要管理海量 “标签”, 就要建设一个 “受控词表” 体系。建设 “受控词表” 体系, 就是明确标引出词项的如下属性的值
| order |
ob-property-name |
name |
descriptor-prop-id |
| 1 |
主题词-英文 |
英文 |
03 |
| 2 |
主题词-同义词 |
同义词 |
05 |
| 3 |
主题词-上位词 |
上位词 |
06 |
| 4 |
主题词-下位词 |
下位词 |
07 |
| 5 |
主题词-相关词 |
相关词 |
08 |
| 6 |
主题词-分类 |
分类 |
31 |
| 7 |
主题词-来源 |
来源 |
|
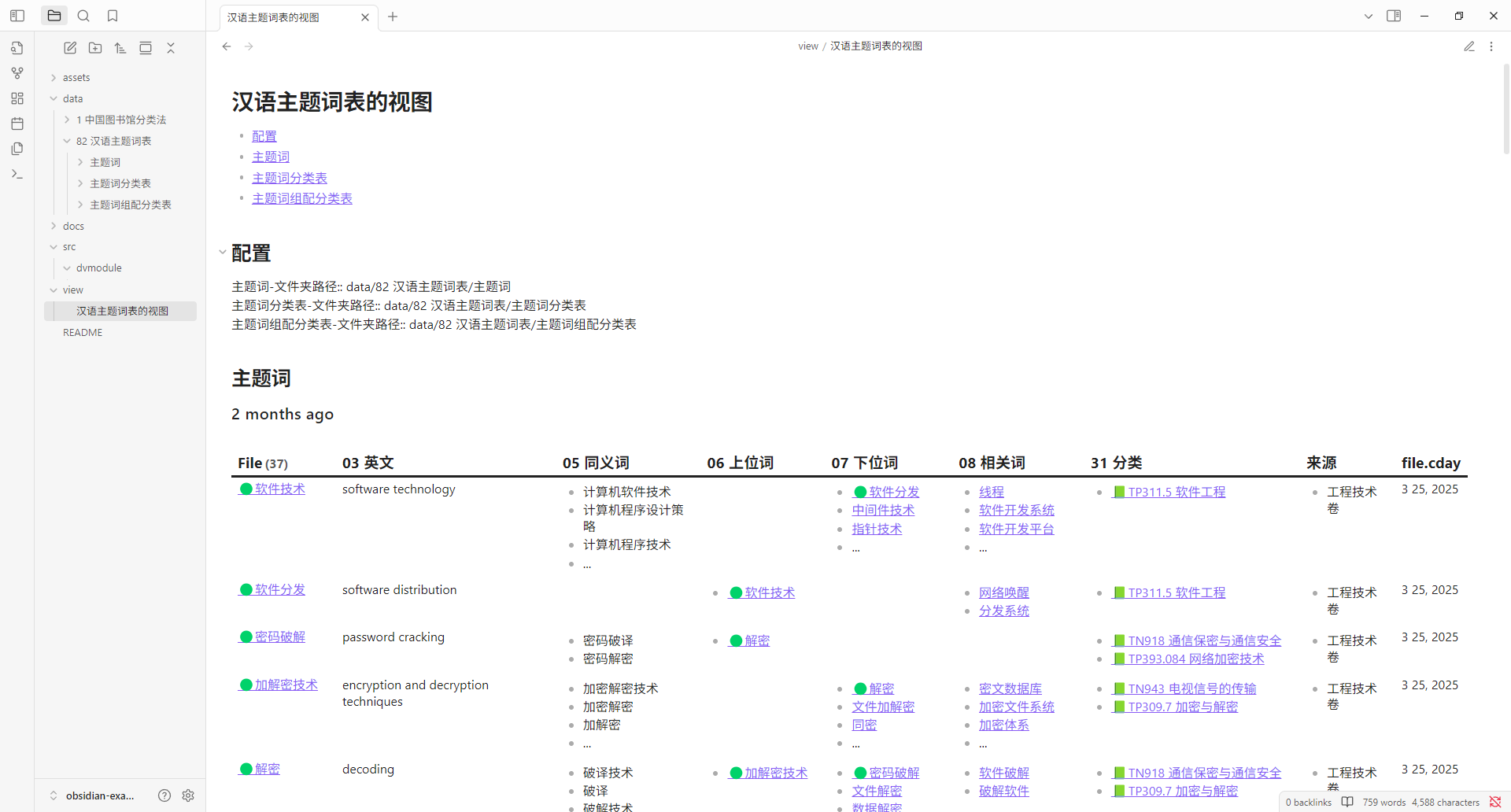
所以,我创建了一个《汉语主题词表OB示例库》 ,托管在 github。其视图预览如下所示。
更多信息,请参见我的《汉语主题词表OB示例库》的网址:
2 个赞
Ryooo
(Roy)
2
好东西。其实不止 ob,现在的软件在标签管理方面缺陷都非常大。这么搞下来算是弥补了这一方面的缺陷了。
不过反过来说, 直接在每个主题词笔记下记录相应的内容,就可以抛弃标签、直接管理笔记了 
3 个赞
我认为,在每个主题词笔记下直接记录相应的内容不符合“高内聚低耦合原则”,可能会降低可维护性和可拓展性。
并且,在组织笔记文献的过程中,对笔记的 “标引” 和 “编目” 不仅仅要使用 “主题检索语言”,还需要 “分类检索语言” 和 “代码检索语言” 。
比如,我的管理方式就是将一个文件夹当成一个数据库的数据表来管理笔记。一个例子的具体过程如下
步骤一、写出数据库标准文档。
设计读书笔记数据库 book,约定将读书笔记文件放在 data/literature/book, 构建出读书笔记的记录的范式 book(标题,摘要,关键词,分类号,配图,创建时间, 书籍作者,……其他属性),
| 字段名 |
字段内容的类型 |
| 标题 |
自由词(字符串) |
| 摘要 |
自由词(字符串) |
| 关键词 |
一个主题词表的受控词(如 软件技术 ) |
| 分类号 |
一个分类表的受控词 (如 TP393 ) |
| 配图 |
图片代码表的受控词 (如 [[图片01.png]] ) |
| 创建时间 |
