概述
Obsidian 的 Bases(数据库)版本 1.9.10 已经发布,相信很多人会好奇——它有什么用?
本文用一个简单的例子来介绍它的用法,同时也作为“一步步跟着实现”的基础教程。
效果
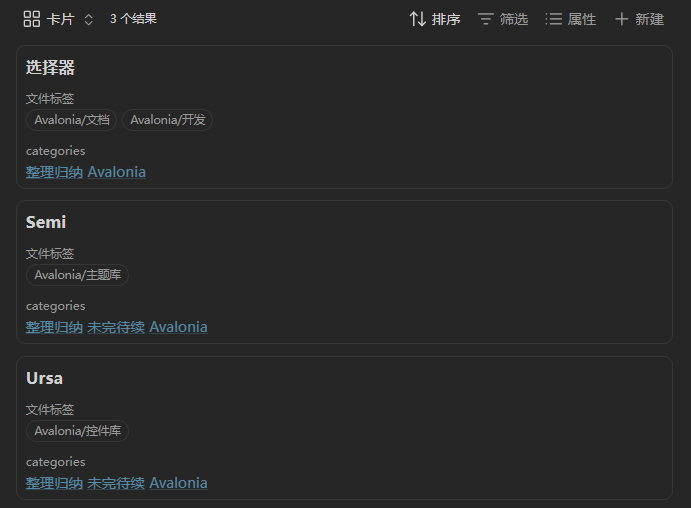
我们先看数据库实现的效果:
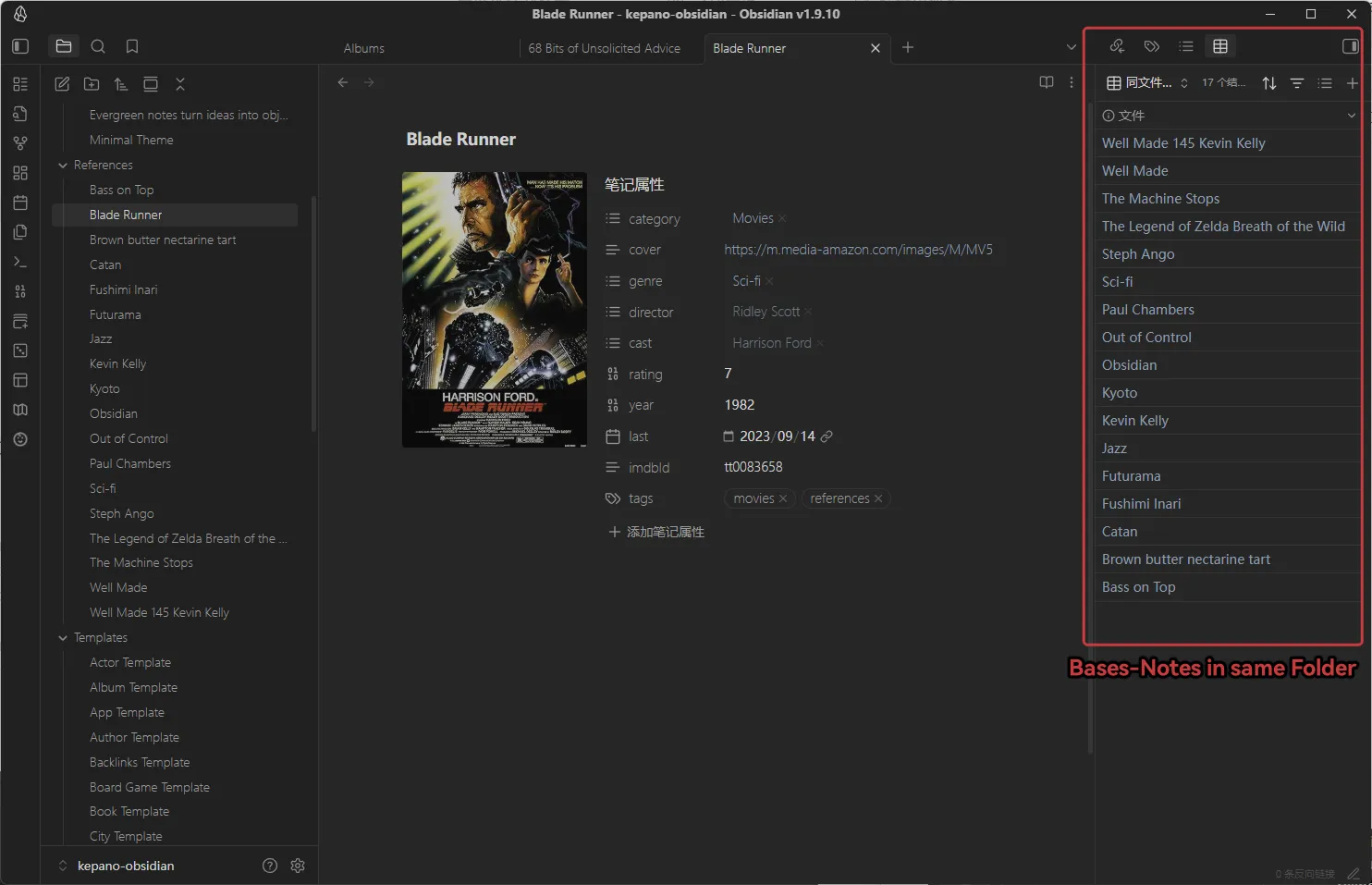
该库为 Kepano 的示例库
这个 Bases 的作用很简单:显示出和当前笔记相同文件夹的其他笔记
非常适合你在浏览笔记时,快速查看相关的其他笔记。
实现
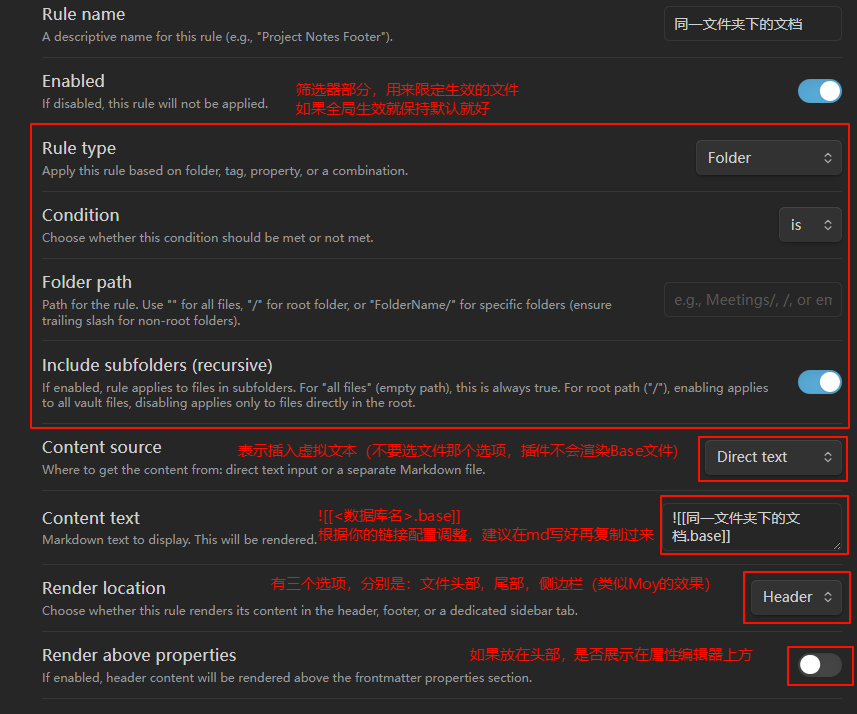
首先,在文件浏览器中右键,创建新的 Base 文件:
