因为ob并不支持多个文件合并,所以我想用dataviewjs来把n个文件提取到一个文件下,然后就可以导出pdf了。这样可以把一些散落的片段,比如说例题,整合起来,方便查看。目前已经可以正常提取并放入表格,但是我想给表格中的正文添加首行缩进(可能是个伪需求)。
首先放出自己的代码。(ps:这段代码是我根据求助Dataview抽取callout - #7,来自 熊海 这里的熊海大佬的代码配合chatgpt魔改的,本人的js代码实力非常一般)
const pages = dv.pages('"Project notes/Politics"')
const rows = []
//因为不打算删除yaml 所以把正则给注释掉了,但是我的模板里会有# Reference 所以把Reference给删除了,这里不重要
//const regex1 = /---([\s\S]*?)---/g
//const regex2 = /#\sReference([\s\S]+)/g
const regex3 = /#\sReference/g
for (const page of pages) {
const file = app.vault.getAbstractFileByPath(page.file.path)
const contents = await app.vault.read(file)
// const cts1 = contents.replace(regex1, "") // 清除yaml
// const cts2 = cts1.replace(regex2, "") // 清除引用后内容
const cts3 = contents.replace(regex3, "") // 清除Reference
const fileName = page.file.name;
const match = fileName.match(/\d+/);
const number = match ? parseInt(match[0]) : NaN;
// Get the creation timestamp of the file
const creationTime = page.file.ctime;
rows.push([creationTime, page.file.link.toString(), cts3])
}
// Sort rows based on creation timestamp
rows.sort((a, b) => a[0] - b[0]);
dv.table(
["Page"], // Table's header row
rows.map(row => {
const title = `# ${row[1]}\n`; // Create centered title
const contentWithTitle = title + row[2]; // Combine title and content
return [contentWithTitle]; // Create a single column row for content
}),
)
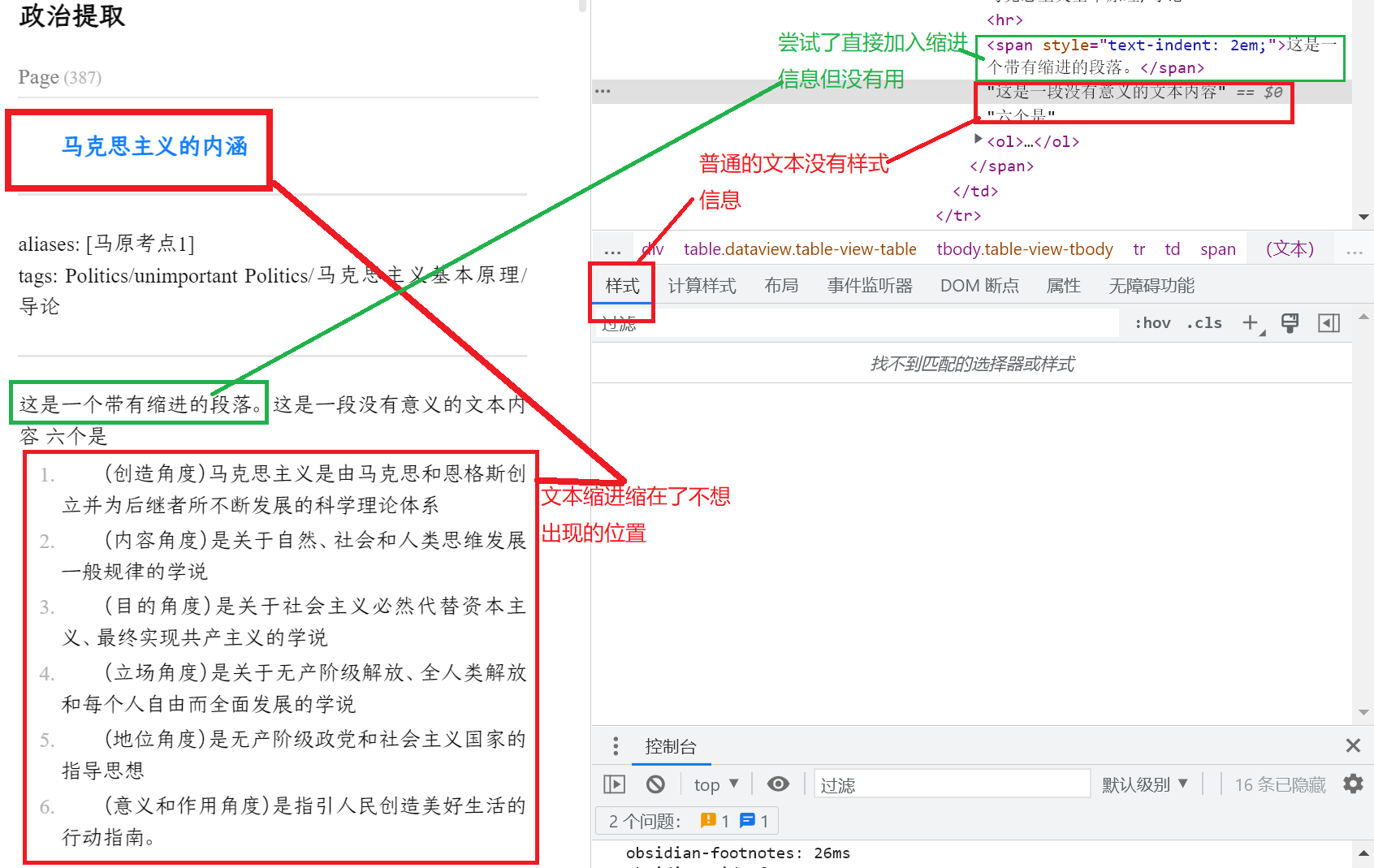
我用css实现了两端对齐,可是当我在内部插入text-indent:2em时,并没有将我想要的进行缩进。出现了以下问题如图所示。
我想问一下dataview 表格内的首行缩进该怎么实现?提取出来没有样式是不是就很难实现了,是不是我的提取代码有问题导致了样式信息的缺失?如果是,该怎么解决?
