railcn
2022 年12 月 18 日 02:06
1
首先感谢官方开发这么好玩、好用的产品,也感谢ob群的兄弟们。
在转战有道、为知、印象数年后,最终还是入坑Obsidian了。
#问题1 :
#问题2 :
```dataviewjs
// 修改其中的标签 todo 以及修改 LOLOLO
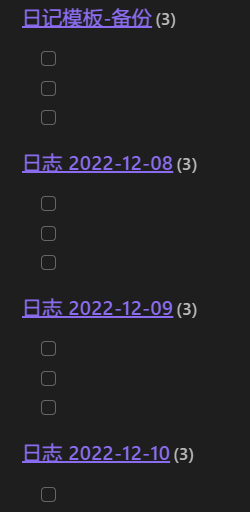
dv.taskList(
dv.pages("").where(t => { return t.file.name != "日记模板-备份" }).file.tasks
.where(t => t.text.includes("") ),1)
想用以上代码实现聚合所有日记中的代办任务,已经实现上图效果,
#问题3 :
重要事项:
#重要事项
今日感悟:
#今日感悟
需要改进:
#需要改进
非常感谢各位大佬!
1 个赞
c11
2022 年12 月 18 日 05:35
3
同蹲问题3
应该是用dataview ,但我不太会用
#问题2 :
```dataviewjs
dv.taskList(
dv.pages().where(t => { return t.file.name != "日记模板-备份" }).sort(p=>p.file.name,'desc').file.tasks
.where(t => t.text.includes("") ),1)
```
#问题3 :
刚好整理完善了一个标题聚合的功能
```dataviewjs
let files = dv.pages(`"文件夹"`).filter(p=>moment(Number(p.file.ctime.ts))>moment().subtract(7, 'days');).sort(p=>p.file.name)
await HeaderAggregation(files,['重要事项:','今日感悟:'])
async function HeaderAggregation(files,headers) {
files.map(async function(file) {
let contents = []
for(let i in headers) {
let content = await app.vault.readRaw(file.file.path)
content = content.split(/#+ /).find(p=>p.startsWith(headers[i]))
contents.push(content.slice(headers[i].length))
}
if(contents.every(p=>p.replace(/\s+/,'')=='')) return
dv.header(2,file.file.name)
contents.map((p,i)=> {
if(p.replace(/\s+/,'')=='') return
dv.header(3,headers[i])
dv.paragraph(p)
})
})
}
```
1 个赞
好像不小心多打了一个分号
```dataviewjs
let files = dv.pages(`"文件夹"`).filter(p=>moment(Number(p.file.ctime.ts))>moment().subtract(7, 'days')).sort(p=>p.file.name)
await HeaderAggregation(files,['重要事项:','今日感悟:'])
async function HeaderAggregation(files,headers) {
files.map(async function(file) {
let contents = []
for(let i in headers) {
let content = await app.vault.readRaw(file.file.path)
content = content.split(/#+ /).find(p=>p.startsWith(headers[i]))
contents.push(content?.slice(headers[i].length)??'')