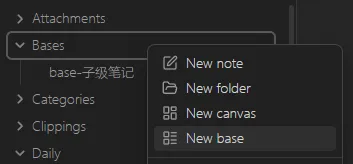
创建完后,为它取一个名字,例如 base-SameFolder
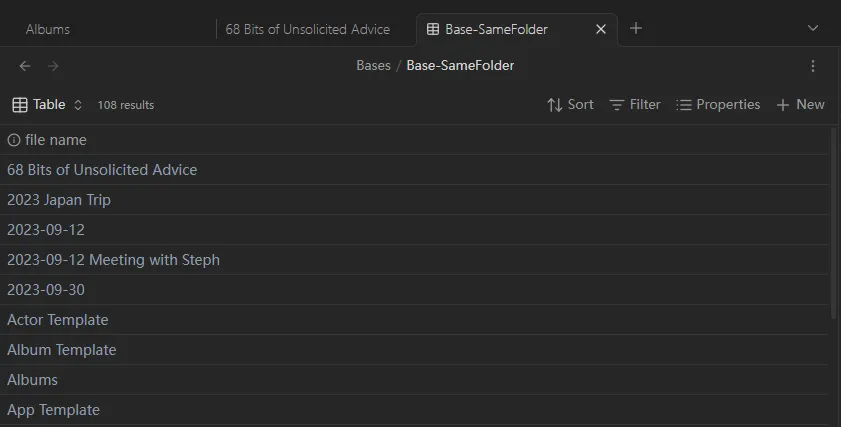
然后你会看到 Bases 的基础状态:
一个表格,包含你库中的所有文件。
接下来,我们要认识到最重要的两个基础概念:筛选 和 属性。
概念
数据库最重要的部分在最上方的操作区域,包含:
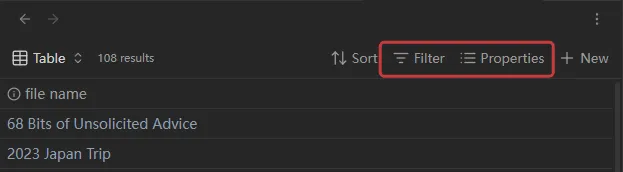
左上方:
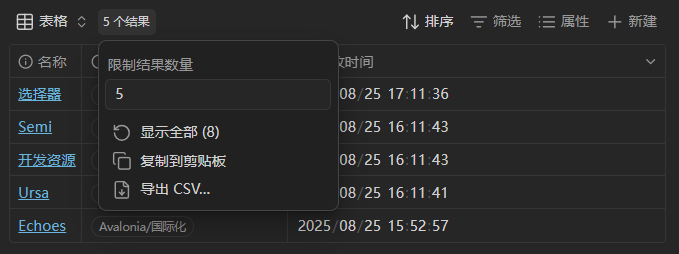
- 视图
- 结果(包括导出 CSV、结果数量限制等功能)
