Ther
2025 年12 月 11 日 03:17
1
已经下载了pandoc。
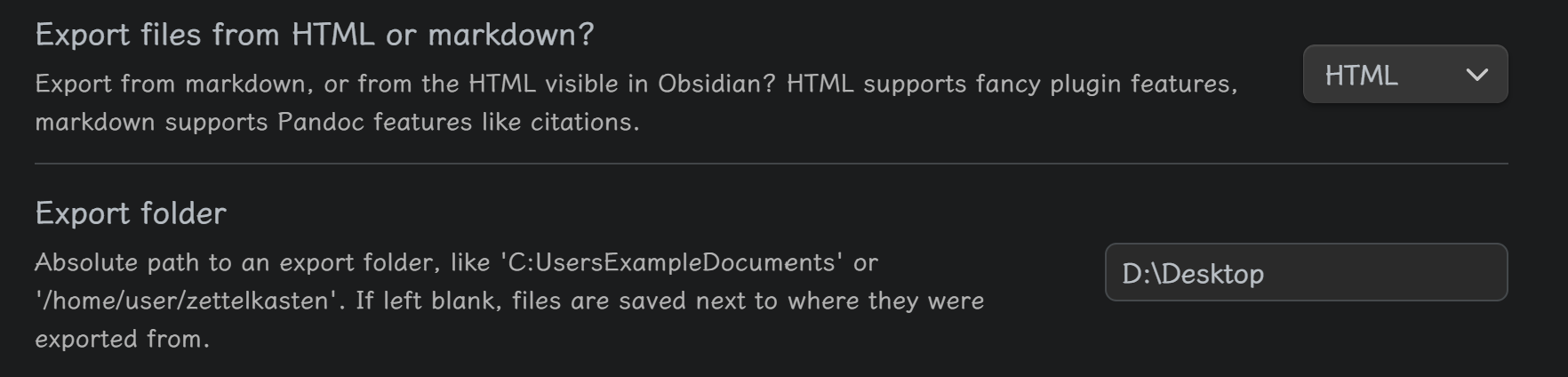
我的电脑是win11,obsidian版本是1.10.6,obsidian-enhancing-export插件版本是1.10.11,obsidian-pandoc插件版本0.4.1,pandoc版本是3.8.3。
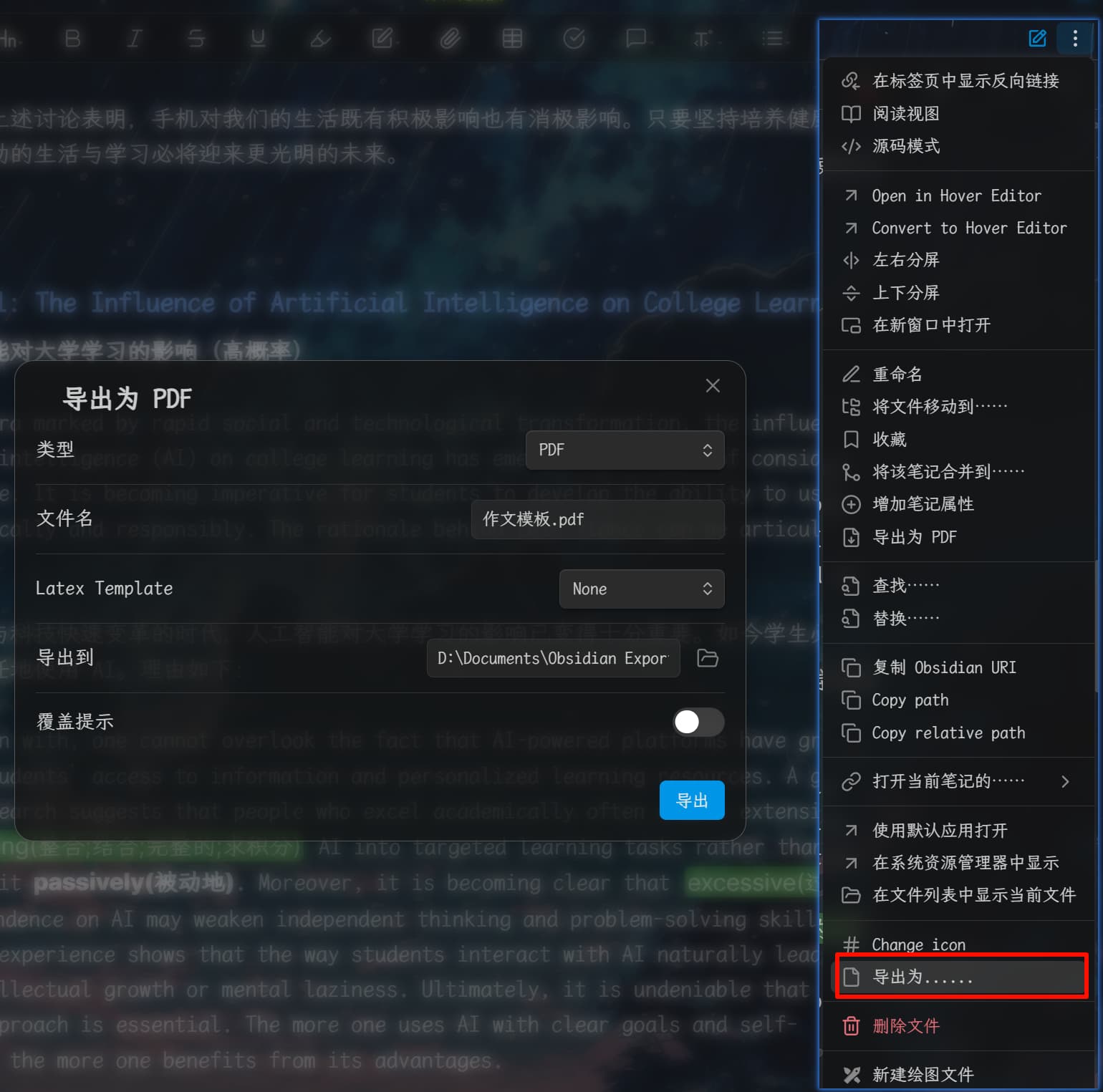
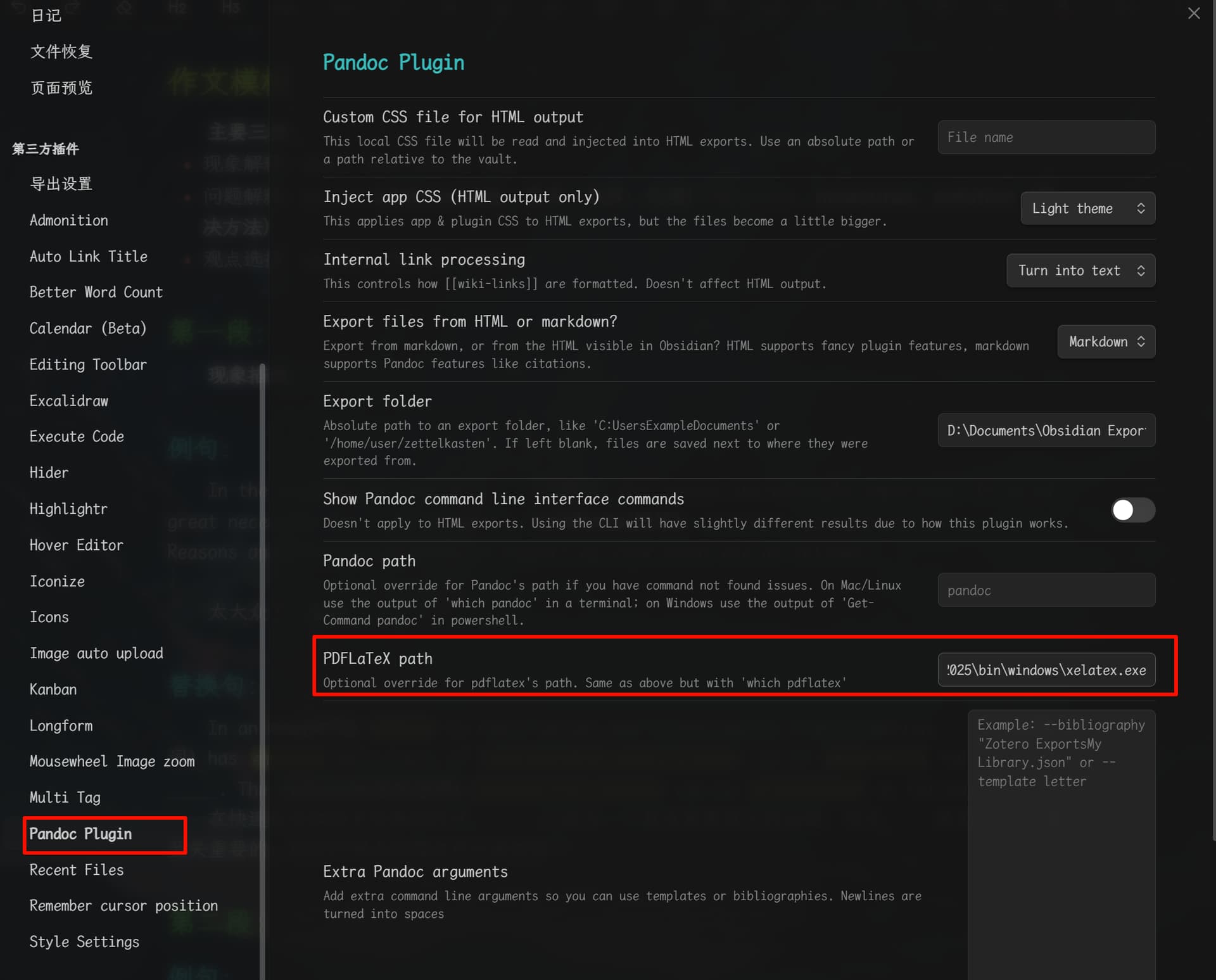
点击导出没有任何反应,没有任何文件输出,不管是导出什么格式,导出路径也设置了没有中文,连报错也没有:
插件也检测到了pandoc的路径,也试过自定义路径,没有任何用:
在论坛内发现有一样情况的人,但是解决办法是换pandoc插件,然而我使用pandoc插件也有问题。
有朋友知道是怎么回事吗,该怎么办啊
导出内容带有中文的文件会报错:
并且生成的文件只有非中文字符,中文部分直接没有:
我在网上查了一下,有说法是要把插件的PDFLatex路径填上xelatex.exe的路径
但是没有任何作用。