时间代码表的受控词 (如 2025-01-02T13:04:05.678Z ) |
| 书籍作者 |
作者代码表的受控词 (如 [[作者01]] ) |
| ……其他属性 |
|
步骤二、对已有的读书笔记文献进行标引和编目
- 标引:填写相应的字段属性,如标题,摘要,关键词,分类号,配图,创建时间, 书籍作者,……其他属性
- 编目:根据自己的需要和库里已有的信息,创建存放书目或目录的笔记,
- 其形式可以是保存的动态查询 比如
```query
path: "data/literature/book/" [关键词:软件技术]
```
- 也可以是一些相关笔记链接构成的MOC(相当于综述论文,倒排索引)
1. [[软件技术书籍01]] | 书籍描述01
2. [[软件技术书籍02]] | 书籍描述02
3. [[软件技术书籍03]] | 书籍描述03
1 个赞
Ryooo
(Roy)
4
理解为 wiki 就好。我之前也是从你这套方法过来的,转为 wiki 式记录以后,在记录、整理和检索上都轻松了很多:
- 用受控语言来作为笔记标题。这样 ob 的别名功能就可以天然的处理语词同形异义和同义异形的问题。也方便了后期的检索,毕竟基于需要查找的主题就可以知道所需的标题,然后就可以仅通过快速切换到达所需笔记。同时也可以通过属性来构建笔记间的种属关系。
- 由于检索方便,就可以在记录新内容时轻松地知道库内是否已经记录过类似笔记,从而避免冗余记录。
- 基于受控的标题,双链笔记软件的出、入链功能也能被自然应用起来——在其他笔记的行文过程中,可以自然地提到一些词语,从而让相关笔记不经意间产生了联系。
我更倾向于把上述过程视为针对知识的管理,而对笔记加分类号、加主题词的管理方式视为文献管理。针对知识的管理比针对文献的管理,麻烦一些的地方就在于每篇笔记只应该聚焦于一个主题,而不能像文章一样随心所欲地记录不同主题的内容。
2 个赞
2025-09-08 - 《汉语主题词表》OB示例库现已发布成如下的网站
网站内容包含:
- 《中国图书馆分类法》所有类目
- 《汉语主题词表》主题词(数十个主题词)
- 相关的其它笔记
网站内容文件是通过使用 Obsidian 插件 Webpage HTML Export 在 2025-09-07 时生成的
2 个赞
“主题检索语言”,“分类检索语言” 和 “代码检索语言” 是什么?
