的分组条件,这样返回的结果就是按照分类把书籍分成了几组,所以for循环的次数,和分组后的组数是一致的,看一眼for循环体内的句子,我们大概能猜到,每组书籍应该是以表格形式来呈现的,有几组就有几张表格。
❹ for循环体内的语句,不展开,使用了dv.head()与dv.table()的方式来输出三级标题和画表格。这里需要重点提两个地方:
第一是group.key的用法。group在前面提了,是每次for循环从笔记集合体遍历出来的一个笔记子集合,由于前面用了genre属性做分组,分组保存的形式,类似key、value的方式,key保存的是分组的genre属性的值,value保存的是某个分组下的笔记的集合。所以,group.key的值就是genre分类,把它当成一个三级标题输出。
第二个是dv.table()的用法,这里不展开讲,用到了排序和map构造二维数组作为填充表格的内容,这个也放到第三步里我们看源代码来详细解读。
第二步,知其然的部分就说到这,篇幅有限,下篇继续。
