抱歉这么晚才回复,这个问题似乎没办法解决,折叠功能似乎与dataviewjs不兼容,甚至正常标题会把dv同级标题一起折叠
谢谢大佬,目前我想到了一个办法,这个渲染成折叠的callout标注框可以间接地实现折叠
还有一个问题,这一句const files = dv.pages(#aaaaa).sort(p=>p.file.name,‘desc’),我想搜索一个文件夹里的内容,但是想排除掉某些文件(已知文件名),要怎么写呢
准确的说是想排除当前文件,我写成const files = dv.pages("diary" and -"this.file.path").sort(p=>p.file.name)不能当前文件不知道为什么不行,但是我把当前文件的完整路径写进去就行
dv.pages(`"diary" and -"this.file.path"`).sort(p=>p.file.name),这样是不行的,你这相当于排除一个名叫this.file.path的文件![]() ,如果想在
,如果想在`包起来的字符串中插入变量,可以用${}把变量括起来,像这样dv.pages(`"diary" and -"${this.file.path}"`).sort(p=>p.file.name)
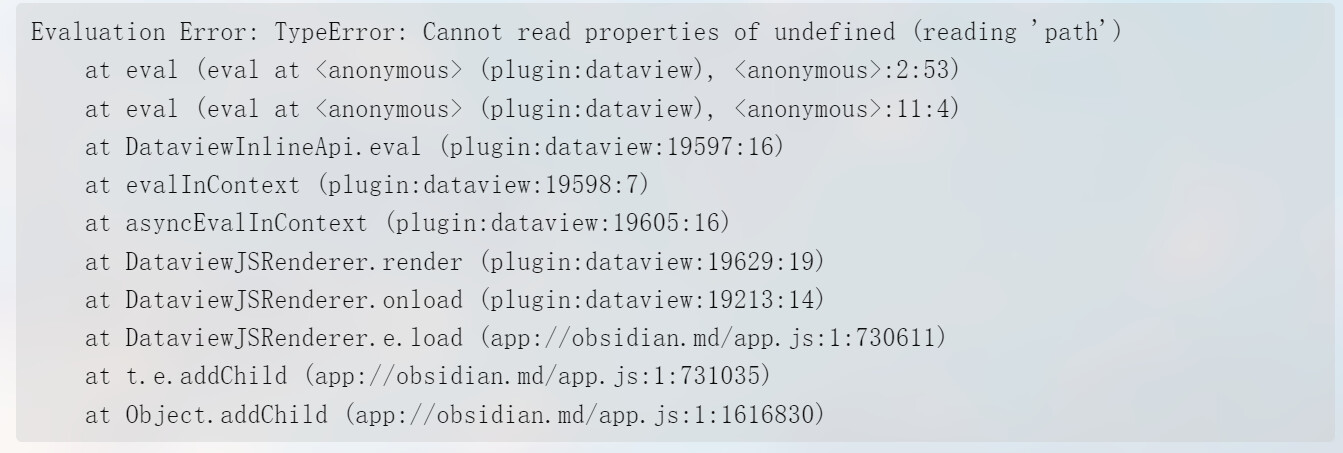
诶,我突然没反应过来这个变量,这个this是你从哪学来的![]() ,它其实等同于dv,底下没有叫file的属性,也就没有path,如果想从dv里获取当前文件路径可以用
,它其实等同于dv,底下没有叫file的属性,也就没有path,如果想从dv里获取当前文件路径可以用dv.currentFilePath,不过更常见的方法是dv.current().file.path,或者说是this.current().file.path
好了没问题了谢谢大佬

请教大佬:我需要将指定文件夹下所有文档的标题、大纲(1-6级标题),自动提取、汇总在一个页面(下级标题最好能自动缩进展示),请问怎样的代码能实现这个功能?
```dataviewjs
let files = dv.pages(`"300-系列笔记/310-课程/信号与系统"`)
for(let f of files) {
let content = await app.vault.readRaw(f.file.path)
content = content.split('\n')
let headers = content.filter(p=>/#+ (.*?)/.test(p))
dv.paragraph(f.file.link+'\n'+headers.map(p=>p.replace(/#/g,' ')+'\n').reduce((a,b)=>a+b,''))
}
```
1 个赞
太牛了!正是我需要的效果!可解决我的大问题了,非常感谢!!!大神帮我再完善一下好吗?就是现实的行距太密了,挤在一起了很难看,能否加大标题之间的空行?

直接做成列表应该会更好看一点
```dataviewjs
let files = dv.pages(`"300-系列笔记/310-课程/信号与系统"`)
for(let f of files) {
let content = await app.vault.readRaw(f.file.path)
content = content.split('\n')
let headers = content.filter(p=>/#+ (.*?)/.test(p))
dv.paragraph('### '+f.file.link+'\n'+headers.map(p=>p.replace(/#+/g,' '.repeat(p.match(/#+/g)[0].length*2)+'-')+'\n').reduce((a,b)=>a+b,''))
}
```
嗯,效果非常好,这样我可以更高效的整理素材,太感谢你了!
请教下,在此基础上,如果想把对应笔记的某一个yaml的值也显示出来,应该怎样修改代码呢?谢谢!
例如,我md笔记的yaml中均有类似 url: https://forum-zh/t/topic/5954/135 的数据(即:url: 网址),我想将之也显示出来。
那加一句就行了
```dataviewjs
let files = dv.pages(`"300-系列笔记/310-课程/信号与系统"`)
for(let f of files) {
let content = await app.vault.readRaw(f.file.path)
content = content.split('\n')
let headers = content.filter(p=>/#+ (.*?)/.test(p))
dv.paragraph('### '+f.file.link)
dv.paragraph('url:'+f.url)
dv.paragraph(headers.map(p=>p.replace(/#+/g,' '.repeat(p.match(/#+/g)[0].length*2)+'-')+'\n').reduce((a,b)=>a+b,''))
}
```
2 个赞
很强悍!能再加一条排序的命令不?一直没太弄明白js的排序
按什么排序呢,排序用sort就行了
我只知道这种写法.sort(f => f.file.mtime, ‘asc’) ,但加进去报错。另外请教下,这种渲染出来的结果,似乎没办法导出为PDF,不知道有没有解决办法,谢谢
你这个没问题啊,是不是加错位置了
另外关于导出pdf,我以前也发现导出不完全,只有第一个循环里的渲染的内容出现在pdf里
刚才想了想,猜测可能是与异步运行有关,提前加载好内容再一次性渲染出来后发现果然没问题了
```dataviewjs
let files = dv.pages(`"300-系列笔记/310-课程/信号与系统"`).sort(p=>p.file.mtime,'asc')
let headers = []
for(let f of files) {
let content = await app.vault.readRaw(f.file.path)
content = content.split('\n')
headers.push(content.filter(p=>/#+ (.*?)/.test(p)))
}
for(let i=0;i<files.length;i++) {
dv.paragraph('### '+files[i].file.link)
dv.paragraph('url:'+files[i].url)
dv.paragraph(headers[i].map(p=>p.replace(/#+/g,' '.repeat(p.match(/#+/g)[0].length*2)+'-')+'\n').reduce((a,b)=>a+b,''))
}
```
1 个赞
确实放错位置了,谢谢!
请问提前加载好内容,只能用鼠标滑轮一点点的下拉么?我的文件比较多,这样太费劲了。请问有没有类似一键执行的方法呢?