Sang
2023 年1 月 27 日 04:59
1
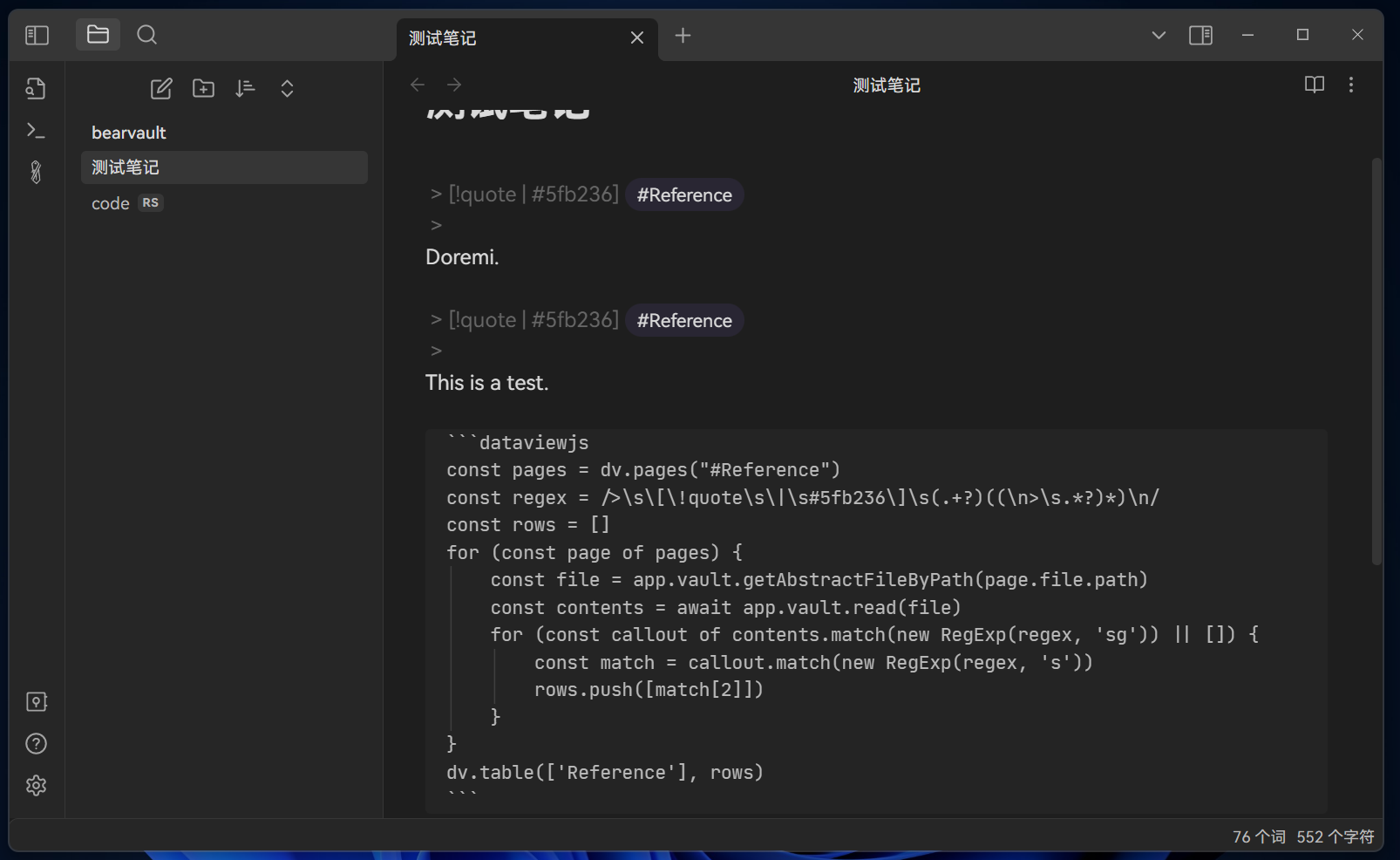
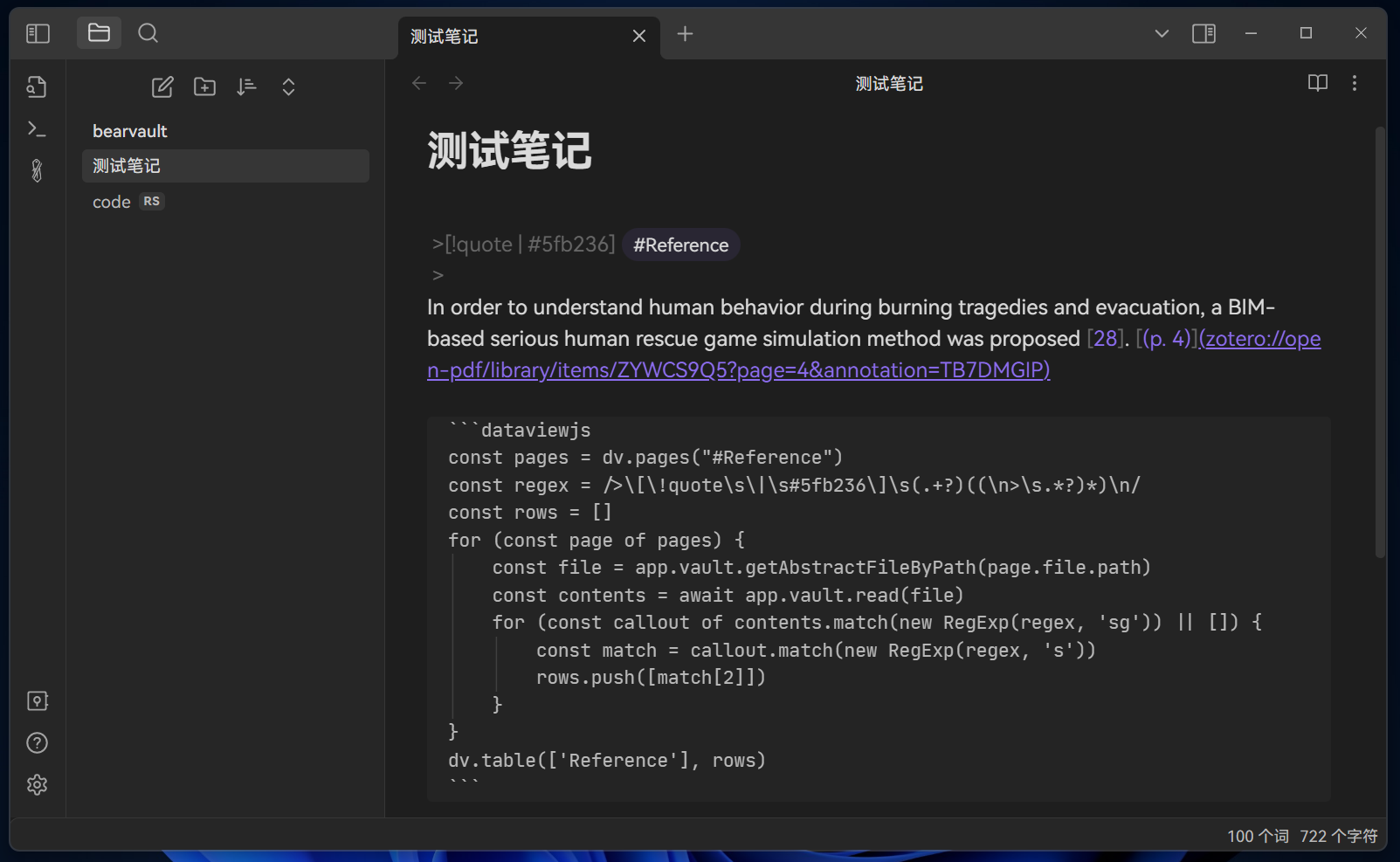
我用Zotero上读论文并且做笔记,通过Zotero integration导入Obsidian。导入的笔记通过模板放入了callout,下面为一个例子
[!quote | #5fb236 ] #Reference