检索语言是根据信息检索的需要创造出来的一种人工语言,是在文献检索领域中用来描述文献特征和表达信息检索提问的一种专用语言。
检索语言有如下的种类
一、自然语言(关键词、题名即标题、全文、引文、作者和摘要等)
二、人工语言(分类检索语言、主题检索语言、代码检索语言)
所以,“主题检索语言”,“分类检索语言” 和 “代码检索语言” 是人造的检索语言。
直白的说,“主题检索语言”,“分类检索语言” 和 “代码检索语言” 就是 3 种存放人造检索符号的关系数据库的【表格】
“主题检索语言”,“分类检索语言” 和 “代码检索语言” 的特点对比
- 分类检索语言:检索符号 E8 具有字母数字交叉叠加和前缀表示上位类语义的特点
- 主题检索语言:检索符号 工具软件 具有直观易读和有语义的特点
- 代码检索语言:检索符号 M4555 有不可读的特点
“主题检索语言”,“分类检索语言” 和 “代码检索语言” 怎么用?
- 步骤1:阅读相关的标准文档学会标引的方法,比如 “ 中华人民共和国国家标准《文献叙词标引规则》 (GB/T3860-1991 )”
- 步骤2:打开运营相关数据库的网站,查阅检索标识,比如 “《汉语主题词表》 服务系统 https://ct.istic.ac.cn )
- 步骤3:根据文献的内容特征,将相应的检索标识写入文档的元数据,比如将 “工具软件” 写入文档 “论工具软件.md” 的 frontmatter 的 “keywords” 属性
“主题检索语言”,“分类检索语言” 和 “代码检索语言” 具体是什么样的?
下面是几个关于检索语言的例子
分类检索语言
例子1:《中国图书馆分类法》
检索符号 E8 指的就是如下表格中的 “E8 战略学、战役学、战术学” 那一行
检索符号 E8 具有字母数字交叉叠加和前缀表示上位类语义的特点
| ID |
名字 |
上位类 |
英文 |
| …… |
…… |
…… |
…… |
| E |
E 军事 |
|
Military affairs |
| E8 |
E8 战略学、战役学、战术学 |
E |
Science of strategy,science of campaigns and science of tactics |
| E81 |
E81 战略学 |
E8 |
Science of strategy |
| …… |
…… |
…… |
…… |
主题检索语言
