- 再贴上一份几年前对卡片盒的研究资料以供参考
![]()
![]() 太赞了,谢谢你的分享
太赞了,谢谢你的分享 ![]()
![]()
- 局部有类似于分类的结构我觉得很正常,毕竟话题分支的结构和分类的结构本来也有很多相似之处。
- 但我认为编号的整体功能和分类号还是明显不同的。比如我从 ZK2 目录里抽出了这一串笔记,我不认为它对应一个分类逐步细化的过程:
-
2基本术语和方法 -
21功能的概念 -
21/3功能分析的参考单位 -
21/3d系统概念(系统概念的澄清) -
21/3d18系统/世界 -
21/3d18c世界的复杂性 -
21/3d18c50复杂度/单位 -
21/3d18c50e相互渗透的概念 -
21/3d18c50e6a不安(人类学)
-
- 而且 ZK2 里的根节点大致可以认为只有这 11 个:组织理论,功能主义,决策理论,办公室,正式/非正式秩序,主权/国家,个人概念/个人问题,经济,特别说明,古老的社会,先进的文明。我不认为这是属于分类学的框架。
- 至少卢曼自己是不指望能单纯靠这种编号来找到笔记的。按他在《与卡片盒交流》里的说法,「考虑到卡片盒没有系统的顺序,我们必须规范重新发现笔记的过程。」从我自己的体验来看,这种笔记方法(尤其是笔记规模达到一定程度以后)的检索能力有相当一部分依赖于关键词索引 + 笔记间的大量链接,当然局部的笔记序列结构(包括其分支结构)也会在其中发挥作用。
1 个赞
关于通过关键词索引的检索,我的理解是指通过关键词的字母/拼音顺序(人类语言)来查找,然后返回链接到该关键词的分支入口(可以有多个)。比如这样:
- 输入/选择关键词
- 返回链接到关键词的分支入口
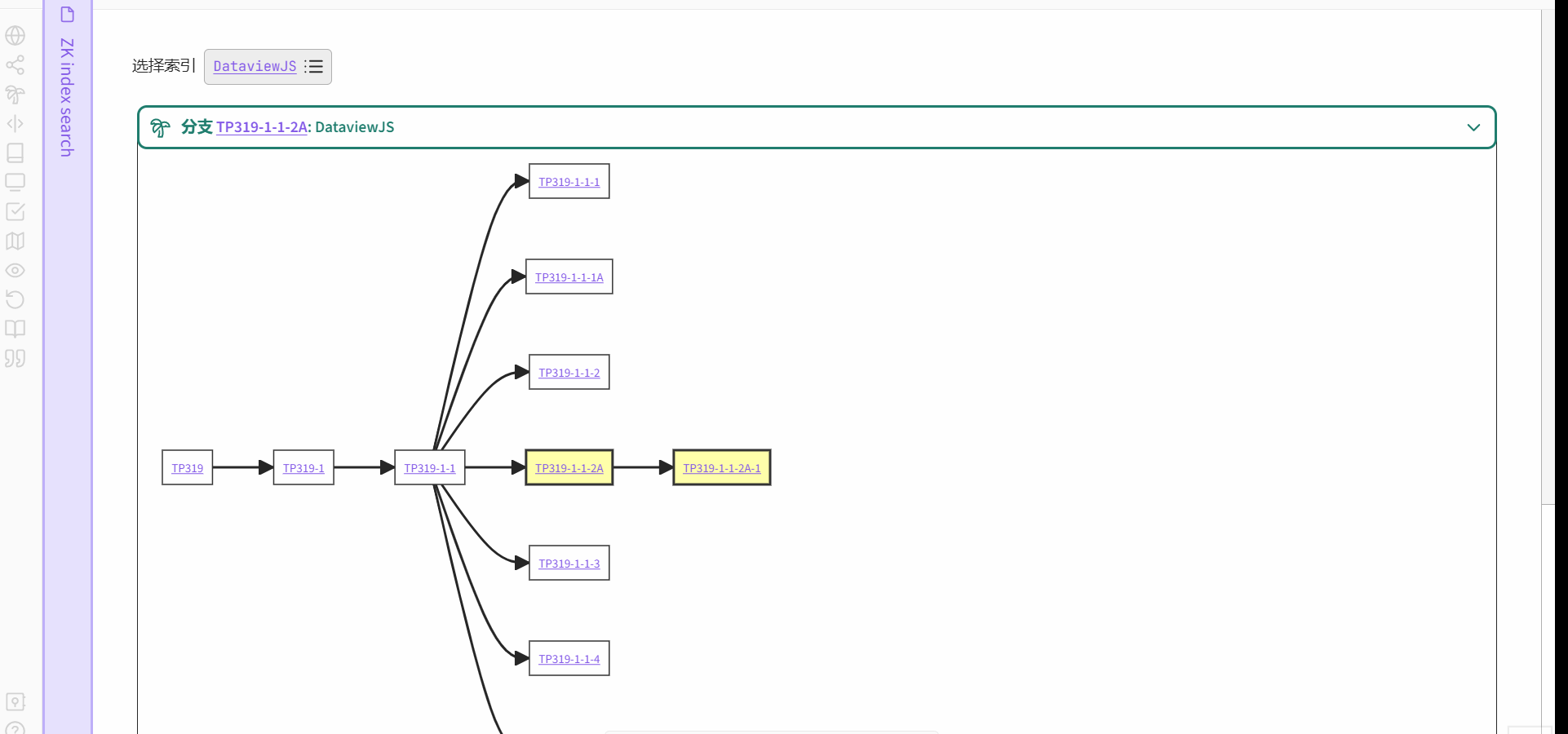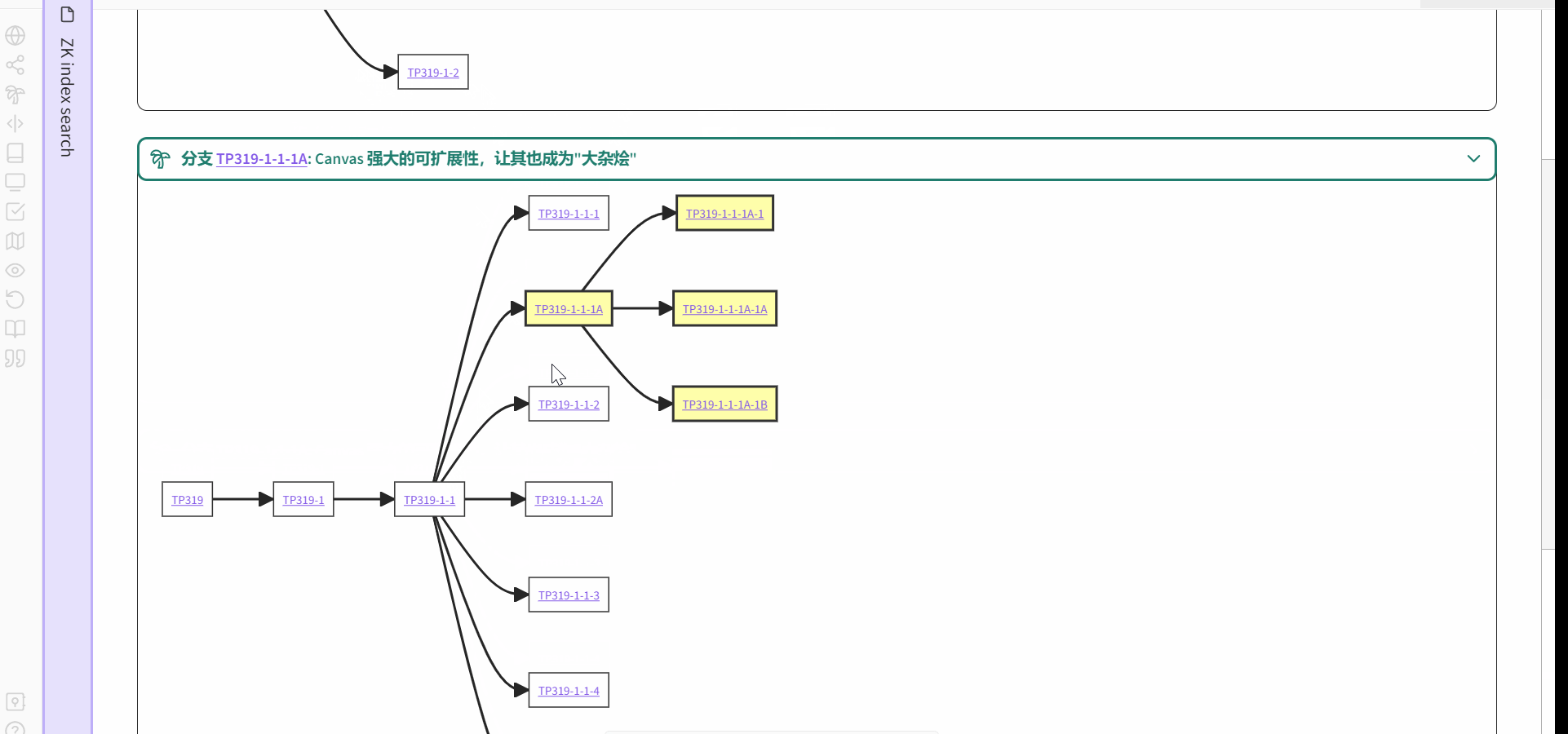