右上方:
- 排序
- 筛选
- 属性
- 新建
我们会先聚焦在最重要的 Filter 筛选器和 Properties 属性上。
筛选
筛选器,即定义“显示的条件”。
默认情况下所有文件都会被列出来,而过多的信息量等于无效的信息量。
所以我们需要定义好自己希望看到的内容。
在这次的案例中,条件即「和当前笔记相同文件夹」。
属性
每个文件有自己特定的属性,属性可以用在“筛选”的条件,也可以作为“显示的信息”。
属性除了笔记最上方的 Properties 属性区域中的属性,还包含一些隐性的元数据,例如文件路径、文件所在文件夹等。
对于这次案例,我们需要获取到 文件夹 属性。
实践
特定文件夹
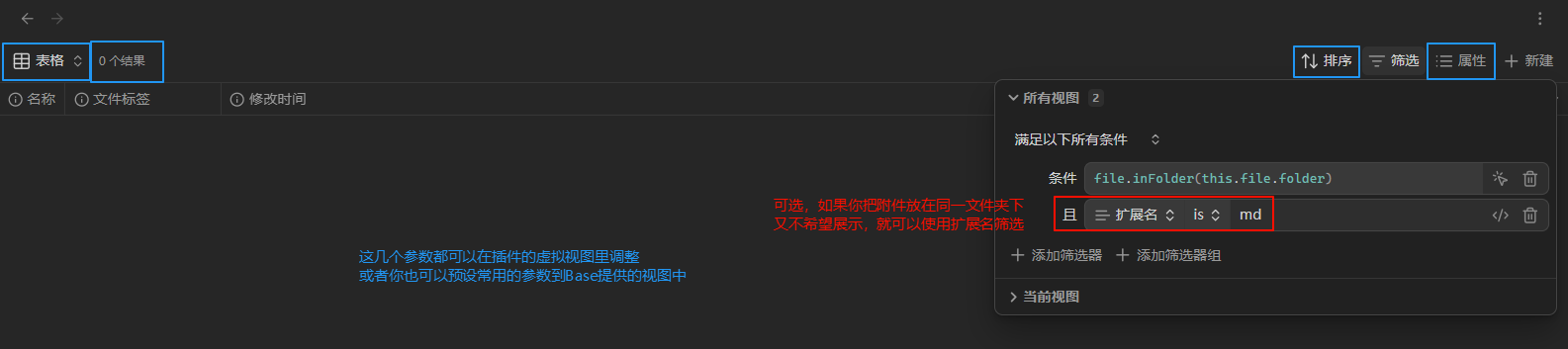