我也试过重启软件,更新插件等,但是都没有用,网上也都搜了论坛也搜了,但是找不到解决办法,只能来这里求助了,救命,怎么办啊家人们
我考系解
2025 年12 月 12 日 03:44
2
我是之前问的那个。目前没搞清楚原理。
Ther
2025 年12 月 12 日 07:53
3
唉,试过了,还是没变化,有中文的地方还是根本不会显示
Probe
2025 年12 月 13 日 03:09
4
这俩插件都是基于 pandoc 命令行导出, 插件内部给拼接一条复杂的导出命令, 不确定性比较大
建议先回原始需求, 如果只为了要拿到 pdf 可以试试 Ob 自带的导出 pdf, 兼容性好点
一定要用这俩插件的话, 查了下 obsidian-enhancing-export 更新于一个月前, obsidian-pandoc 是三年前, 那还是研究前者吧
考虑先简化状态, 造个新仓库, 只放一条笔记, 不要主题样式, 只装必须插件, 再用 obsidian-enhancing-export 导出试试, 导出前先把控制台打开能看到具体报错
Ther
2025 年12 月 14 日 09:47
5
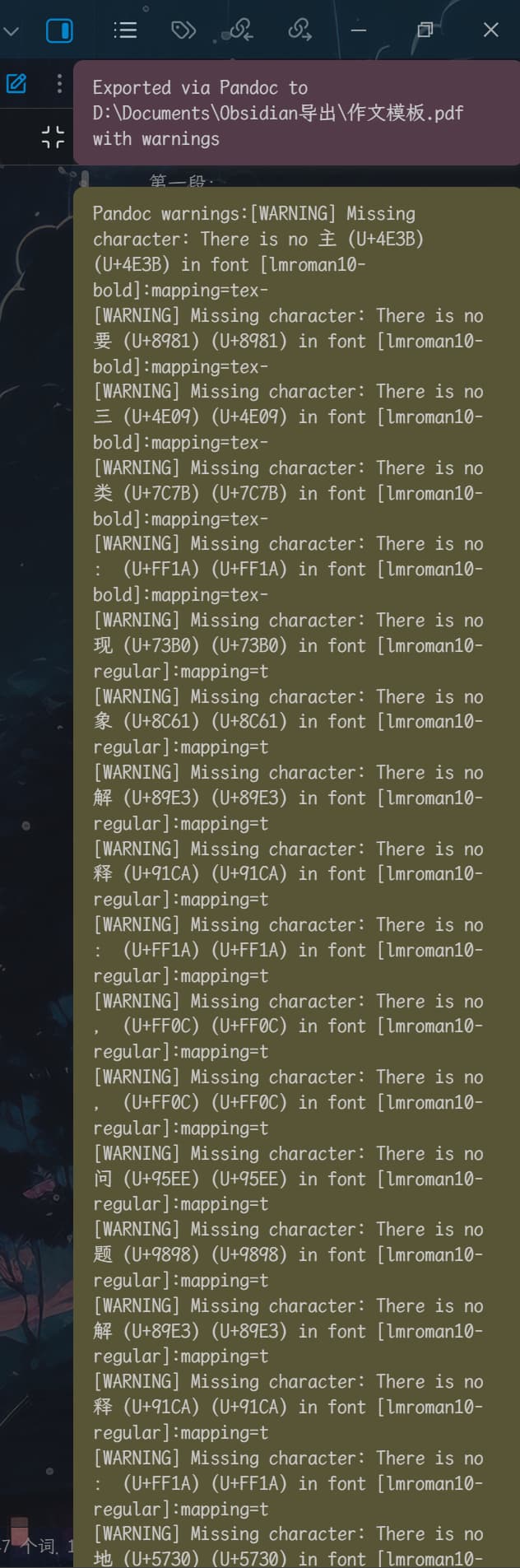