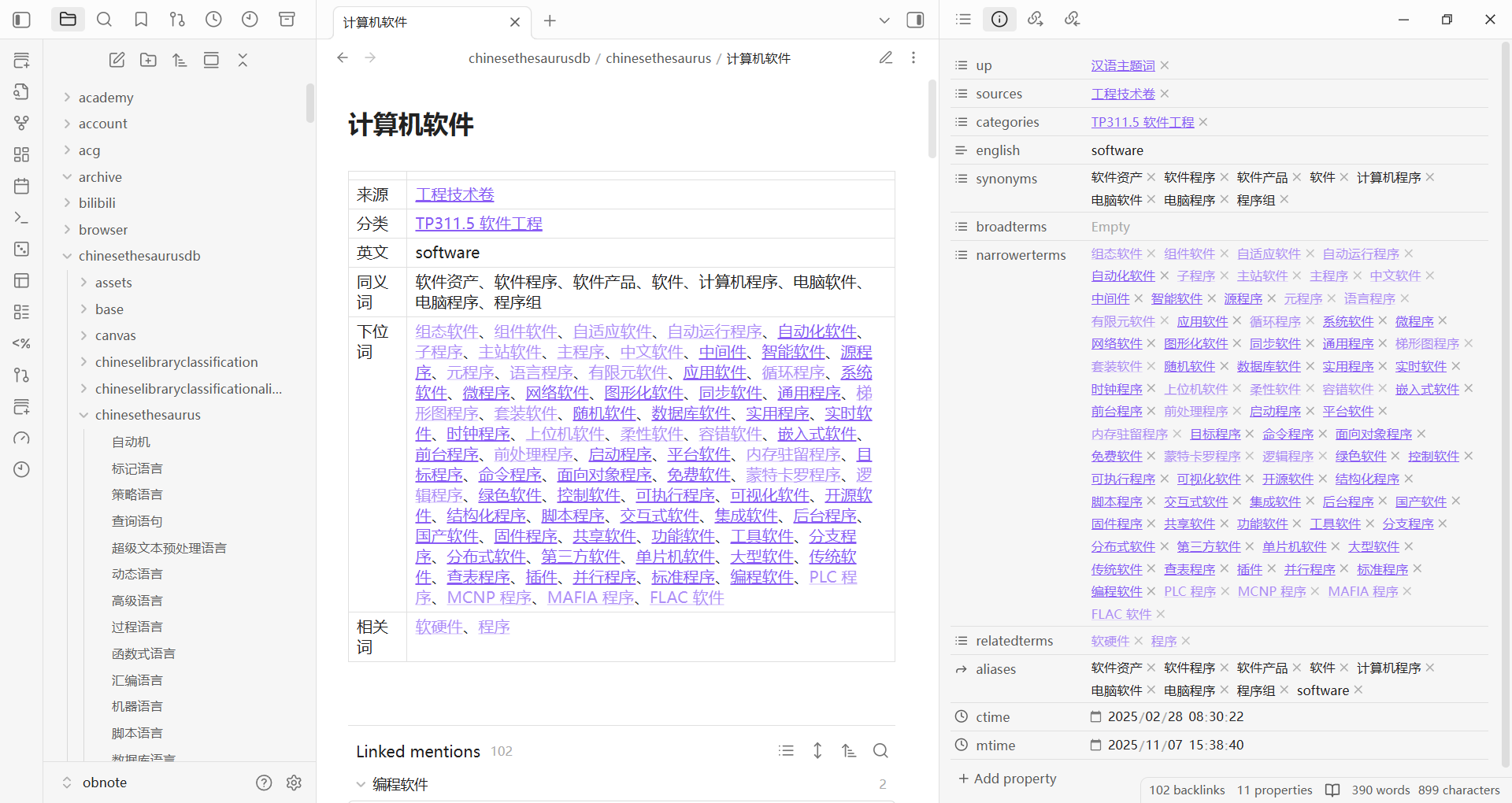
例子2:《汉语主题词表》
检索符号 工具软件 指的就是如下表格中的 “工具软件” 那一行
检索符号 工具软件 具有直观易读和有语义的特点
| ID |
来源 |
分类 |
英文 |
同义词 |
上位词 |
下位词 |
相关词 |
| …… |
…… |
…… |
…… |
…… |
…… |
…… |
…… |
| 计算机软件 |
工程技术卷 |
TP311.5 软件工程 |
software |
软件资产、软件程序、软件产品、软件、计算机程序、电脑软件、电脑程序、程序组 |
|
组态软件、组件软件、自适应软件、自动运行程序、自动化软件、子程序、主站软件、主程序、中文软件、中间件、智能软件、源程序、元程序、语言程序、有限元软件、应用软件、循环程序、系统软件、微程序、网络软件、图形化软件、同步软件、通用程序、梯形图程序、套装软件、随机软件、数据库软件、实用程序、实时软件、时钟程序、上位机软件、柔性软件、容错软件、嵌入式软件、前台程序、前处理程序、启动程序、平台软件、内存驻留程序、目标程序、命令程序、面向对象程序、免费软件、蒙特卡罗程序、逻辑程序、绿色软件、控制软件、可执行程序、可视化软件、开源软件、结构化程序、脚本程序、交互式软件、集成软件、后台程序、国产软件、固件程序、共享软件、功能软件、工具软件、分支程序、分布式软件、第三方软件、单片机软件、大型软件、传统软件、查表程序、插件、并行程序、标准程序、编程软件、PLC 程序、MCNP 程序、MAFIA 程序、FLAC 软件 |
软硬件、程序 |
| 工具软件 |
计算机软件 |
TP311.561 软件工具 |
tool software |
软件开发工具、软件工具、计算机程序工具、工具程序 |
计算机软件 |
自适应预测器、自动生成器、转换程序、抓取器、注册机、中介器、支撑软件、诊断软件、运行支撑系统、远程控制软件、优化软件、应用生成器、应用开发工具、压缩软件、选择程序、虚拟软件、修改器、信息管理器、卸载程序、显示程序、系统文件检查器、网络工具软件、托盘程序、搜索器、搜索工具、数据挖掘工具、数据库开发工具、事件处理程序、设计器、筛选器、软键盘、软件测试工具、驱动程序、破解软件、浏览器、量化器、链接器、联锁软件、类装载器、类驱动器、课件制作工具、刻录软件、可视化工具、开发工具、解压缩软件、解码软件、结构软件、接