点击 Filter 按钮,会弹出筛选器的 UI。
我们打开 All views(对所有视图生效)筛选器,并且选择:
file | in folder 即“在特定文件中”。
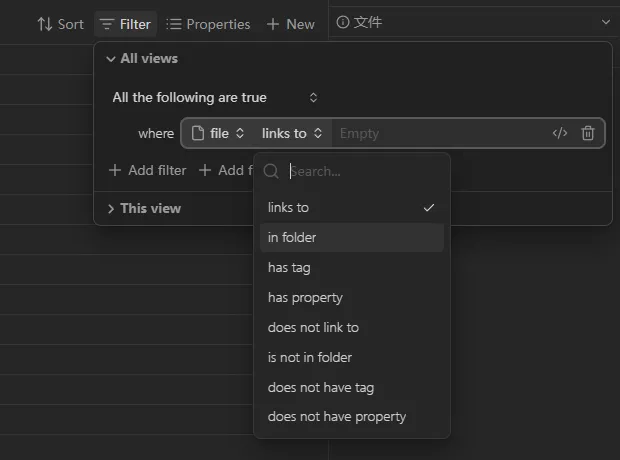
然后我们可以先手动输入一个文件夹(路径带有自动补全),查看效果:
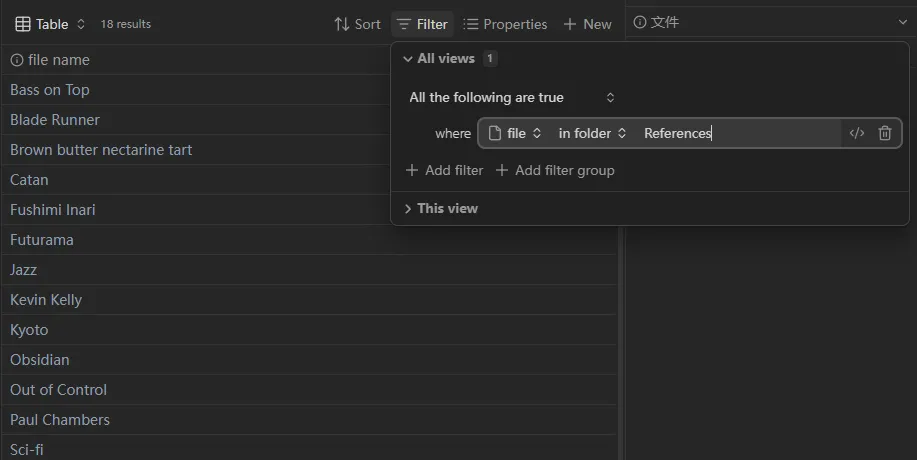
可以看到,这样配置之后,已经可以显示来自特定文件夹的笔记了。
为你 Bases 最重要的第一步喝采! ![]()
公式:动态筛选条件
但是我们想要实现的目标是:显示和当前笔记相同文件夹的笔记。
总不能每次都手动修改文件夹路径吧?