我用了 obsidian-enhancing-export 的前一个版本,1.10.10,这次导出倒是有反应了,但是,经过一系列测试,只有在导出PDF时仍然有问题:
只要文档的内容有中文,那么就会导出报错:
内容全英文的就没有问题,我又逛了一圈插件的issue区,好像这是pandoc的问题?我还没查清楚,我先继续看看
Probe
2025 年12 月 15 日 04:14
6
我弄个新环境顺着楼主的步骤试了下, 好家伙, 简直一步一坑,
仍然使用 --pdf-engine=pdflatex
在文档开头声明如下
---
header-includes:
- \usepackage[UTF8]{ctex}
# 周围允许有其他的与导出 pdf 无关的 YAML 文档属性
---
如此设置后, 可以解决导出 pdf 中文问题, 楼主可以试试
附 过程记录如下
1 下载 pandoc Pandoc - Installing pandoc 这一步没啥问题, 最后命令行里 pandoc -- version 能查到就是成功
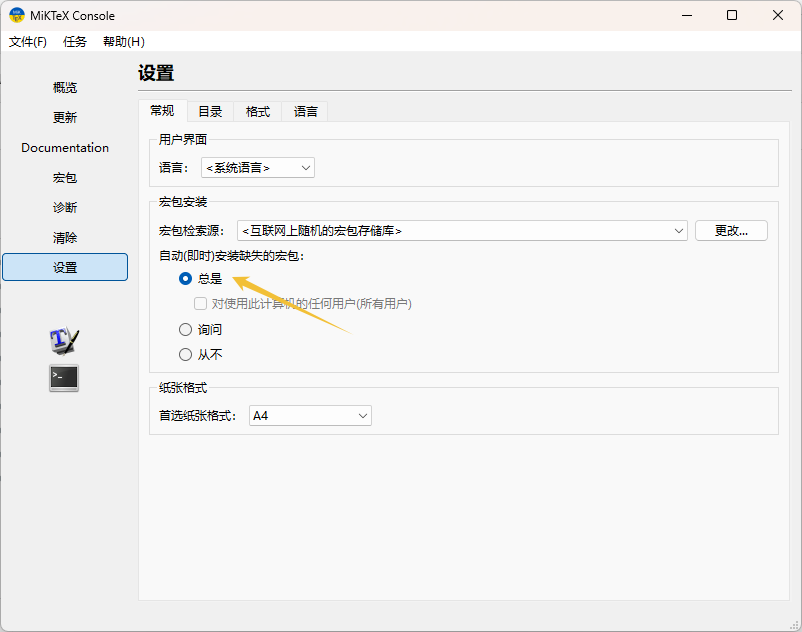
2 下载 MiKTeX Getting MiKTeX 这一步可能是对应楼主的 texlive 方案, 具体我不太熟悉 LaTeX 这一大堆知识, 完后设置为 “总是自动安装缺失宏包”