在图中绿色部分,尝试直接加入缩进,但没有效果。
尝试利用gpt更改代码获取样式信息,也无用。
PS:
Probe
2023 年8 月 18 日 01:54
2
在图中绿色部分,尝试直接加入缩进,但没有效果
span 设 text-indent 应该没用, 这属性只对块级元素生效 div / p / …
简单情况, 直接两个 全角空格 完事,dv.paragraph 之类的自己拼接出来
好的谢谢。我让gpt按照你的想法写了代码。
dv.table(
["Page"], // Table's header row
rows.map(row => {
const title = `# ${row[1]}\n`; // Create centered title
const contentWithTitle = title + row[2]; // Combine title and content
const indentedContent = `<div class="indented">${contentWithTitle}</div>`; // Wrap content in a div with class "indented"
return [indentedContent]; // Create a single column row for content
}),
)
不过还是没有效果,我放弃了。感谢您的回答
Probe
2023 年8 月 19 日 04:38
4
嗯, 确实这细节不碍事
ChatGPT 给出的代码基本是对的,<div> 里面套 markdown 语法, 应该显示不出来的吧?
可以试试
```dataviewjs
let rows = [
['rowtitle1', 'rowtitle11', 'rowcontent111 rowcontent111 rowcontent111 rowcontent111 rowcontent111 rowcontent111 rowcontent111 '],
['rowtitle2', 'rowtitle22', 'rowcontent222 rowcontent222 rowcontent222 rowcontent222 rowcontent222 rowcontent222 rowcontent222 rowcontent222'],
['rowtitle3', 'rowtitle33', 'rowcontent333 rowcontent333 rowcontent333'],
]
dv.table(
["Page"], // Table's header row
rows.map(row => {
const title = `${row[1]}`; // Create centered title
const contentWithTitle = row[2]; // Combine title and content