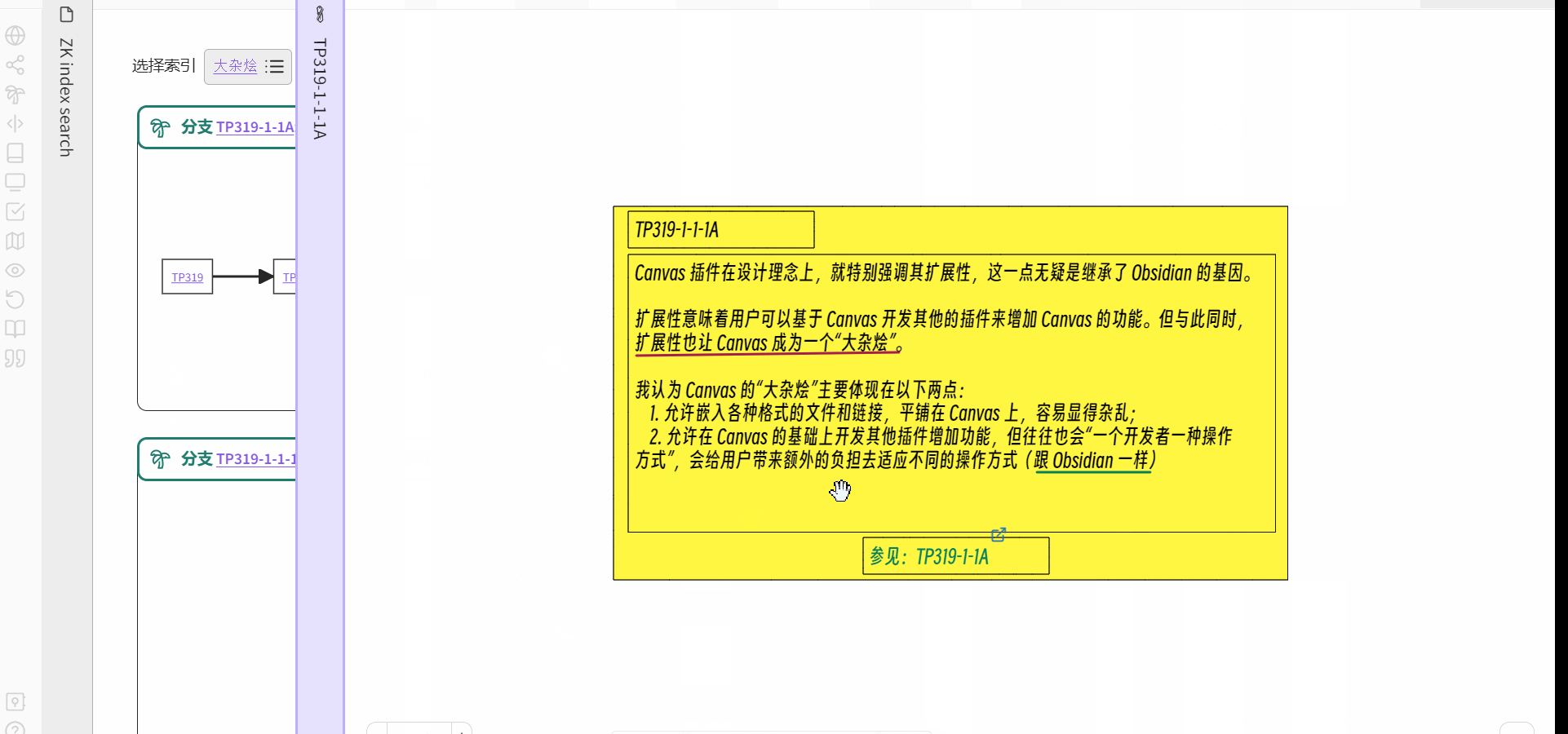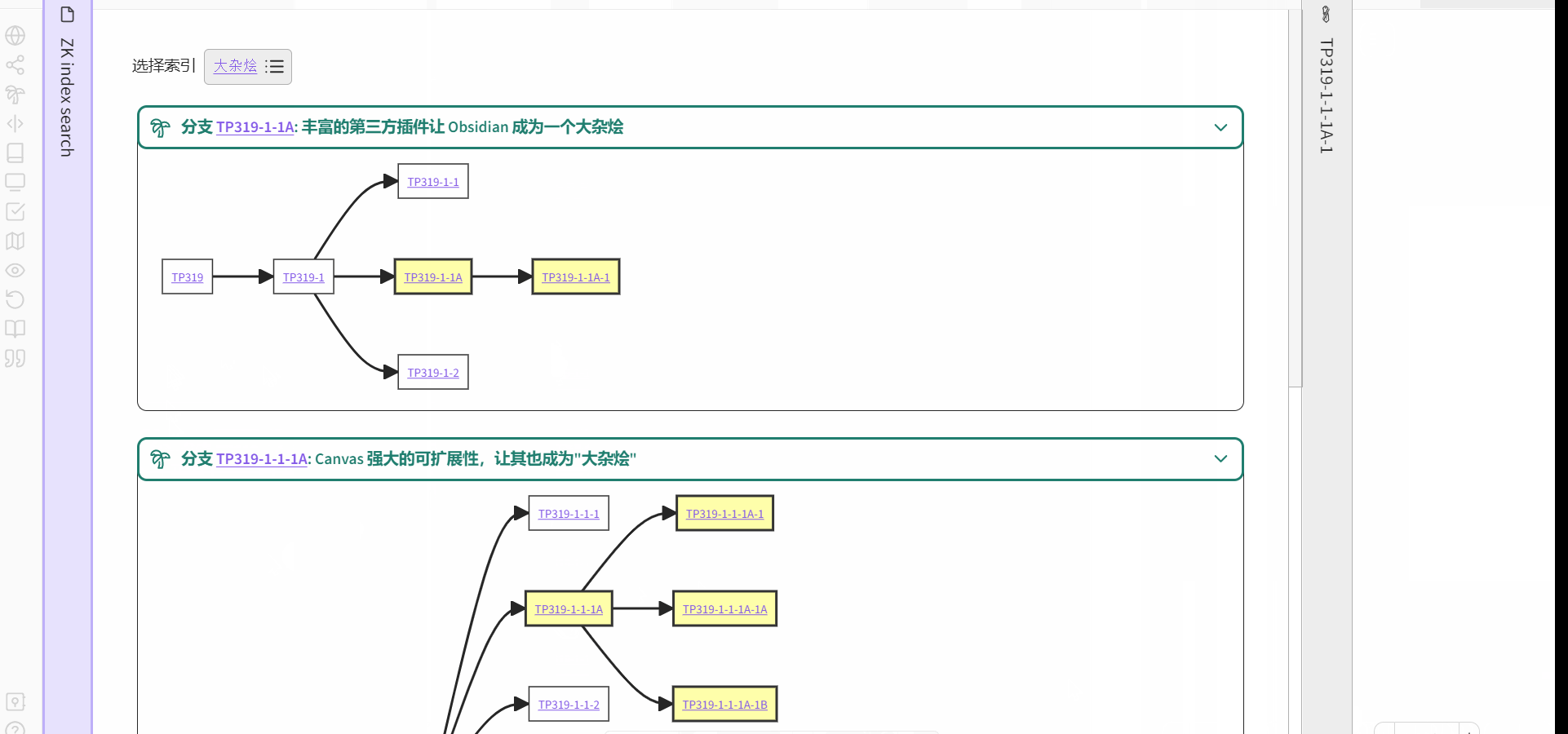
形成一种现在的我与过去的我对话的效果。
说一下我的理解:
- 关键词索引一般是需要自己维护的,我是把所有关键词和相应的链接都放进一个专门的文件里面,不是每个关键词一个文件。
- 不过不同人熟悉的工具不完全相同,这个做法不一定适合所有人。
- 各个关键词按什么顺序排列不太重要,单文件内搜索对电子笔记不是什么难事(我目前不认为卢曼索引的字母顺序有查找便捷性以外的意义)。
- 这里可能要考虑避免链接内容对关键词搜索的干扰。我几乎所有链接的格式都只是字母数字组合(特殊的时间戳),因此不会遇到这种问题。
- 每个关键词后面写的链接不建议多,卢曼大多数时候是只有一个,虽然偶尔也会多一些。参见他的 一代卡片盒索引(可以往后翻页)。我自己的习惯是全都只有一个。