3 下载 obsidian-enhancing-export 这插件在当前最新版, 有严重 bug: 当导出后, 界面完全丢失, 无响应无报错v1.10.11, 上一个可用版本是 1.10.10
在 console 里界面完全丢失时会看到报错如下
那么卸载最新版插件, 从 Releases · mokeyish/obsidian-enhancing-export 里找个可用版本的, 手动下载回来releases 里特定版本号 的插件)
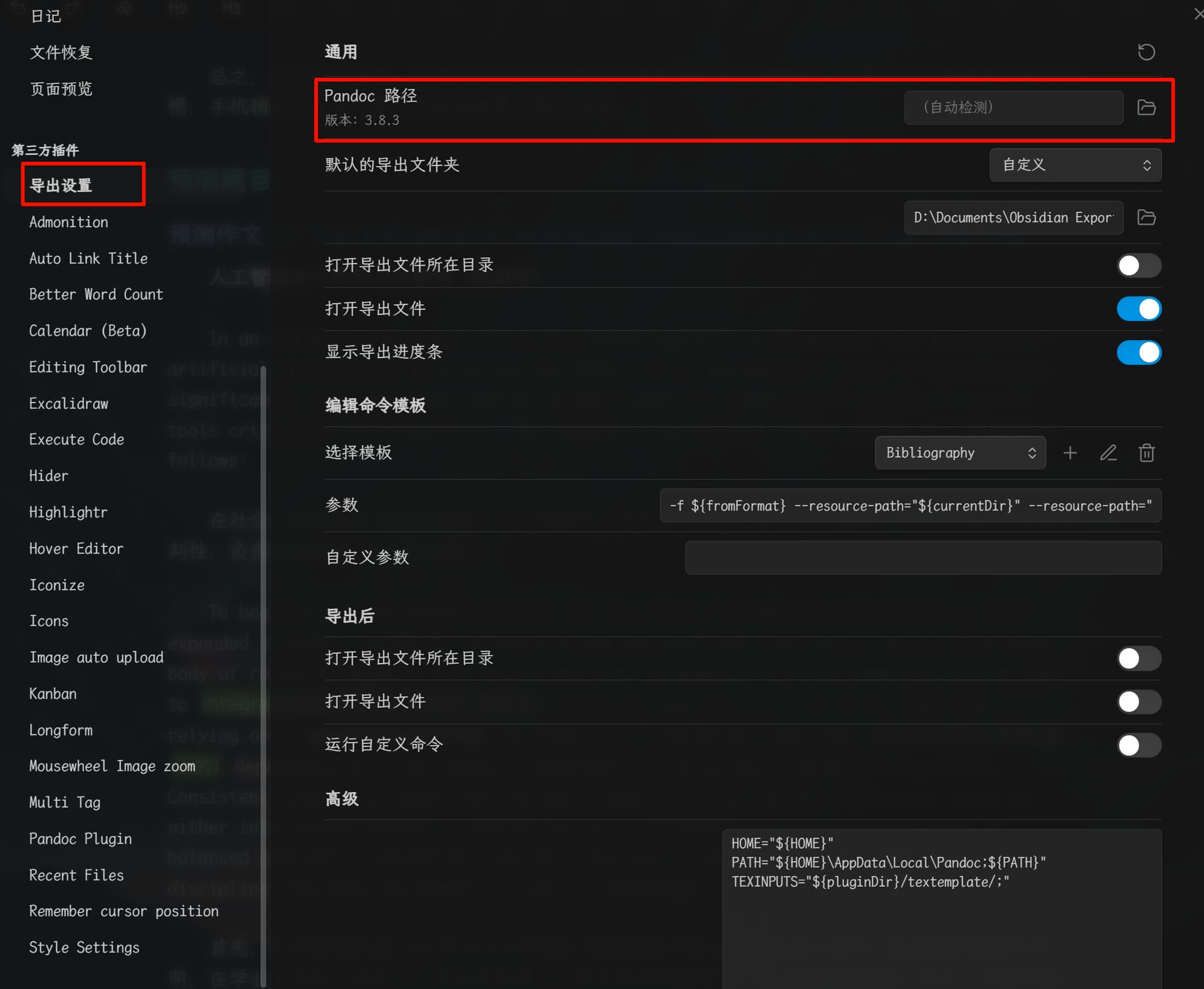
4 设置 obsidian-enhancing-export
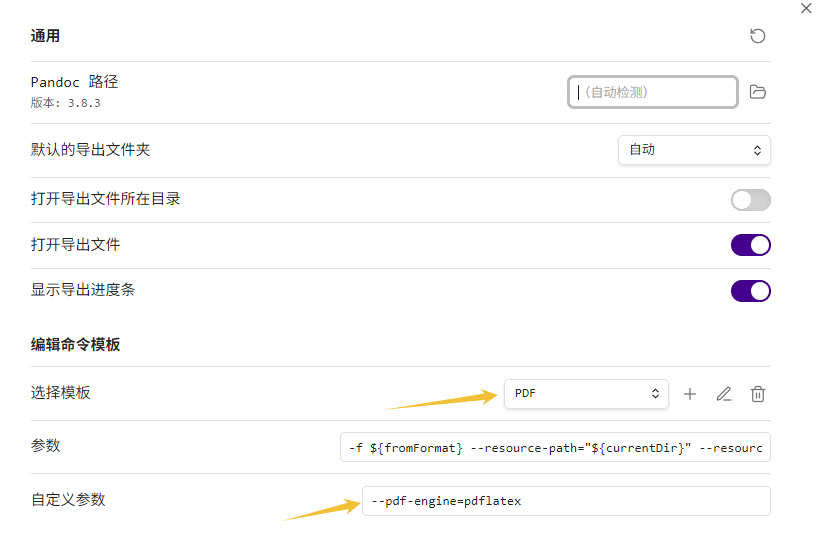
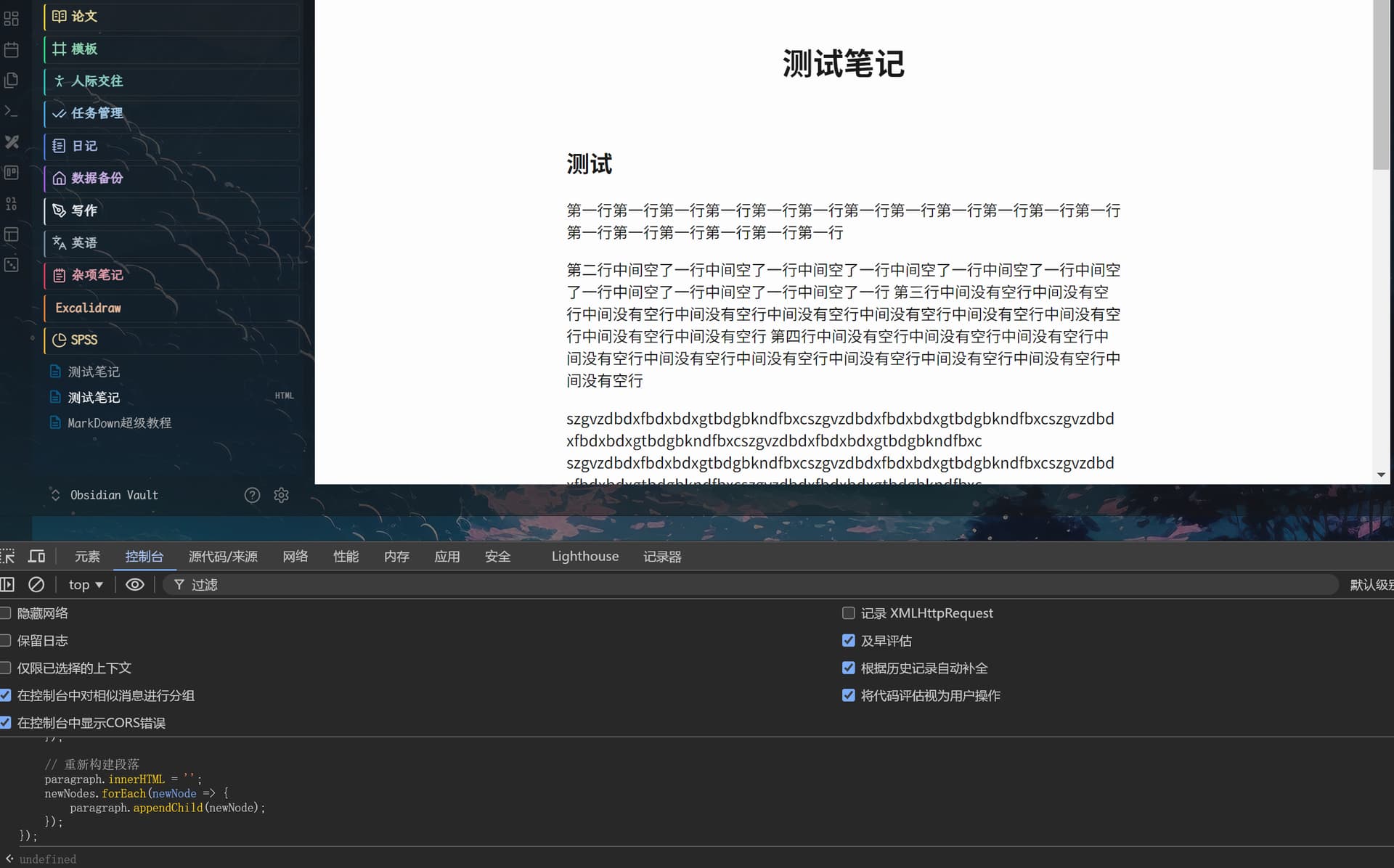
我这边是如图
注意要先下拉 “选择模板: pdf” 时, 再填入自定义参数
--pdf-engine=pdflatex
5 到这一步, 终于复现了楼主的报错
Error producing PDF.
! LaTeX Error: Unicode character X (U+65E0)
not set up for use with LaTeX.
