遇到的问题
我用obsidian 记录自己每天的事项;
建立一个文件,称之为”NOTE“,每天用模板插入”Note模板“,”Note模板“里用dataveiw 的 inline开式插入需要的field,整个形式如下:
2023-02-13 星期一 // ”Note模板“的标题;以日期为标题;
[日期::];[A::];[B::];[C::];// 每天需要记录的;
2023-02-12 星期天
[日期::];[A::];[B::];[C::];
2023-02-11 星期六
[日期::];[A::];[B::];[C::];
即所有的field在同一个文件"NOTE"里。
预期的效果
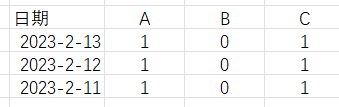
我要通过dataview形成一个表格:
已尝试的解决方案
TABLE without ID 日期, A,B,C
FROM “NOTE”
得到的查询结果是一个列表,日期与内容不对应。
请问应如何修改以下的查询代码?
谢谢!
洛森
2
来自 关于日记自定义日期文件名、代办任务排序、内容聚合等问题 - 疑问解答 - Obsidian 中文论坛 的解决方案
在dailynotes文件夹里,按标题统计,和你的需求不完全一致,不过应该也能达到目的吧
```dataviewjs
let files = dv.pages(`"DailyNotes"`)
HeaderAggregation(files,['标题1','标题2'])
async function HeaderAggregation(files,headers) {
let d = await Promise.all(files.map(async function(file) {
let contents = []
for(let i in headers) {
let content = await app.vault.readRaw(file.file.path)
let header = content.match(/^#+ .*$/mg)
if(!header) return
header = header.map(p=>[p.split(' ')[0].length,p.slice(p.split(' ')[0].length+1)])
content = content.split(/^#+ /m)
let index = header.indexOf(header.find(p=>p[1]==headers[i]))
if(index==-1) continue
let num = []
for(let j =index+1;header[j]&&header[j][0]>header[index][0];j++) num.push(header[j]);
let c = content.find(p=>p.startsWith(headers[i]))
for(let j=0;header[index+1+j] && j<num.length;j++)
c+='#'.repeat(header[index+1+j][0])+' '+content.find(p=>p.startsWith(header[index+1+j][1]))
contents.push(c?.slice(headers[i].length)??'')
}
if(contents.every(p=>p.replace(/\s+/,'')=='')) return
return [file.file.link,...contents]
}))
d=d.filter(p=>p)
dv.table(['标题',...headers],d)
}
1 个赞
谢谢你的回复。
我对js不懂,我把代码复制过去,改了关键字,不能实现我所需要的。
我想要是能用sql语句形式能实现,就更好了。我结合了论坛其他的回答,把查询语句改成以下:
TABLE without ID 日期, A,B, C
FROM “NOTE”
flatten 日期
group by 日期
但A,B,C内容不显示;
洛森
4
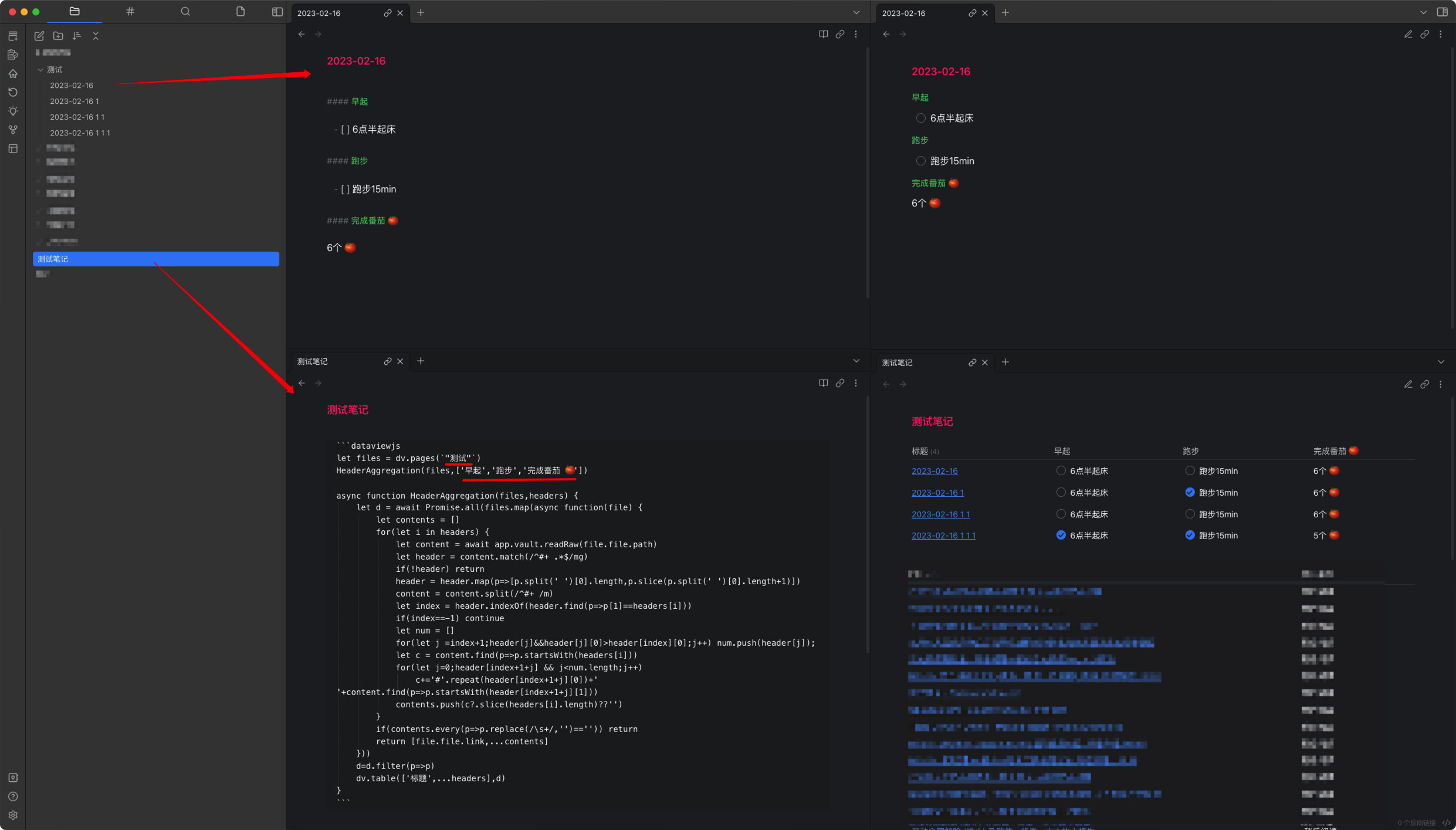
我也不太懂代码,根据大神的内容调试后可以用,你仔细看下图,和你的输入规则需求不一样,但可以达到统计不同标题下内容的目的
非常感谢你的回复;
我发现你的文件与我的文件主要区别在:
你的header名称是固定,而我的header名称是不固定;
我再仔细看看代码;