}
if(contents.every(p=>p.replace(/\s+/,'')=='')) return
dv.header(2,file.file.name)
contents.map((p,i)=> {
if(p.replace(/\s+/,'')=='') return
dv.header(3,headers[i])
dv.paragraph(p)
})
})
}
```
3 个赞
railcn
2022 年12 月 18 日 11:00
7
大佬牛逼,膜拜。
修改后确实可以了。
有两个小问题:
非常感谢
想倒序在第 sort 函数的二个参数填 desc 就可以了.sort(p=>p.file.name,'desc')
只筛选 task 就麻烦多了,里面的内容得重新写一遍,而不能用已经得到的内容进行加工,因为用 dv.taskList 是可以在代码生成的页面反向修改原始内容的,直接提取的话页面是写死的,相当于是少了很多功能
```dataviewjs
let files = dv.pages(`"600-日常"`).sort(p=>p.file.name)
HeaderAggregation(files,['日程安排'])
function HeaderAggregation(files,headers) {
files.map(function(file) {
let tasks = file.file.tasks.filter(p=>!p.completed).groupBy(p=>p.header.subpath)
if(headers.map(p=>tasks.find(q=>q.key==p)?.rows.length??0).some(p=>p>0)) {
dv.header(2,file.file.path)
headers.map(p=> {
if(!tasks.find(q=>q.key==p)?.rows) return
dv.header(3,p)
dv.taskList(tasks.find(q=>q.key==p).rows)
})
}
})
}
```
Naraku
2022 年12 月 19 日 08:07
10
请教下大佬,我和楼主同样的问题三。我是想要汇总日记文件下每篇日记的 二级标题:感悟和思考。但用你的这个代码后还是报错,想问下是什么原因:
Evaluation Error: Error: Failed to parse query in 'pagePaths': Error:
-- PARSING FAILED --------------------------------------------------
Got the end of the input
Expected:
string
at DataviewApi.pagePaths (plugin:dataview:19957:19)
at DataviewApi.pages (plugin:dataview:19979:21)
at DataviewInlineApi.pages (plugin:dataview:19444:25)
at eval (eval at <anonymous> (plugin:dataview), <anonymous>:1:69)