For example, when a building fire occurs, some people choose to escape, others choose to wait for rescue, and others become involved in the firefighting effort. These differential decisions reflect individual characteristics [14,15] (p. 2)
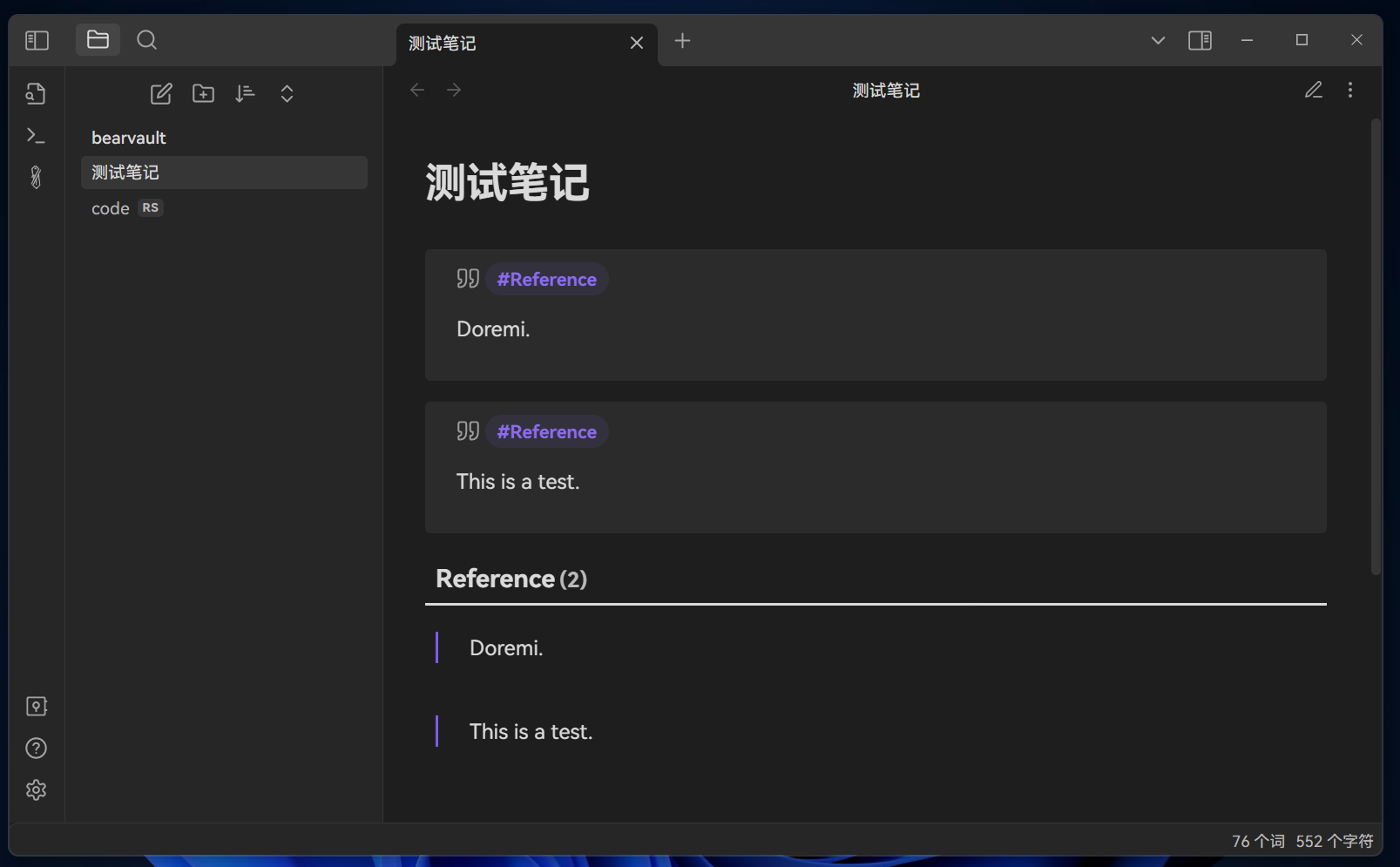
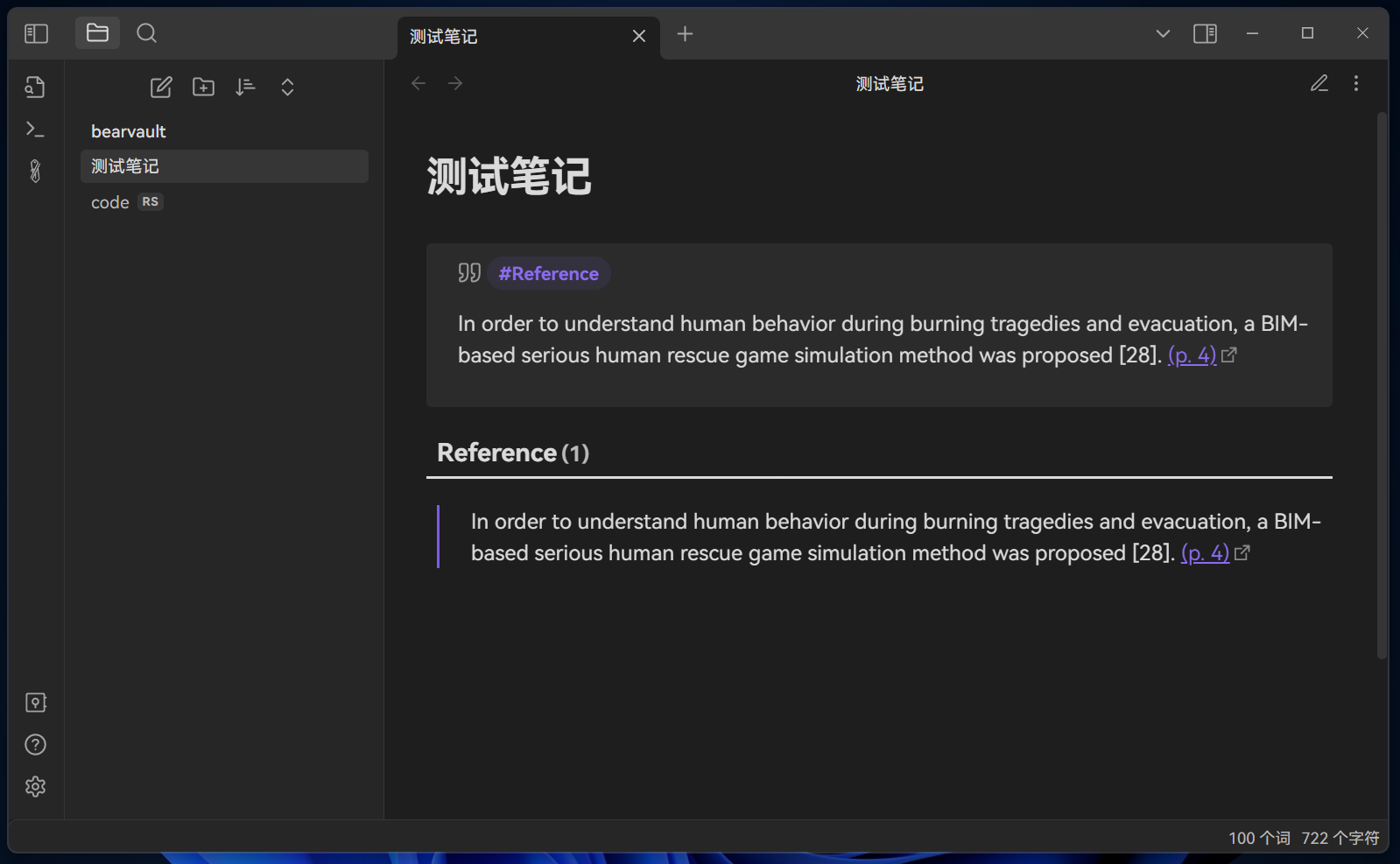
现在我希望将所有带有#Reference的callout通过dataview在表格中展示出来。
尝试过下面帖子里的方法
I tried to see any examples on the internet or the documentation on DataView Plugin, but didn’t found any resource. I’m willing to query specific type of callouts for my weekly routine. Any guidance to to do that would help. Thanks!
Reading time: 2 mins 🕑
Likes: 23 ❤
但是没有效果,我没有js基础也不知道从何下手调整
1 个赞
熊海
2023 年1 月 27 日 06:51
2
下午好!希望这个对您有所帮助!