所以,我们需要更动态的筛选条件。
首先,点击右侧的 </> 按钮,
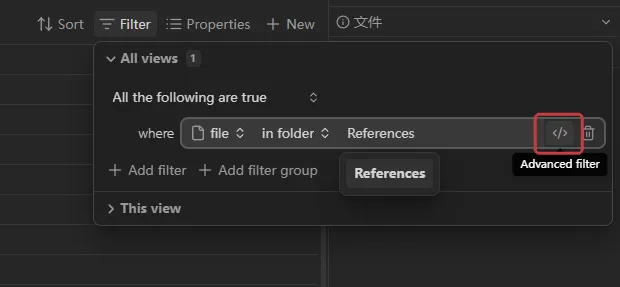
进入高阶筛选器的编辑界面:

可以看到,这时候筛选条件变成了一条公式:
file.inFolder("References")
它的含义和刚才的筛选器完全一致:file 位于文件夹 Reference 内。
公式有点儿类似 Javascript 代码,但是相对简单,你可以通过先构建简单过滤器,然后切换成高阶过滤器的方式来进行学习。
更多资料也可以查看:
这里的 file 指代每一个进行检验的文件,如果符合条件,就列进结果中。
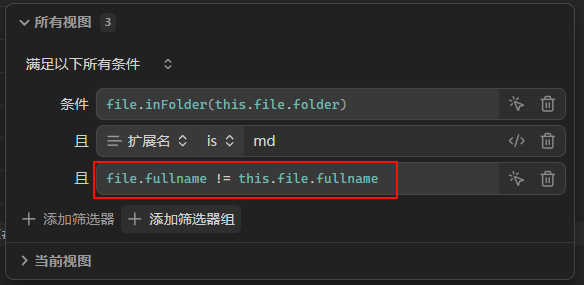
所以,我们下一步要做的是——把文件夹 Reference 换成实际的 当前笔记所在的文件夹。
具体来说,把 "Reference" 替换成 this.file.folder:
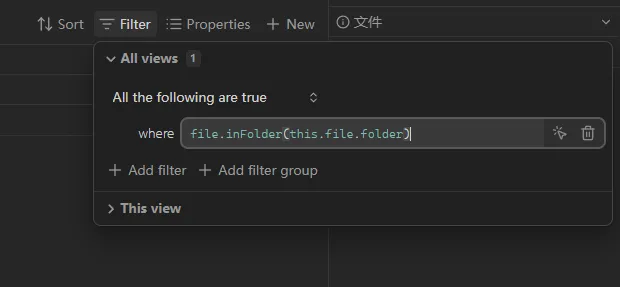
你可以先这样修改,看看结果,然后我们再说理论部分。
关于当前文件
如果一切顺利,在输入完毕后你会看到当前 base 文件所在的文件夹的文件:
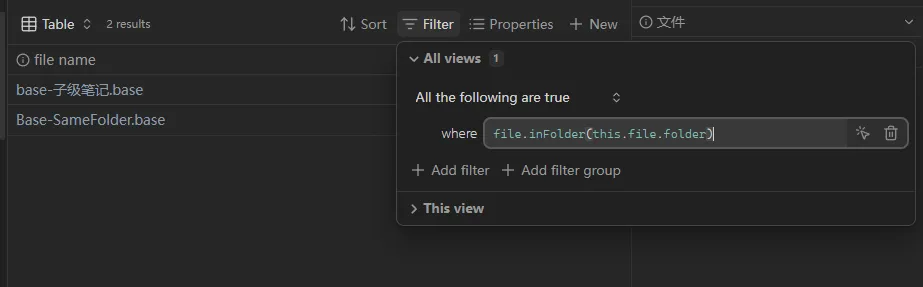
(可能只有它自己)
接下来我们就要介绍到 this 这个特殊的变量——
它代表“当前”的文件,但是这个“当前”取决于 Base 所在的位置。
举个例子,当前我们在主要编辑器编辑 Base,那么这个 base-SameFolder.base 就是当前文件。
但是,如果我们把 base 文件拖到侧栏,然后点击一下当前的笔记,事情就会发生变化——
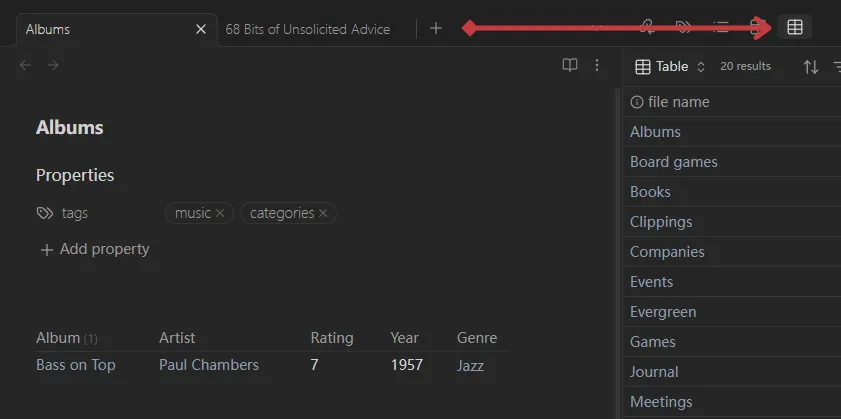
当 Base 位于侧栏或者分屏编辑器时,this 代表的就是当前激活的文件。
这是一个很重要的特性,也正是基于这个特性,我们才能实现“当前笔记所在文件夹的其他笔记”这个功能。