const indentedContent = `<b>${title}</b><div class="indented" style="text-indent: 2em;">${contentWithTitle}</div>`;
return [indentedContent];
}),
)
```
在我这里是
您好,感谢您的回答。用了您的代码,提取现在是这个样子了。内容被加粗,原本的标题链接也没了。
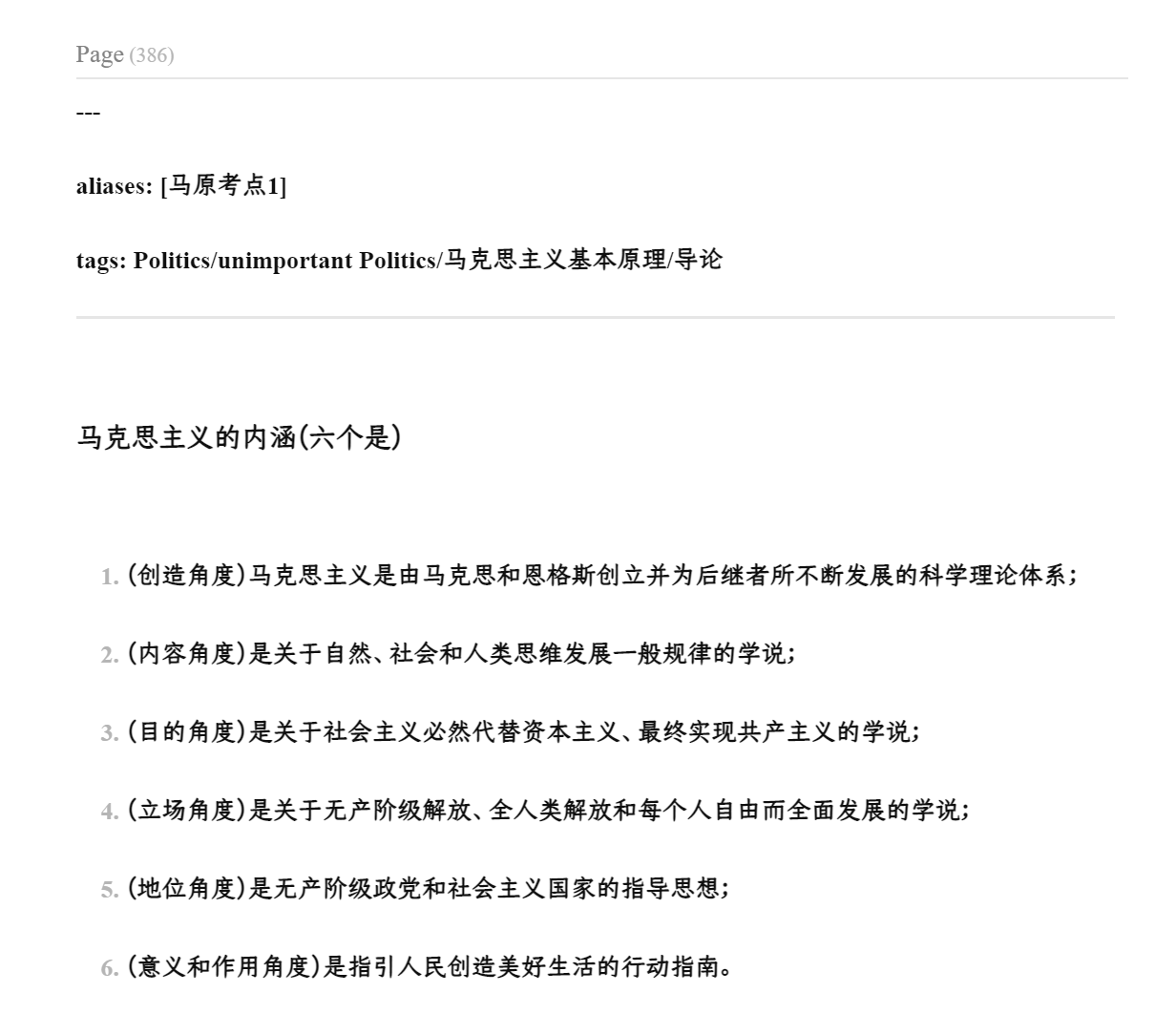
(创造角度)马克思主义是由马克思和恩格斯创立并为后继者所不断发展的科学理论体系;
(内容角度)是关于自然、社会和人类思维发展一般规律的学说;
(目的角度)是关于社会主义必然代替资本主义、最终实现共产主义的学说;
(立场角度)是关于无产阶级解放、全人类解放和每个人自由而全面发展的学说;
(地位角度)是无产阶级政党和社会主义国家的指导思想;
(意义和作用角度)是指引人民创造美好生活的行动指南。
马克思主义哲学、马克思主义政治经济学和科学社会主义是其三个基本组成部分,它们有机统一并共同构成了马克思主义理论的主体内容。
[!note] 补充
基础和方法——马克思主义哲学
主体内容——马克思主义政治经济学
目的和归宿——科学社会主义
马克思主义用哲学的方法,写了政经的理论,最终得到科社的结论。
您可以再试试?
Probe
2023 年8 月 23 日 03:16
6
不能完全抄这代码啊, 它就为了演示 text-indent 怎么起作用
就我理解这事难在, 如果传入 md 格式文本由 dv 渲染出单元格内容, 这时 dv 不会给普通段落加 p 标签, 而是直接做为文本节点挂在单元格里, 这导致不太方便用 css 控制样式
所以至少有这两个办法:
自己编辑正文内容, 加上空格, 再传给 dv.table 去渲染
自己把正文解析为 html, 给段落加好 p 标签, 再传给 dv.table 并结合外部 css 去控制
简单办法就是给正文内容主动加个空格就完了:
// ... 一楼的其他代码不动,
// 给文本中, 应该是普通段落的, 加两个空格
let cts3 = contents.replace(regex3, "");
let cts3 = cts3.split('\n').map(line => {
if (line.length > 0 && /^[^>#\d\-\*\+`]/.test(line)) {
return '  ' + line;
} else {
return line;
}
}).join('\n');
熊海
2023 年8 月 24 日 14:10
7
晚上好! 我收到了您的链接邮件, 您可以提供需要提取的文本的其中一小段吗? 这样我们可以更方便地帮您进行测试和解决问题, 非常感谢, 祝您生活愉快!