- 如果与某关键词相关的笔记有多条,建议通过笔记间链接来体现(除非它们已经在同一串笔记序列里)。关键词直接指向的这条笔记(或紧随其后的笔记)上面可以有比较多的链接。(当然这点在你演示的这张动图里应该是已经有体现了。)
1 个赞
- 关键词尽量只有1个链接(分支入口),其他相关笔记通过链接来体现——这一点很有启发。
- 我之前有想到过,如果有多个分支链接到索引关键词,当查询关键词的时候,获得多个分支,不同分支笔记之间的关系不清晰,要使用时还需要额外的时间重新梳理。你这个建议我觉得很有帮助,谢谢~
我现在除了不是用纸笔手写笔记之外,基本上复刻了纸质卡片盒的做法:
- 文献笔记(一本书建一个笔记文件,读到有感兴趣的观点就往里面加一条笔记,标记原文位置(链接),供将来查阅)
- 主笔记(一个想法建一个笔记文件,用excalidraw文件模拟纸质卡片,通过大小限制,强迫用自己的语言来表述)
- 索引卡(每个关键词单独建一个笔记文件,内容只放分支入口的笔记链接)
在这3类笔记的基础上,借助Obsidian提供的其他功能/插件,做了几个面板来查询(通过笔记编号,通过索引关键词),并动态生成相应的树状结构视觉化。
有很多体会都是在实践的过程中才能理解,包括笔记的编码作用,每个主笔记内容限制大小的好处,关键词索引卡与标签的区别等等。
发这个主贴的收获远超我的预期,解答了我很多的困惑,也纠正了我一些理解上的偏差。谢谢你和前面其他网友的分享 ![]()
![]()
1 个赞
大佬,看到个卢曼卡片命名的插件,这个有帮助吗? GitHub - Dyldog/luhman-obsidian-plugin
每个人实践Zettelkasten都会带有自己的一些习惯,有些人用纸笔也可以做得很好。结合自己对Zettelkasten的理解选择合适的工具就行。