如果改换 --pdf-engine=xelatex 等等也是类似报错, 具体文本各异
一顿 AI 加搜索之后, 找到的方案是, md 文档开头添加 YAML 元数据
---
header-includes:
- \usepackage[UTF8]{ctex}
---
完后终于能在导出 pdf 里看到中文字符了
Ther
2025 年12 月 17 日 01:17
7
是的,一步一个坑。。。我之前也搜到过文档开头添加YAML数据,不过我想如果每次导出都要声明一次太麻烦了,想找到一劳永逸的办法,就没说,然而目前看下来好像没有其他办法了。
在文档开头添加这个YAML后,确实能导出带有中文的PDF了,但是我又发现了一个新问题:导出带有markdown语法删除线(~~~~)的文档会报错:
我问了AI,说是 LaTeX 层面对“带 CJK(中文)字符的删除线命令”处理不当导致的语法异常:报错信息里\st{测试} 被 LaTeX/ctex 在 CJK 语境下解析时触发了 “Argument of \CJK@xxx has an extra }” 的错误。
之后他给的方法是引擎改xelatex,文档开头添加如下YAML:
---
header-includes:
- \usepackage[UTF8]{ctex} % 如果你已经用 ctex,可以保留
- \usepackage[normalem]{ulem} % 提供 \sout / \st 等删除线命令,normalem 避免重定义 \emph
- \usepackage{xeCJK} % 如果用 xelatex,显式加载 xeCJK 更保险
- \setCJKmainfont{Noto Serif CJK SC} % 把这里换成你已经安装的中文字体名
---
然而没有用,之后试了其他方法也没用。
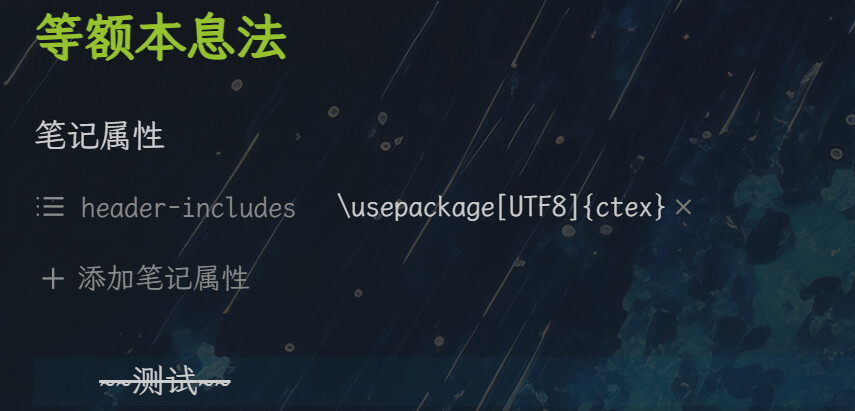
他还说把删除线换成 HTML语法的版本: <del>文本</del>,然而我试过了,虽然导出成功了,但是导出的PDF文件的相应文字没有删除线:
PS:我感觉我要疯了,折腾了这么久,可以说仍然没什么进展,而且好不容易跨过一个坑,又有无数坑。。。
Probe
2025 年12 月 17 日 02:13
8
我觉得还是分两块研究:
1 还是回到最开始的讨论, 为啥不试试 Obsidian 自带的 “导出为 pdf”?
这比 pandoc 识别 markdown 语法细节, 生成符合意愿的 pdf 要可靠许多,
同类思路还有, 许多 Ob 插件有全库 / 单个笔记转 HTML 的功能, 然后在浏览器里 HTML 打印 pdf
2 如果还是用 pandoc 方案, 删除线问题我再看看, 应该也是有办法的
Ther
2025 年12 月 17 日 02:32
9
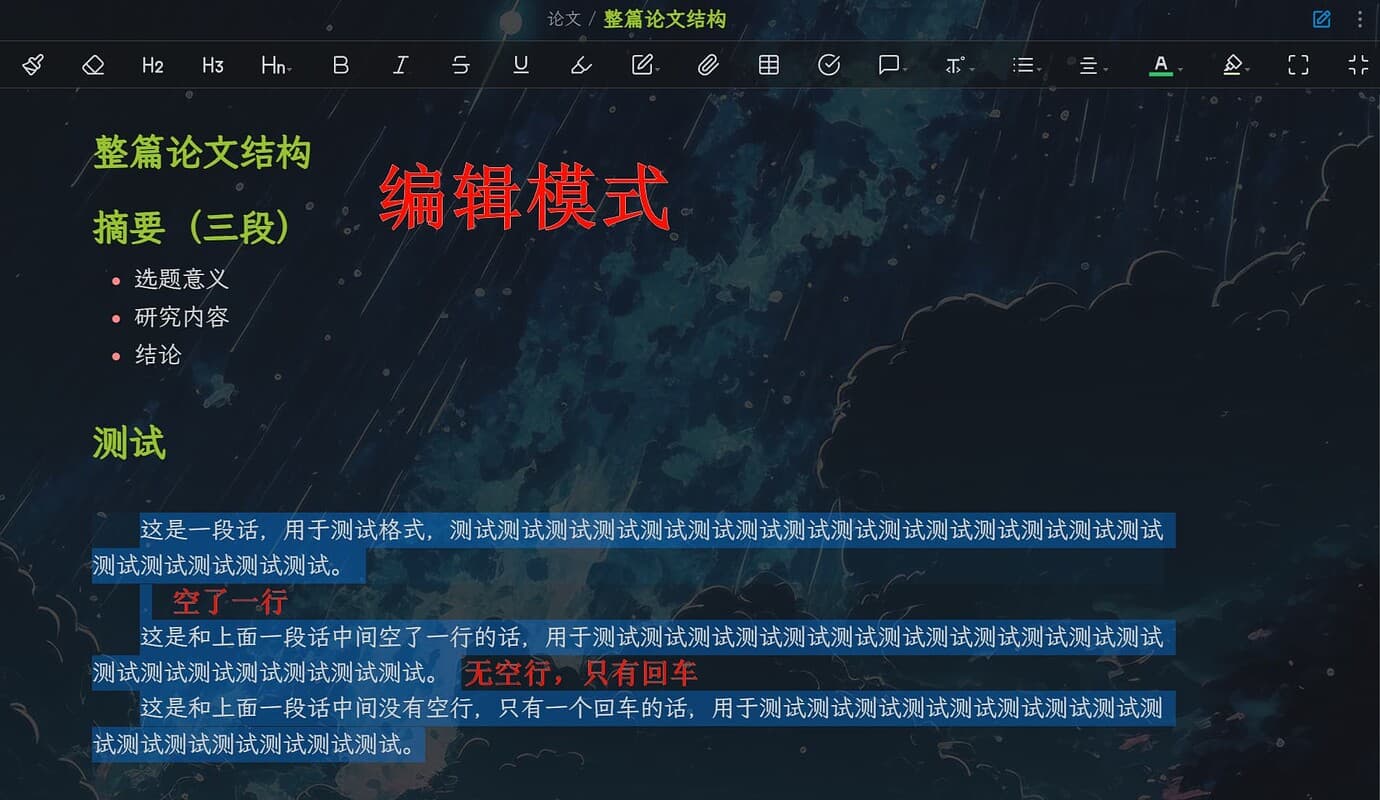
obsidian自带的导出pdf确实挺好的,但是那个空行/换行问题我一直很苦恼,即编辑模式下,多个空行在阅读模式会直接消失,如果两段话之间没有空行只有一个回车,在阅读模式下两段话会挤在一起。导出的pdf的样式和阅读模式一样,看起来排版很怪。。。
我不想每次换行时还要插入<br>等换行的符号,太麻烦了。。。
我以为用其他的导出插件也许能解决这个问题,就开始研究其他导出插件,之后进度就是目前这样了。。
Probe
2025 年12 月 17 日 08:23
10
大致了解了, 这种情况我自己的教训是, 先不追求导出时 “简单省事”, 先顾好导出过程每一步都 “可控, 能及时看到错误”
这排版问题核心是:
markdown 原本规则是单个换行渲染到同一段落, 连续两个换行才是开启新段落