噢顺便一提,不知道你注意到了没,当你做到这里的时候,你已经实现了我们一开始想要完成的效果了 ![]()
恭喜! ![]()
原理和小技巧
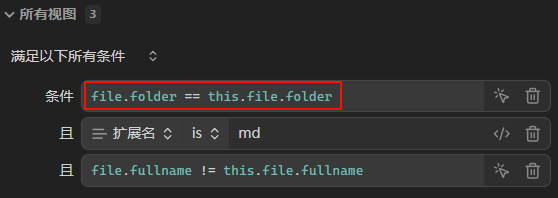
原理上来说,我们最终的筛选条件:file.inFolder(this.file.folder)
即我们先用 this.file 获取到当前激活的笔记的“文件对象”,然后再通过 .folder 获取到它的文件夹信息。
这里有一个小技巧,你可以点击 Properties → Add Formula 添加公式属性:
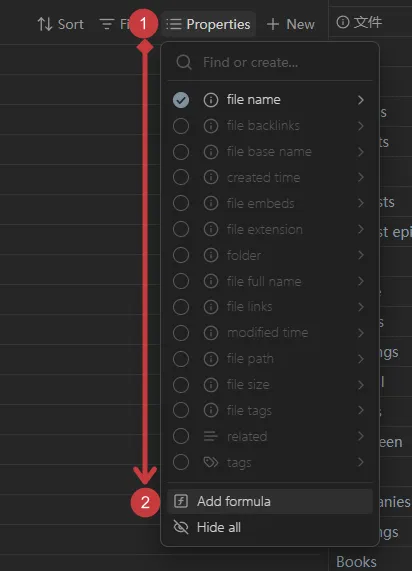
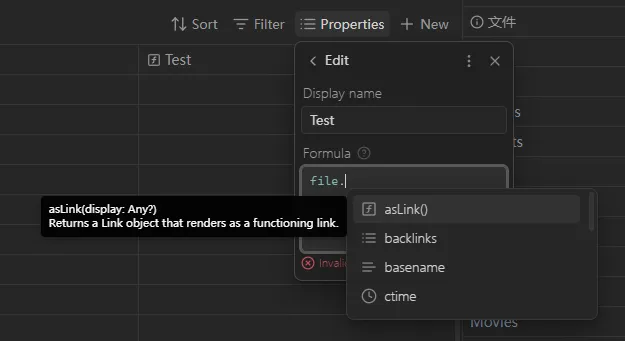
输入 file. 后你会看到它具有的各种属性:
输入完整的 file.folder 时,就可以看到每个文件的该属性:
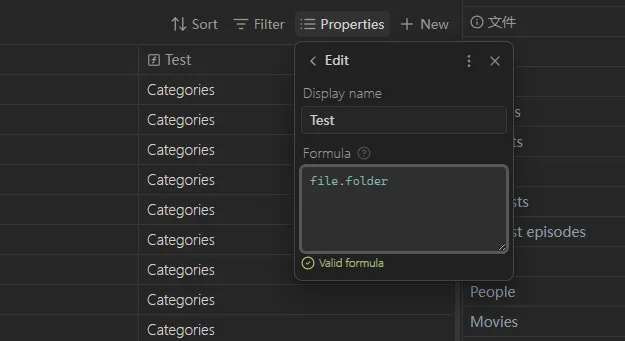
——这也是一个测试 bases 公式的实用技巧,多试试其他属性吧!
总结
这次我们尝试了:
- 创建一个新的数据库文件
- 添加筛选条件,来显示出我们想要的笔记
- 通过移动 base 到侧栏,来获得动态的筛选结果
- 同时,了解了基础的文件属性
希望这篇文章能作为你的 base 之旅的轻松起步,祝你玩得愉快~
Moi moi! ( ̄▽ ̄)ノ
资料
这里是一些相关资料,可以作为拓展学习。
Base 文档
Bases syntax - Obsidian Help
base 的基础语法,建议在实践完之后(或者之前)先查看该文档,获取扎实的基础知识。
在 Properties 章节,你可以看到笔记属性和文件属性的介绍;
在 Functions 页面,你可以看到关于公式/函数的介绍和应用。
示例库
kepano/kepano-obsidian
Kepano 分享的 Obsidian 示例库,他已经将库中的筛选都换成了 bases 数据库形式,你可以在里面学习到很多用法。