Callout:
> [!quote | #5fb236] #Reference
> For example, when a building fire occurs, some people choose to escape, others choose to wait for rescue, and others become involved in the firefighting effort. These differential decisions reflect individual characteristics [14,15] (p. 2)
DataView:
```dataviewjs
const pages = dv.pages("#Reference")
const regex = />\s\[\!quote\s\|\s#5fb236\]\s(.+?)((\n>\s.*?)*)\n/
const rows = []
for (const page of pages) {
const file = app.vault.getAbstractFileByPath(page.file.path)
const contents = await app.vault.read(file)
for (const callout of contents.match(new RegExp(regex, 'sg')) || []) {
const match = callout.match(new RegExp(regex, 's'))
rows.push([match[2]])
}
}
dv.table(['Reference'], rows)
```
但是每一个 Callout 结尾都必须要换行,否则就匹配不上。
您可以向我们提供更多信息,以便我们可以为您提供更多针对性的建议。
1 个赞
Sang
2023 年1 月 27 日 11:06
3
非常感谢回复,我试了试没有还是匹配上,仔细看了看我的MD文档发现要索引的部分开头固定这个格式:
> [!quote | #5fb236] #Reference
>
XXXXXXX
每个callout最后都有换行。?) )\n/
熊海
2023 年1 月 27 日 11:19
4
晚上好!它看起来好像可以正常工作,您可以提供更多信息吗?比如一个 Callout 例子(图片 is the best)。
熊海
2023 年1 月 27 日 11:33
7