也可以先不用纠结自动化(插件),用 Obsidian 的基础功能也没差多少。笔记命名你手敲也占不了多少时间。
不知道我是否可以简单粗糙理解为,第二代卡片盒里的卡片更加原子化了,更加独立,面对一个较长概念(如第一代中的12.5f、12.5f1、12.5f2、12.5f3)时,不再选择一直延伸,而是想办法作为一个单独的卡片,这样以便灵活调取。而这种原子化在子分支特别长时,有时候会考虑到与父节点的关系,而直接采用插入的方式使其能更好的被调用(这就是三字母的功能)
你好,dataview插件更新后,Index Search中的关系图不显示了,能分享一下最新的示例库吗?谢谢!
我自己也找到一个卡片盒笔记法的整理方法,没有图片的形式.
谢谢你们的评论,这给我带来了很多启发
谢谢大家的讨论,我收获了很多!
21/3D8 为例。根据你的结论,21/3D8的21/3D8a 应该是21/3D8的字节点,21/3D8aa 是 21/3D8a 的延续, 请问21/3D8 本身的延续是什么呢?
字母分支,数字延续,会遇到一些问题:
例如
3d
3da 分支
3d1 延续
3da
3daa 分支
3da1 延续
3d1
3d1a 分支
3d11??延续,此时会与 3d1 的 3d11 不是重复了吗???
不确定我有没有理解你的问题。
连续数字用分隔符就可以:
3d1 的延续 3d1/1
3d1/1 的延续 3d1/1/1
3d11 的延续 3d11/1
3d1/1/1 与3d11/1是不同的节点
就我用数字字母编号实践ZK的这1年多的体会,字母延续还是数字延续,字母分支还是数字分支,没有什么影响。在不同分支里,按当时已有的节点来决定就可以。
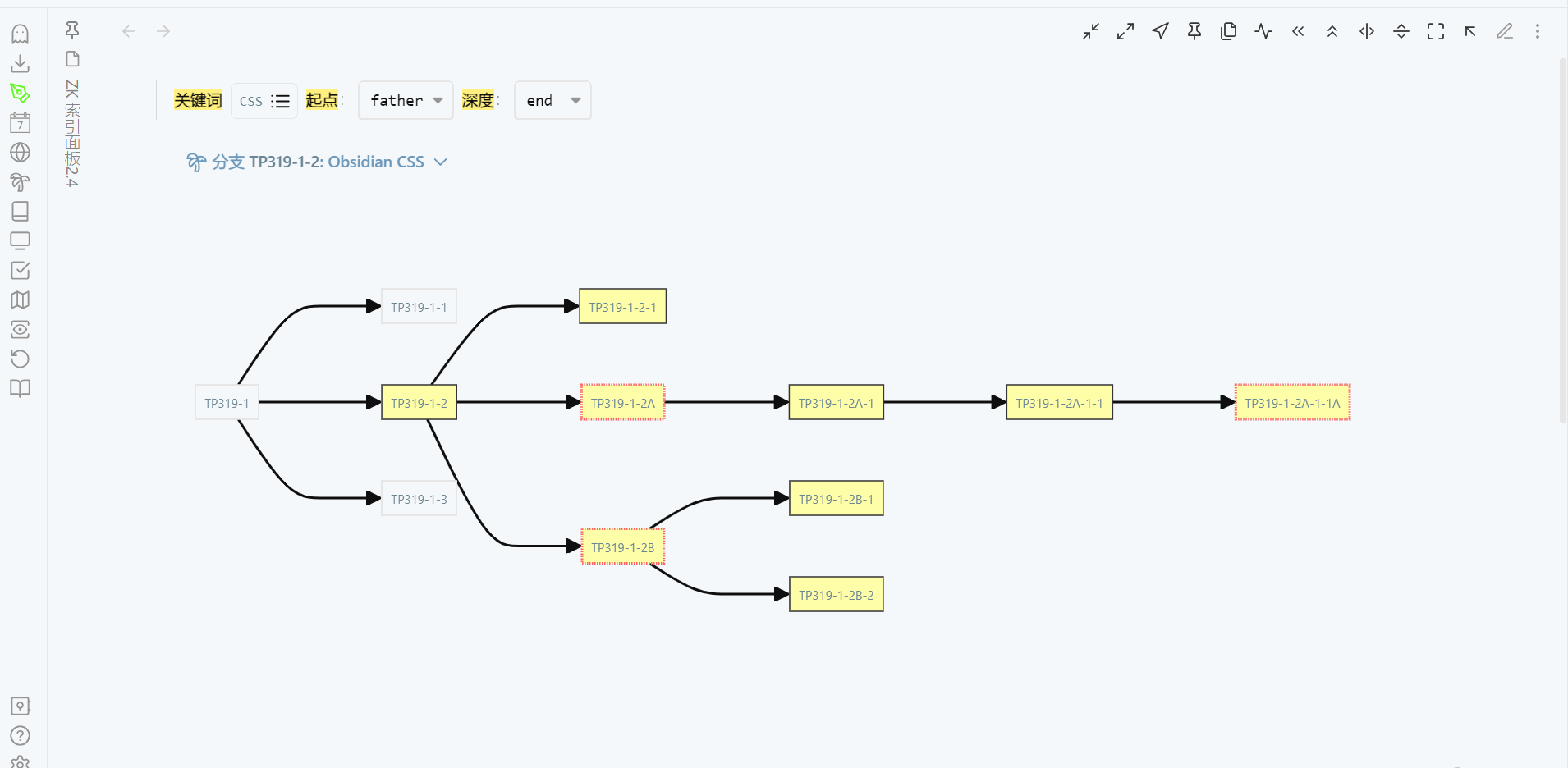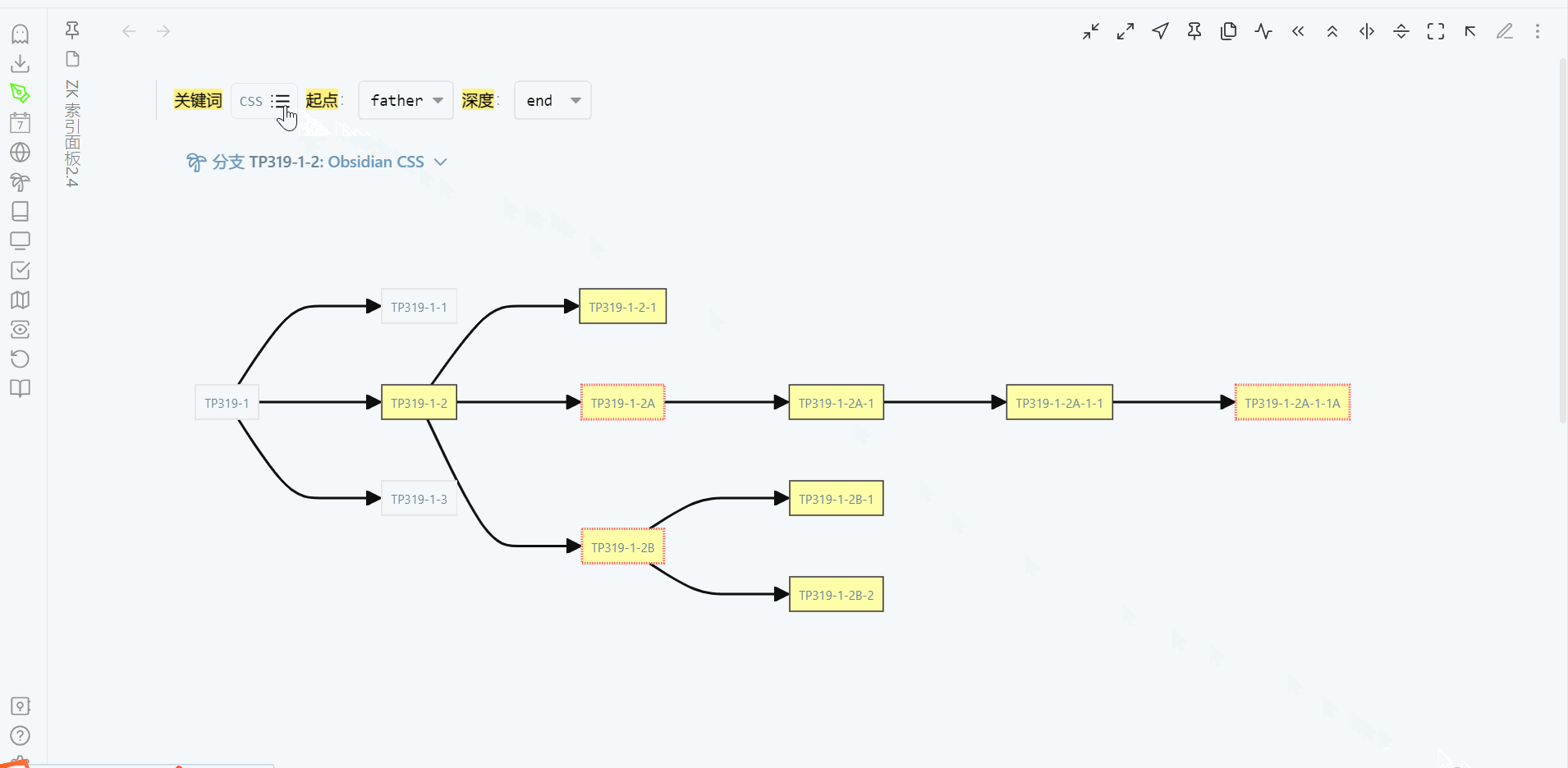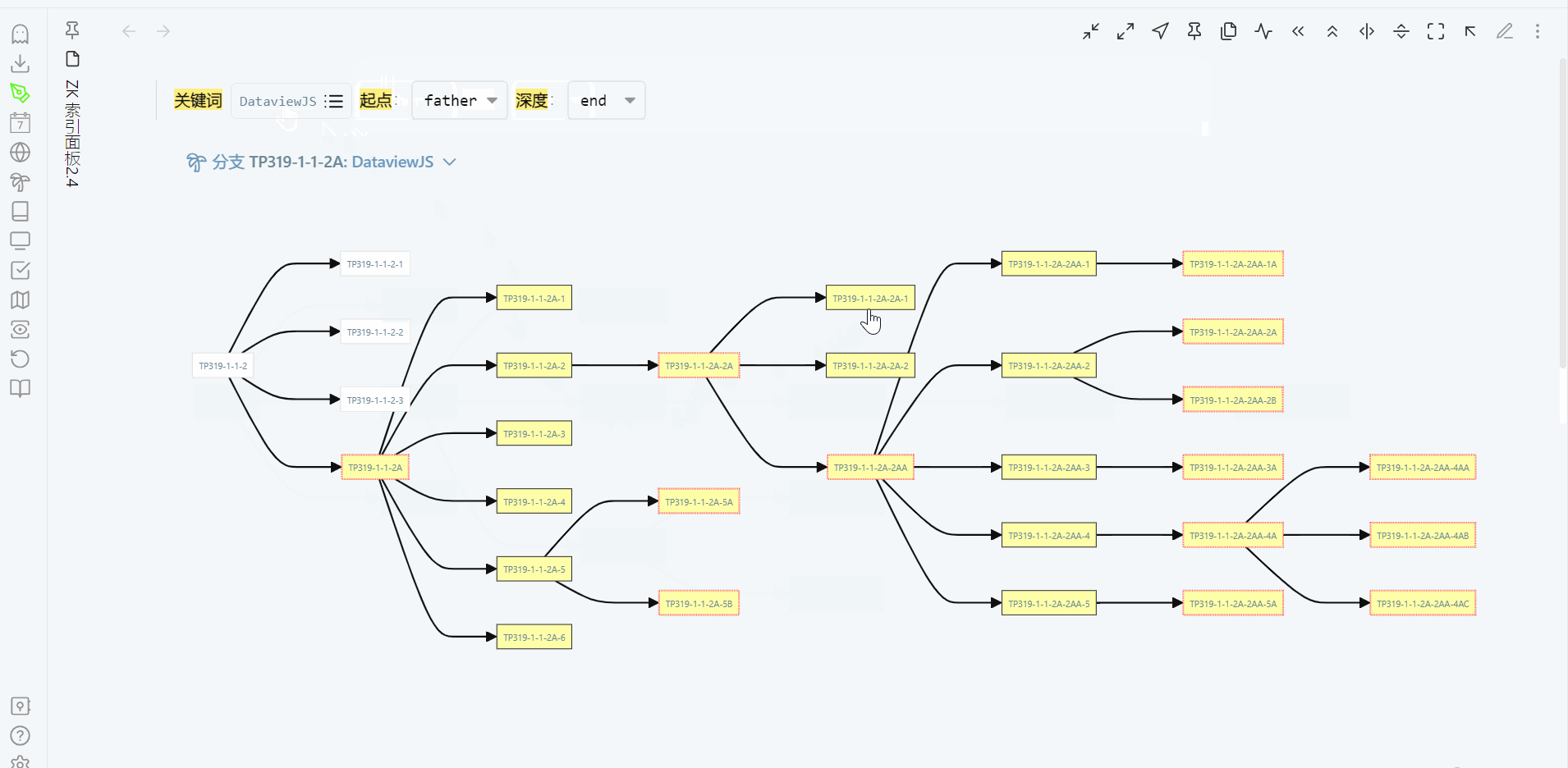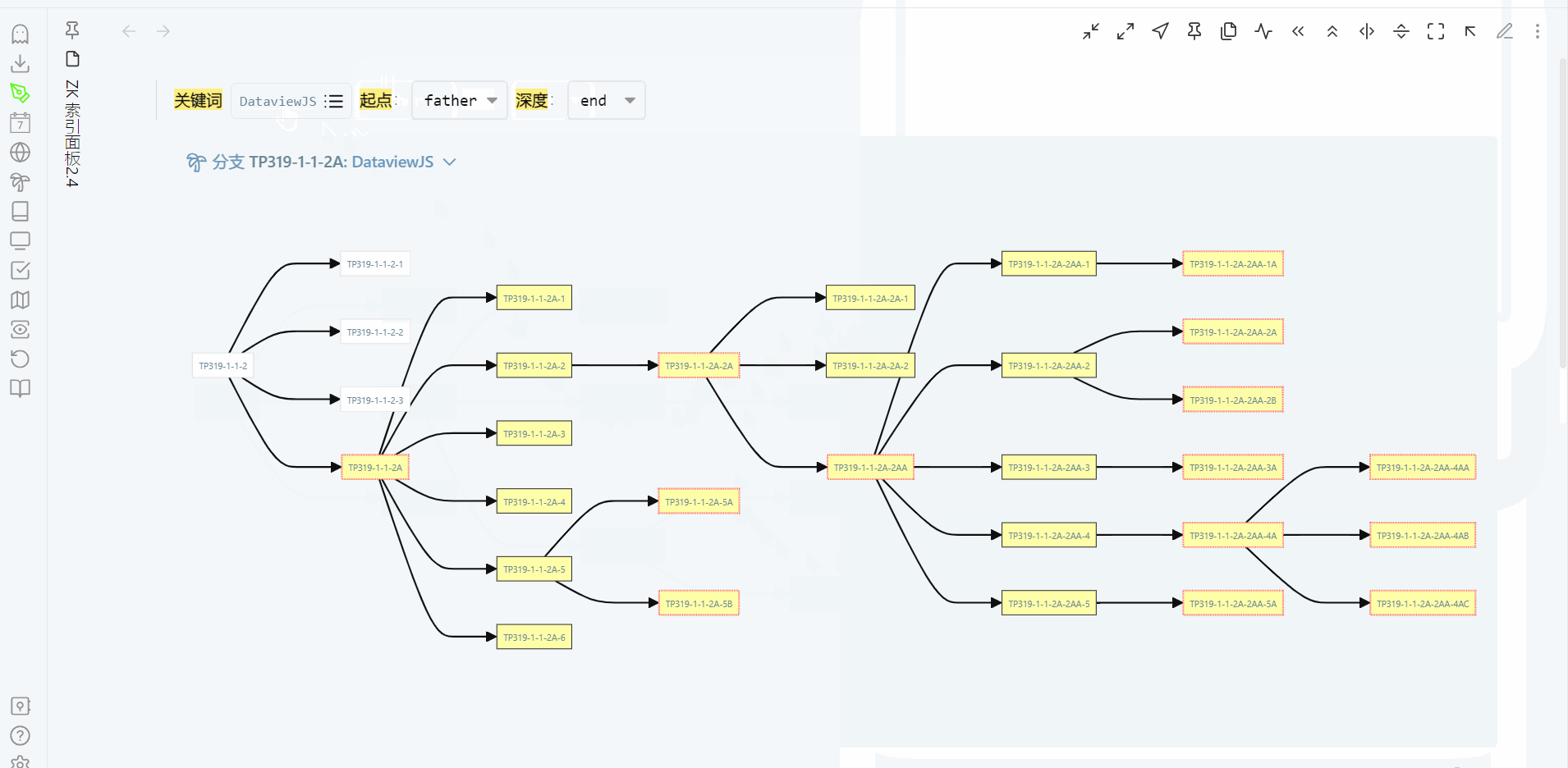
通过关键词来展示分支,当分支的树形结构出现时,就很容易回忆起整个分支的生长过程。这时,只要知道要找的笔记在分支的大概位置就行,沿着分支一定可以找到它。我现在更多是通过每次检索时对该分支的回忆,来记住这个分支。笔记编号只有在创建一个新笔记,才会看看目标分支已有哪些编号,再来决定这个新笔记用什么编号。
太专业了,如果能够用面包屑插件,那样父子兄弟关系展示,然后用你这个mermaid图将会很好,用数字编码,个人不是太习惯,但还是感谢您
Breadcrumbs 没有用过,据我了解,它是在metadata中通过不同的字段来标记前后左右的关系。这种方式从标记父子,手足关系的角度,我觉得它不及卢曼ID来得简洁和优雅。
虽然不够优雅,但是可不可以考虑支持这种方式呢?这样会大大降低使用的门槛。 ![]()