Ob 禁 “严格换行” 时, 认为单个换行就渲染为视觉上的换行 (<br>) 连续两个换行开启新段落
“严格换行” 无论开还是关, 在简单情况都是够用的, 但在额外要求首行缩进等复杂规则后, 其生成页面结构是 <div> + <p> + <br> + 全角字符空格缩进 或 段落样式缩进 的复杂混合体, 很难完美符合需求
试了下我觉得最省心的组合如下, 供楼主参考:
1 在 Ob 里禁 “严格换行”, 写作时顶格写, 不加全角空格
2 编辑模式的两字符缩进视觉效果, 通过 css 解决
3 放弃直接导出 pdf, 而是先导出 HTML, 以 js 修补再导出 pdf
前两步都没啥难的, 论坛里也不少资料
第三步是, 随便找个能把阅读视图转 HTML 的工具 (插件 Webpage HTML Export, Html Server, Share Note 等等) 拿到 HTML 后在浏览器打开, 让 AI 写个调格式的脚本直到效果满意, 然后网页另存 pdf
举例
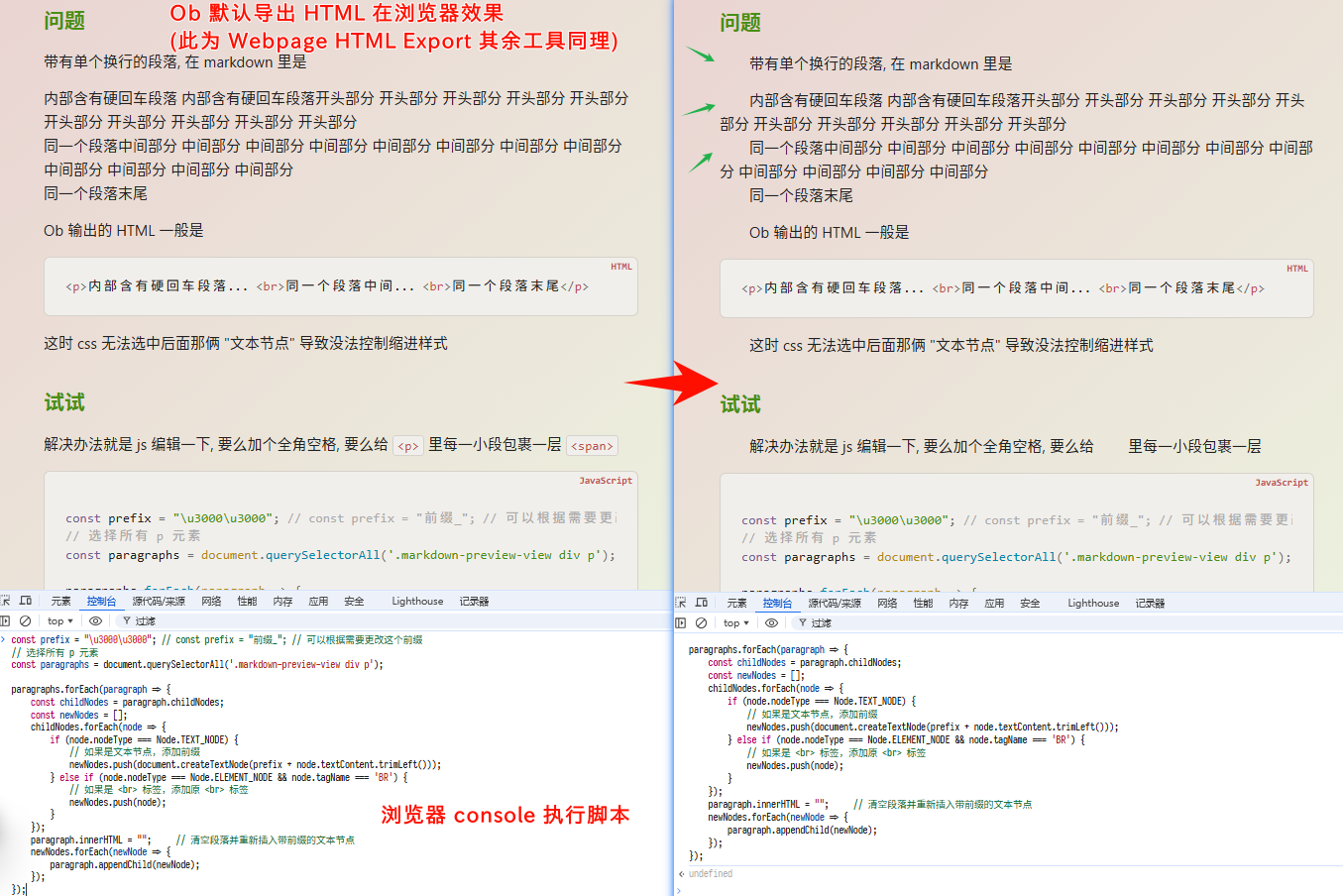
带有单个换行的段落, 在 markdown 里是
内部含有硬回车段落...
同一个段落中间...
同一个段落末尾
Ob 输出的 HTML 一般是
<p>内部含有硬回车段落... <br>同一个段落中间... <br>同一个段落末尾</p>
这时 css 无法选中后面那俩 “文本节点” 没法控制缩进样式
解决办法就是 js 编辑一下, 要么给段首加个全角空格, 要么给 <p> 里每一小段包裹一层 <span>
const prefix = '\u3000\u3000'; // const prefix = "前缀_"; // 可以根据需要更改这个前缀
const paragraphs = document.querySelectorAll('.markdown-preview-view div p');
paragraphs.forEach(paragraph => {
const childNodes = paragraph.childNodes;
const newNodes = [];
let afterBr = true; // 标记是否在 <br> 之后, p 里首个文本元素也设置为 true
childNodes.forEach(node => {
if (node.nodeType === Node.ELEMENT_NODE && node.tagName === 'BR') {
// 遇到 <br> 标签
newNodes.push(node);
afterBr = true; // 设置标记,下一个文本节点需要缩进
} else if (node.nodeType === Node.TEXT_NODE) {
// 处理文本节点
let text = node.textContent;
if (afterBr) {
// 在 <br> 之后的文本节点
// 只给第一个非空白字符前添加缩进
text = prefix + text.trimLeft();
afterBr = false; // 重置标记
}
// 保留原来的空白字符
newNodes.push(document.createTextNode(text));
} else {
// 其他元素节点(如 <code>, <strong> 等)
newNodes.push(node);
afterBr = false; // 遇到元素节点,重置缩进标记
}
});
// 重新构建段落
paragraph.innerHTML = '';