Yet. 这个报错是 MetaEdit 插件引起的,与 DataView 无关,无需担心。
我想我知道问题所在了。
您可以试试这个:
```dataviewjs
const pages = dv.pages("#Reference")
const regex = />\[\!quote\s\|\s#5fb236\]\s(.+?)((\n>\s.*?)*)\n/
const rows = []
for (const page of pages) {
const file = app.vault.getAbstractFileByPath(page.file.path)
const contents = await app.vault.read(file)
for (const callout of contents.match(new RegExp(regex, 'sg')) || []) {
const match = callout.match(new RegExp(regex, 's'))
rows.push([match[2]])
}
}
dv.table(['Reference'], rows)
```
It works properly.
1 个赞
lool
2023 年3 月 19 日 12:54
12
您好 ,我也有遇到同样的问题
callout 加了标题 (形如 “#案例 ”+" " +“正式的标题(包含若干中英文和符号,都是半角)”
callout 有的是open,有的是close,即"±"两种都有
我想问一下,如何才能抽取出带有"#案例 " 这样的callout?
期待得到您的帮助
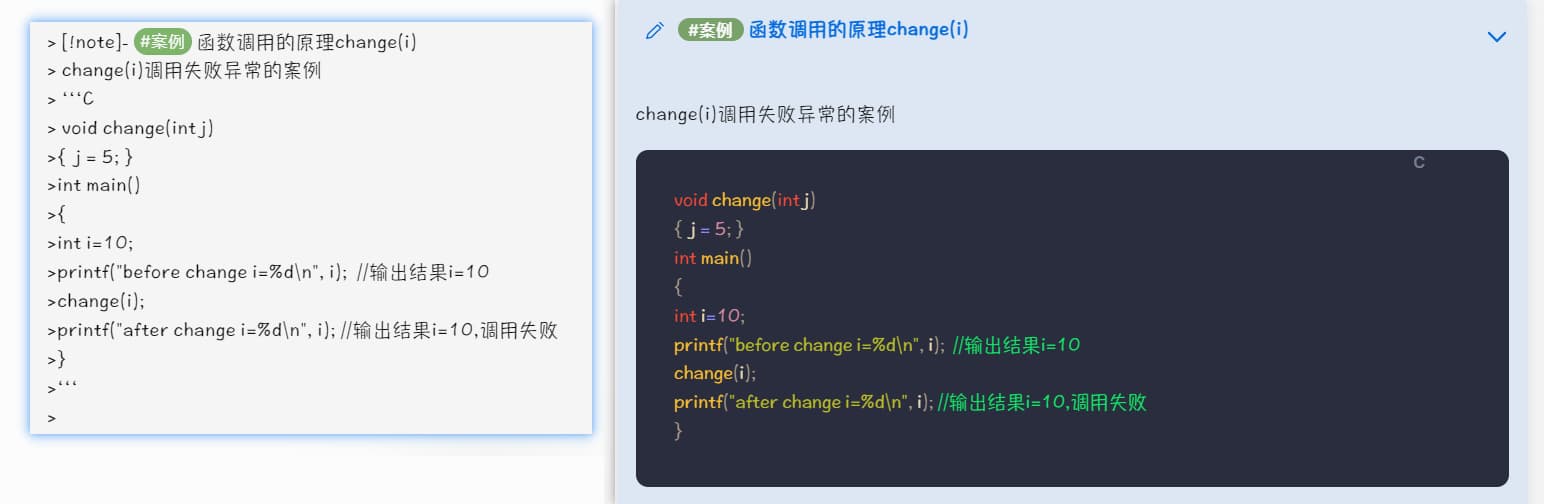
我把源码附上,如果您需要用的话:
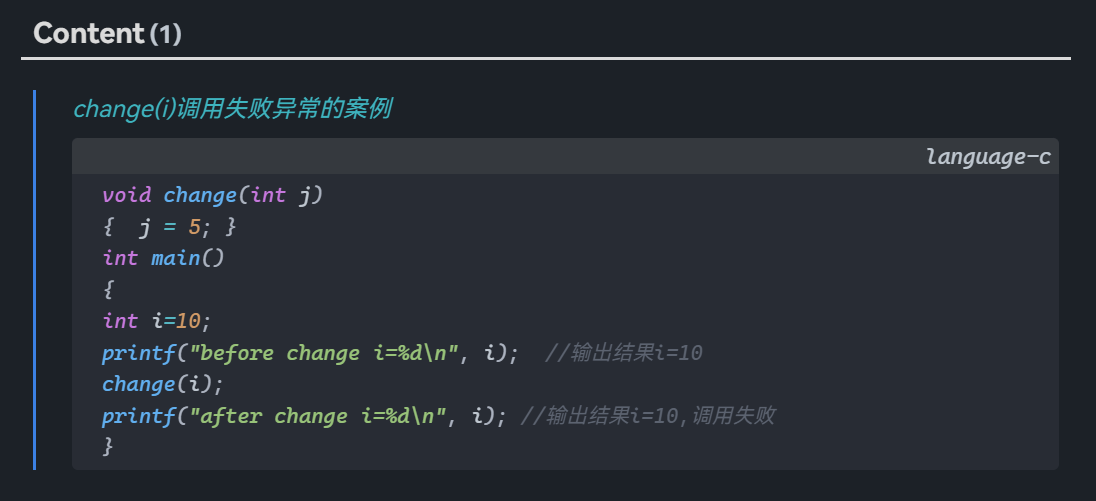
> [!note]- #案例 函数调用的原理change(i)
> change(i)调用失败异常的案例
> ```C
> void change(int j)
>{ j = 5; }
>int main()
>{
>int i=10;
>printf("before change i=%d\n", i); //输出结果i=10
>change(i);
>printf("after change i=%d\n", i); //输出结果i=10,调用失败
>}
>```
>
熊海
2023 年3 月 19 日 18:11
13
晚上好!欢迎加入 Obsidian 中文社区!希望这个对您有所帮助!