at eval (eval at <anonymous> (plugin:dataview), <anonymous>:21:4)
at DataviewInlineApi.eval (plugin:dataview:19673:16)
at evalInContext (plugin:dataview:19674:7)
at asyncEvalInContext (plugin:dataview:19681:16)
at DataviewJSRenderer.render (plugin:dataview:19705:19)
at DataviewRefreshableRenderer.maybeRefresh (plugin:dataview:19283:22)
第一个,desc 应该是有效的,不知道你是怎么写的
Naraku
2022 年12 月 19 日 09:40
13
我就是修改了 dv.pages("文件夹") 里面的文件夹路径为我自己的路径,然后
await HeaderAggregation(files,['重要事项:','今日感悟:'])
这里换成了我自己的标题。改成了
await HeaderAggregation(files,['感悟与思考'])
这样的,就会报错。
```dataview
table
L.text as 感悟和思考,
L.link as 链接
from "30-Life/每日笔记"
flatten file.lists as L
where
!L.parent and
meta(L.section).subpath = "感悟和思考" and
dateformat(date(file.link), "yyyy-'W'WW") = this.file.name
这样是没问题的
那挺好,我就是好奇这个报错是怎么来的,没见过这个报错
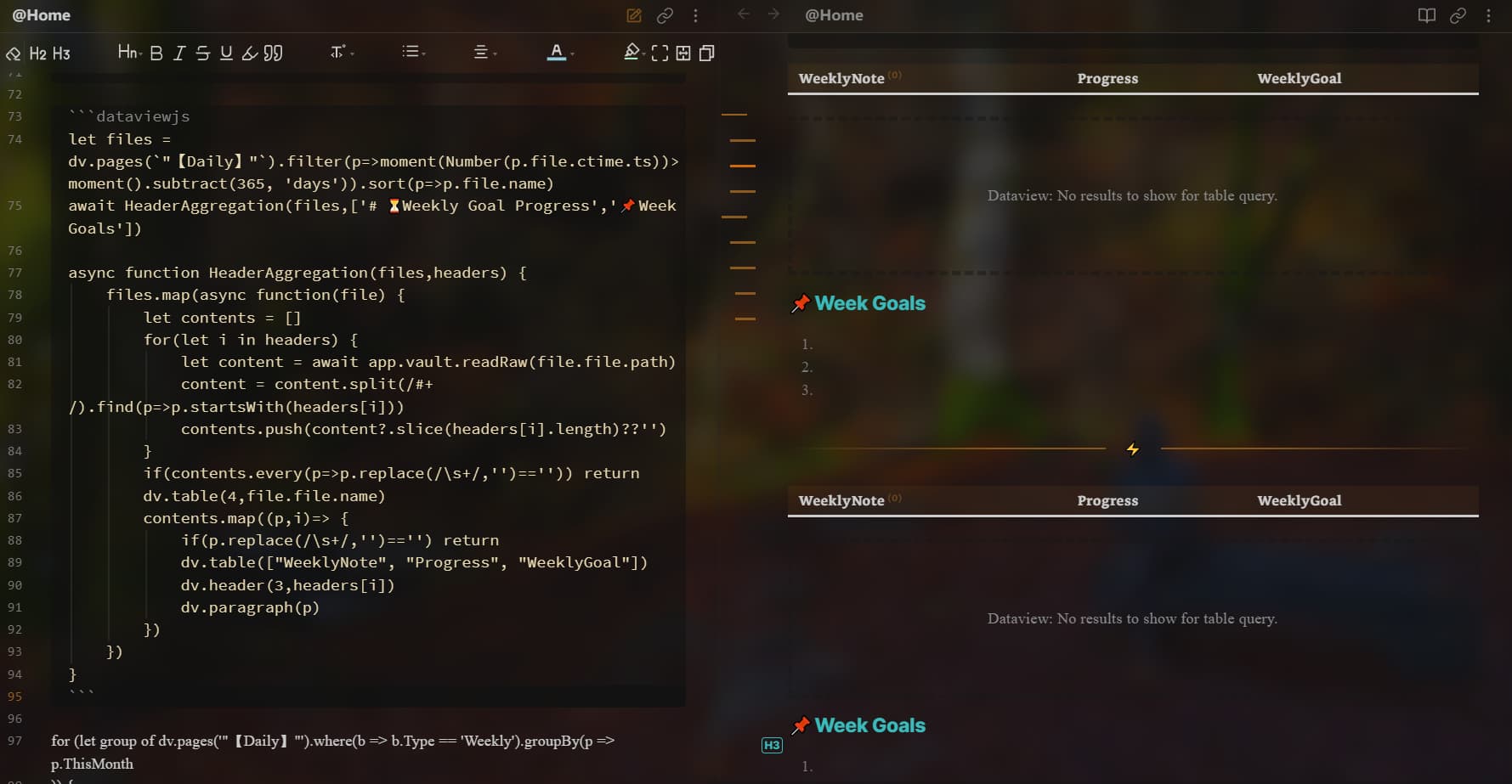
感谢大佬!正好需要!不过输出可以改成表格吗?不是很懂代码,尝试修改了几次都还没达到效果,请问方便指导一下怎么修改吗?
```dataviewjs
let files = dv.pages(`"600-日常/日记"`)
HeaderAggregation(files,['日程安排','日常记录'])
async function HeaderAggregation(files,headers) {
let d = await Promise.all(files.map(async function(file) {
let contents = []
for(let i in headers) {
let content = await app.vault.readRaw(file.file.path)
content = content.split(/^#+ /m).find(p=>p.startsWith(headers[i]))
contents.push(content?.slice(headers[i].length)??'')
}
if(contents.every(p=>p.replace(/\s+/,'')=='')) return
return [file.file.link,...contents]