newNodes.forEach(newNode => {
paragraph.appendChild(newNode);
});
});
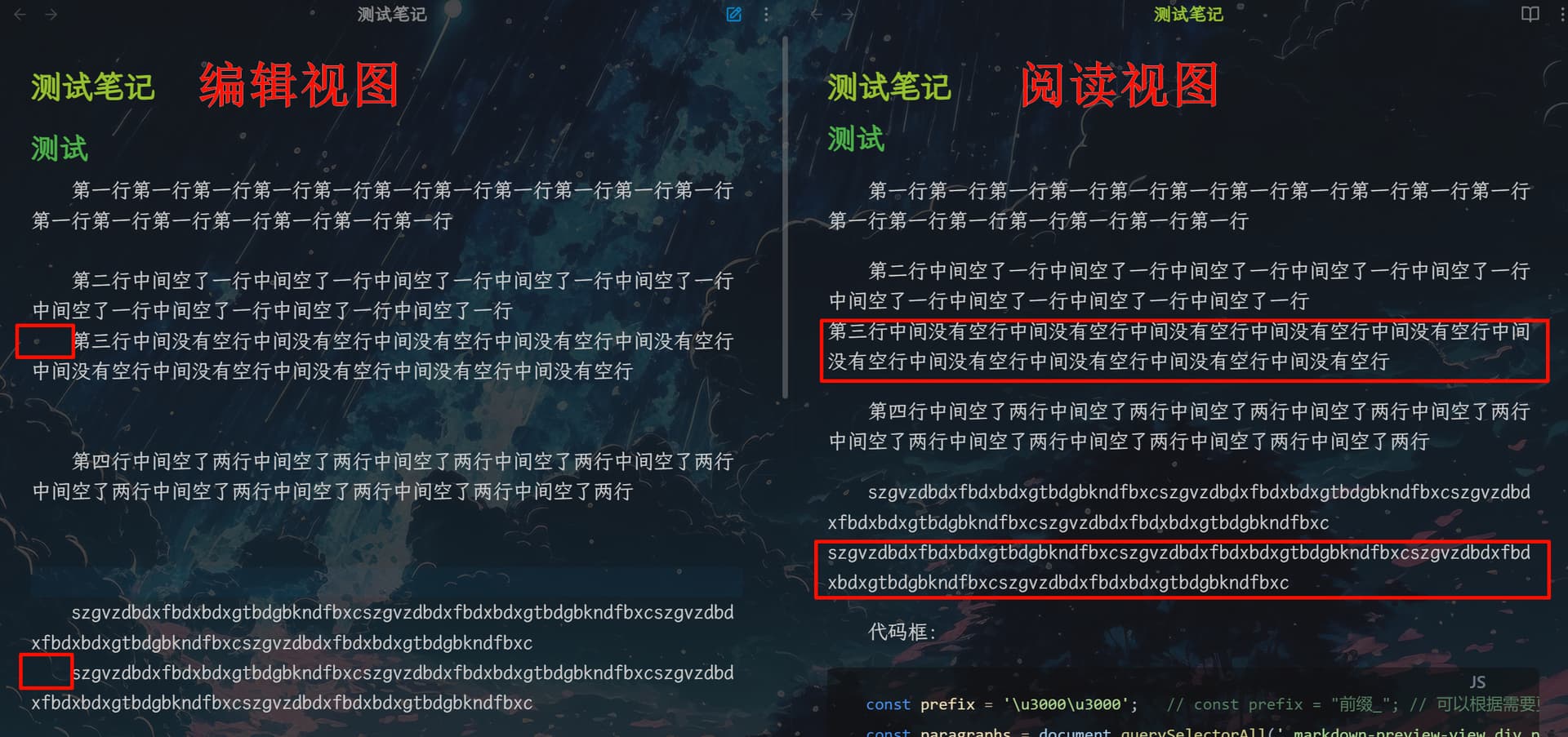
右侧图示 js 执行后效果 (原理就是给段首拼接俩全角空格) 然后浏览器存储/打印为 pdf 就行了
麻烦了点, 但是胜在过程可控, 能及时看到预览, 任何排版细节都可以让 AI 改, 楼主可以试试
Ther
2025 年12 月 19 日 02:22
11
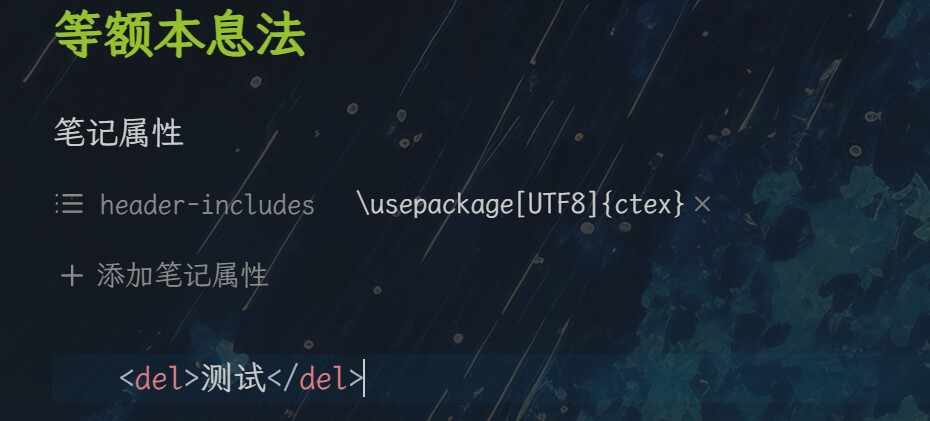
我导出了html文件,打开控制台,运行了你贴的javascript,但是没有反应,我不知道怎么回事:
话说你好像是在obsidian看的html文件?怎么做到还能保留ob主题看html文件的啊,我一点html文件就会跳转浏览器,之后下了个html reader插件才能在ob看,不过没有ob主题
我之后让AI给我写了个保留换行的css片段,成功了:
/* 让 Markdown 的单换行在阅读视图中也换行 */
.markdown-preview-view p,
.markdown-preview-view div {
white-space: pre-wrap;
}
/* 避免影响代码块 */
.markdown-preview-view pre,
.markdown-preview-view code {
white-space: pre;
}
/* 避免影响表格 */
.markdown-preview-view table,
.markdown-preview-view table * {
white-space: normal;
}
效果:
但是不能保留两个段落中间的多个空行,会被合并为一个空行,这个重新写了css也没有用,貌似得搭配javascript脚本才能实现…
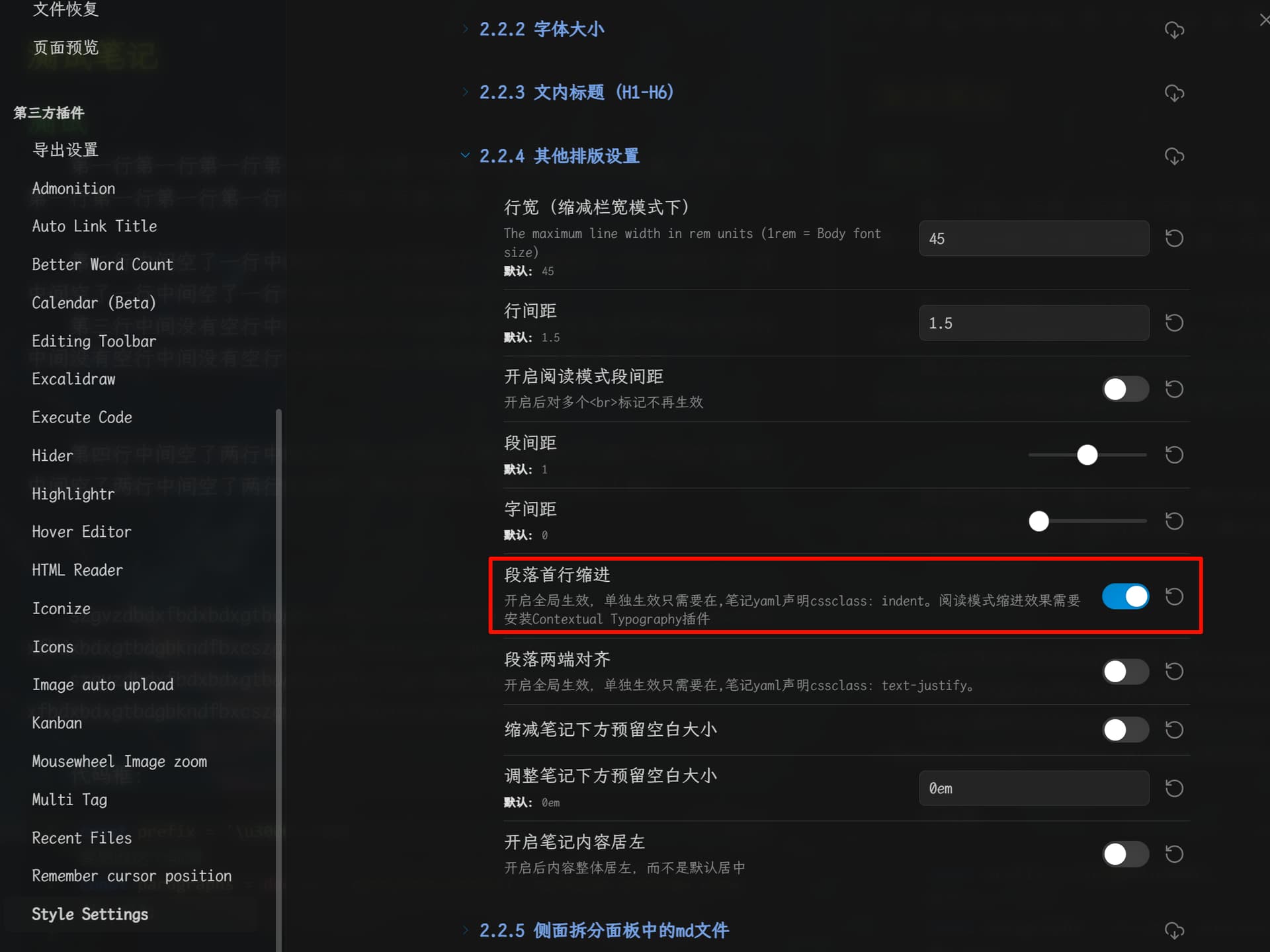
之后的首行缩进 也遇到了麻烦。blue topaz 主题,里面有 首行缩进 的选项,我有使用主题自带的这个选项,也有试过单独写css片段,但是最后的效果都一样)
不管是使用主题自带的首行缩进选项,还是单独写css,效果都一样,无法解决中间没有空行的几个段落,除了第一个段落的首行缩进:
这个情况,ai说,因为段落中间没有空行,所以这几个段落会被识别为一整个段落,所以只有最前面的段落被换行。
这个情况好烦啊(;´д`)ゞ,话说外国可能也有人遇到过这个问题,我去国外的ob论坛看看
Probe
2025 年12 月 19 日 07:09
12
导出 html 文件之后, 就跟 Ob 没关系了, 在浏览器里打开浏览器控制台, 拿 js 微调下样式, 然后浏览器另存/导出 pdf
控制台粘贴代码然后回车
是的<div class="markdown-preview-view">...<div>...<p>...</p></div></div> 结构, 但也不保证所有导出工具的生成细节全都一致
如果没反应, 可能因为导出 html 的结构不含 <div class="markdown-preview-view">... 这个指定类名, 浏览器里直接抄完整 html 源码问 AI 就行
你好像是在obsidian看的html文件?
没有, 导出 html 之后就跟 Ob 无关了,
在这个场景里, 我没有用到 html reader 插件
我之后让AI给我写了个保留换行的css片段 … 但是不能保留两个段落中间的多个空行,会被合并为一个空行 … 之后的首行缩进 也遇到了麻烦