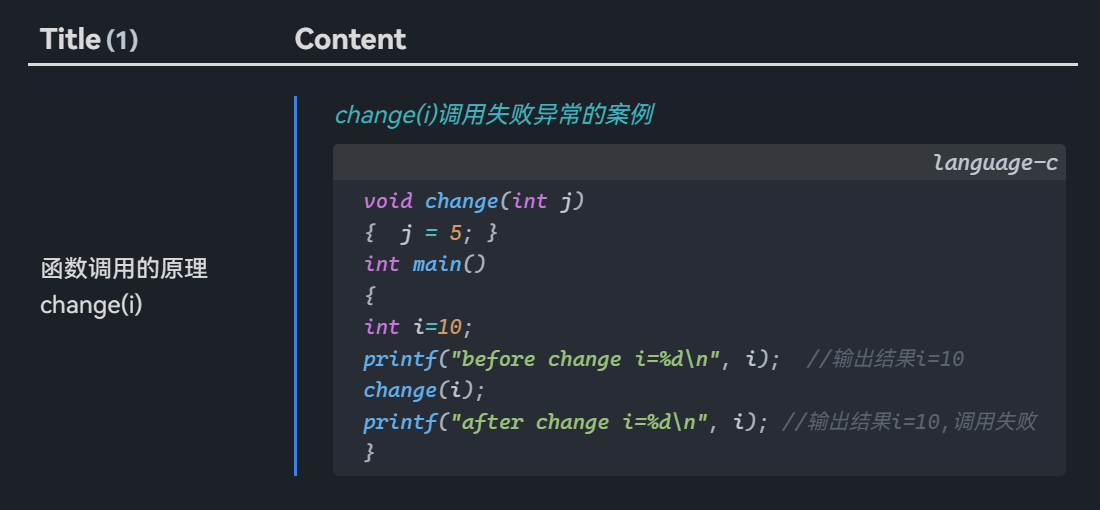
```dataviewjs
const pages = dv.pages("#案例")
const regex = />\s\[\!note\][+|-]\s\#案例\s(.+?)((\n>.*?)*)\n/
const rows = []
for (const page of pages) {
const file = app.vault.getAbstractFileByPath(page.file.path)
const contents = await app.vault.read(file)
for (const callout of contents.match(new RegExp(regex, 'sg')) || []) {
const match = callout.match(new RegExp(regex, 's'))
rows.push([match[1], match[2]])
}
}
dv.table(['Title', 'Content'], rows)
```
It works belike:
如果您不希望展示 callout 的标题,可以尝试这个:
```dataviewjs
const pages = dv.pages("#案例")
const regex = />\s\[\!note\][+|-]\s\#案例\s(.+?)((\n>.*?)*)\n/
const rows = []
for (const page of pages) {
const file = app.vault.getAbstractFileByPath(page.file.path)
const contents = await app.vault.read(file)
for (const callout of contents.match(new RegExp(regex, 'sg')) || []) {
const match = callout.match(new RegExp(regex, 's'))
rows.push([match[2]])
}
}
dv.table(['Content'], rows)
```
It works belike:
您可以向我们提供更多信息,以便我们可以为您提供更多针对性的建议。
敬祝生活愉快 ~
3 个赞
lool
2023 年3 月 20 日 14:48
14
感谢大佬!
胡不缺
2023 年6 月 28 日 00:28
15
熊海
2023 年6 月 28 日 18:59
16
晚上好! 请问您的要求是通过 Dataview 抽取仓库里面所有文件中带有以下固定模式的 callout 内容吗?
> [!note] 思维发散【待抽取的标题】
> 待抽取的笔记
您可以使用正则表达式, 希望这个对您有所帮助!
```dataviewjs
const pages = dv.pages()
const regex = />\s\[\!note\]\s思维发散【(.+?)】((\n>.*?)*)\n/
const rows = []
for (const page of pages) {
const file = app.vault.getAbstractFileByPath(page.file.path)
const contents = await app.vault.read(file)
for (const callout of contents.match(new RegExp(regex, "sg")) || []) {
const match = callout.match(new RegExp(regex, "s"))
rows.push([match[1], match[2]])
}
}
dv.table(["Title", "Content"], rows)
```
It works belike:
如果您不希望展示 callout 的标题, 可以尝试这个:
```dataviewjs
const pages = dv.pages()
const regex = />\s\[\!note\]\s思维发散【(.+?)】((\n>.*?)*)\n/
const rows = []
for (const page of pages) {
const file = app.vault.getAbstractFileByPath(page.file.path)
const contents = await app.vault.read(file)
for (const callout of contents.match(new RegExp(regex, "sg")) || []) {
const match = callout.match(new RegExp(regex, "s"))
rows.push([match[2]])
}
}
dv.table(["Content"], rows)
```
It works belike:
您可以向我们提供更多信息, 以便我们可以为您提供更多针对性的建议.