}))
d=d.filter(p=>p)
dv.table(['name',...headers],d)
}
```
1 个赞
潜伏神经元
2023 年1 月 30 日 15:26
18
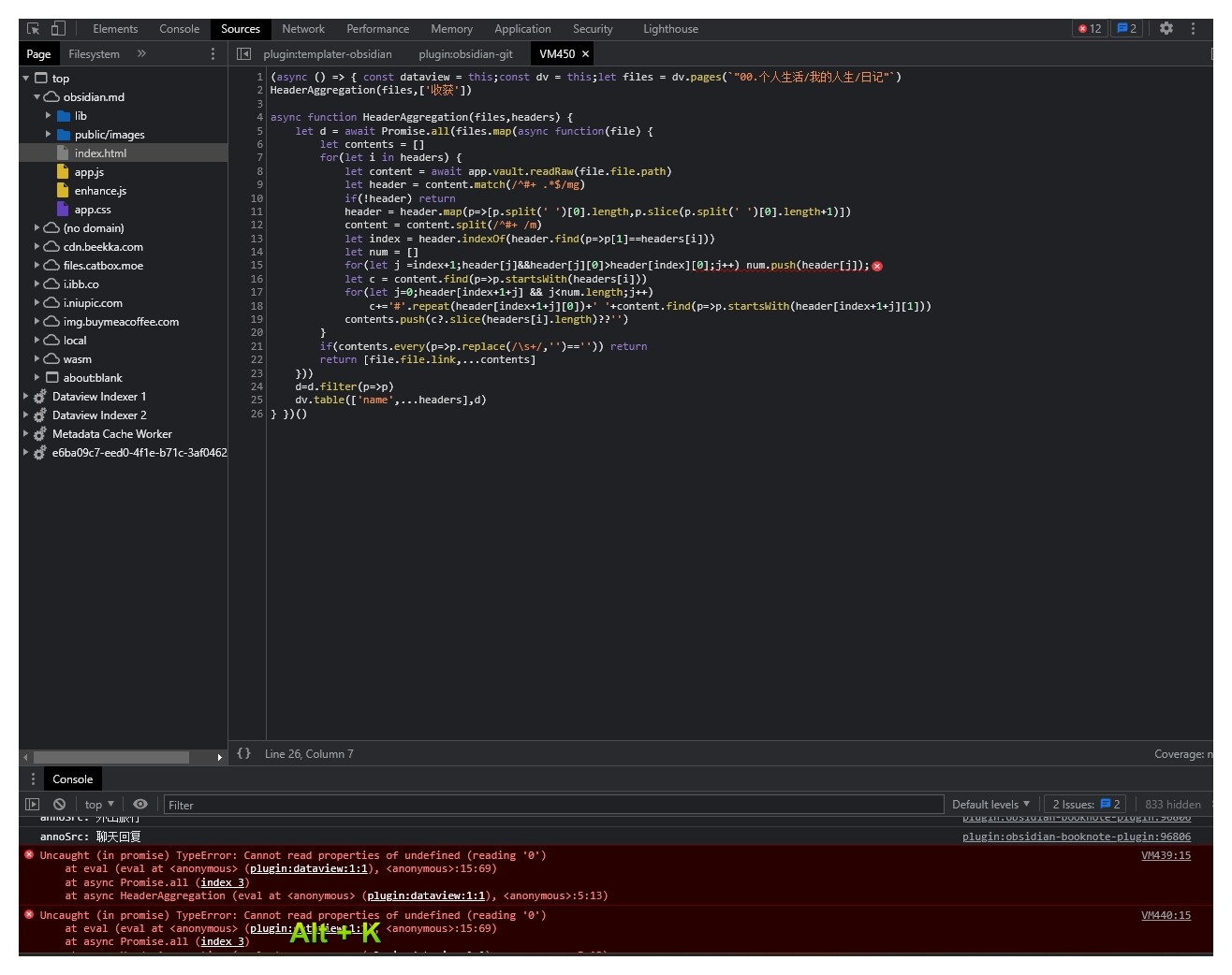
大佬,用了你这段代码发现一个问题
亦即
## 重要事项
### 哈哈
真好笑
### 嘿嘿
悄悄的笑
则上述 二级标题 重要事项 下的内容,都无法提取出来
确实是这样,因为这段代码的逻辑是切分每一个标题,不管它是多少级,这会导致 重要事项 的内容到 哈哈 就停止了
```dataviewjs
let files = dv.pages(`"600-日常/日记"`)
HeaderAggregation(files,['日程安排','日常记录'])
async function HeaderAggregation(files,headers) {
let d = await Promise.all(files.map(async function(file) {
let contents = []
for(let i in headers) {
let content = await app.vault.readRaw(file.file.path)
let header = content.match(/^#+ .*$/mg)
if(!header) return
header = header.map(p=>[p.split(' ')[0].length,p.slice(p.split(' ')[0].length+1)])
content = content.split(/^#+ /m)
let index = header.indexOf(header.find(p=>p[1]==headers[i]))
let num = []
for(let j =index+1;header[j]&&header[j][0]>header[index][0];j++) num.push(header[j]);
let c = content.find(p=>p.startsWith(headers[i]))
for(let j=0;header[index+1+j] && j<num.length;j++)
c+='#'.repeat(header[index+1+j][0])+' '+content.find(p=>p.startsWith(header[index+1+j][1]))
contents.push(c?.slice(headers[i].length)??'')
}
if(contents.every(p=>p.replace(/\s+/,'')=='')) return
return [file.file.link,...contents]
}))
d=d.filter(p=>p)
dv.table(['name',...headers],d)
}
```
潜伏神经元
2023 年1 月 31 日 06:44
20
很奇怪,使用你这段代码,复制进去是正常的,可以看到已经实现了对应的内容(出现了dateview的表头)。600-日常/日记修改为自己的目录,好像就连表头都显示不出来了