这几个问题都是由于之前说过的原因: “额外要求首行缩进等复杂规则后, 其生成页面结构是 <div> + <p> + <br> + 全角字符空格缩进 或 段落样式缩进 的复杂混合体, 很难完美符合需求”
之前的回复就是讨论怎么解决它
为防止误会, 我再说明一下目前的事实:
Ob 的实时阅览视图和阅读视图是两套不同的 html 结构
实时阅览视图里, 拿 css 可以解决 标准段落换行+br硬换行+缩进两字符 问题, 论坛里可以搜到许多资料
阅读视图里, 由于 css 无法选中 html 结构里的 “纯文本节点”, 没法用 css 解决上述问题
通常无法准确控制 “md 转换 pdf” 以及 “md 转换 html” 的生成细节
但是已经得到 html 后, 再次编辑 html 调整任何样式细节很容易, 拿浏览器控制台就能做, 简单直观, 响应快速, 此后再转 pdf 时样式几乎一致
上个回复里, 已经能做到和没做到的如下
实时阅览视图里, 可以做到 标准分段+硬分段+二字符缩进 (通过 css 片段)
阅读视图里, 在不使用 Ob 的 js 脚本的前提下, 无法做到 标准分段+硬分段+二字符缩进
(若使用 Ob 内的 js 脚本, 道理跟下面第4点是一样的, 但建议先别搞等 pdf 落实了再说这个)
pandoc 直接 md 输出 pdf 做不到 标准分段+硬分段+二字符缩进 样式
Ob 阅读视图输出为样式一致的 html 很容易做到 (通过上述随便一个插件) 之后浏览器编辑 html 另存 pdf 很容易做到
Probe
2025 年12 月 20 日 12:03
13
之前的 pandoc 方案, 有个无法解析删除线问题, 在 --pdf-engine=pdflatex 里, 我实在整不出来,--pdf-engine=xeflatex 里实测还是能搞定删除线的, 需要 md 文档前面加上
---
header-includes:
- \usepackage[UTF8]{ctex}
- \usepackage[normalem]{ulem}
- \usepackage{xeCJKfntef}
- \renewcommand{\st}{\CJKsout}
---
然后别忘 插件 Enhancing Export 的自定义参数要改成 --pdf-engine=xelatex
测试文本
---
header-includes:
- \usepackage[UTF8]{ctex}
- \usepackage[normalem]{ulem}
- \usepackage{xeCJKfntef}
- \renewcommand{\st}{\CJKsout}
---
测试 ~~删除线~~ 位置
删除线在 [GitHub Flavored Markdown Spec](https://github.github.com/gfm/) ## 6.5Strikethrough (extension)
GFM 支持`划线延伸` ,此时可选择额外的重点类型。
```sh
划线文本是指任何被匹配的一对或两个波浪号(`~`)包裹的文本。
~~Hi~~ Hello, ~there~ world!
与常规强调分隔符一样,新增段落会导致删除解析停止:
This ~~has a
new paragraph~~.
三个或以上波浪不会形成划线:
This will ~~~not~~~ strike.
```
~~哈~~ 喽, ~世~ 界
与常规~~强调分隔符一样,
新增段落~~会导致删除解析停止
三个或以上~~~波浪~~~不会形成划线
导出效果
简单的删除线还行, 格式复杂之后, 一言难尽
所以个人觉得还是别 pandoc 了, 即使这问题解决了, 未来还不定多少问题在等着