敬颂台安~
3 个赞
zzzzzr
2023 年10 月 21 日 14:03
18
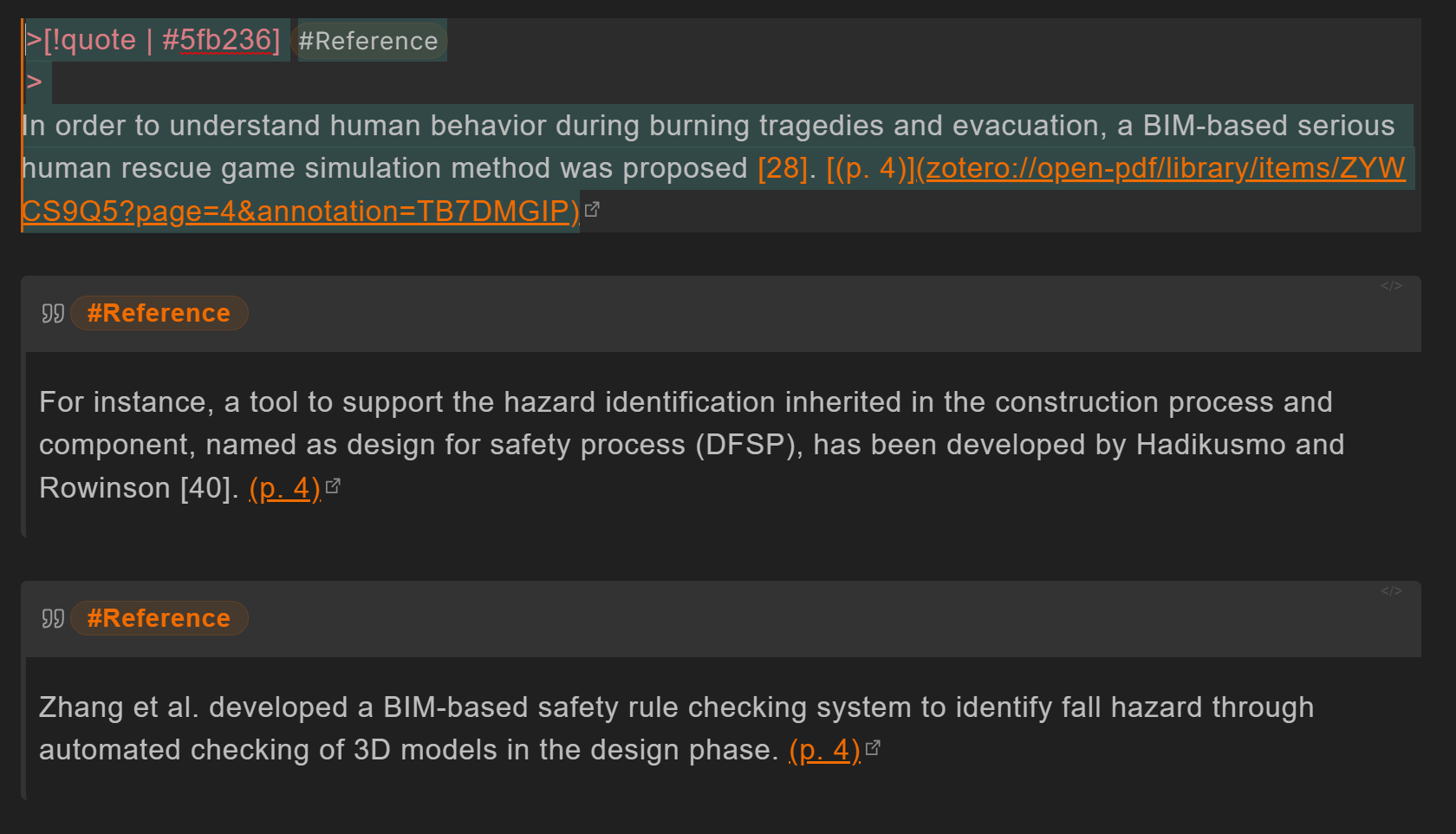
您好,感谢您提供的代码,我使用它达成了筛选的目标;但由于我的callout是使用的代码进行的批量命名,与上面的几位有所区别,想请教下这种情况该怎么处理?
ob2022
2023 年12 月 4 日 01:49
19
你好,我按上面的问题和答案来操作,都不能成功,不知到问题在哪里。