口程序、建模工具、检测程序、加载器、加密软件、记录软件、恢复软件、还原软件、管理器、共享器、格式刷、辅助工具、服务程序、分析软件、分发器、读写程序、迭代器、调度程序、电子设计自动化工具、电算软件、代码生成器、创作工具、串行程序、产品配置器、查询优化器、查看器、插补程序、补丁程序、编码程序、本体构建工具、备份软件、安全软件、Linux加载程序 |
软件技术、工具总线 |
| 搜索工具 |
工程技术卷 |
TP311.569 其他软件工具 |
search tool |
工具软件 |
|
|
网络爬虫、搜索器、搜索模型、搜索机制、搜索服务、搜索窗口、搜索策略 |
| …… |
…… |
…… |
…… |
…… |
…… |
…… |
…… |
代码检索语言
例子3:merckindex (分子式索引)
检索符号 M4555 指的就是如下表格中的 “Dimethyl Sulfoxide” 那一行
检索符号 M4555 有不可读的特点
| Monograph ID |
Title |
UNII |
Molecular formula |
Molecular weight |
Percent composition |
Standard InChI |
Standard InChIKey |
| …… |
…… |
…… |
…… |
…… |
…… |
…… |
…… |
| M4555 |
Dimethyl Sulfoxide |
YOW8V9698H |
C2H6OS |
78.13 |
C 30.75%, H 7.74%, O 20.48%, S 41.03% |
InChI=1S/C2H6OS/c1-4(2)3/h1-2H3 |
IAZDPXIOMUYVGZ-UHFFFAOYSA-N |
| …… |
…… |
…… |
…… |
…… |
…… |
…… |
…… |
回复 受控词是用来一致化文献描述的吗?例子里没看到有标签的使用,但标题里有
- 受控词不是用来一致化文献描述的,而是用来提升信息检索的准确性和一致性
- 这个话题的中心是 ”标签“ 的管理和受控词表的建设,而不是标签的使用方法
检索语言明白了 
不过标签在 ob 里指的是 tag,比如 #进行中,这种也需要标准化吗?
自己设计一个受控词表就可以了
比如在文件 “状态.md” 写下
# 状态
## 标签
| 标签名 | 同义词 | 描述 |
| --- | --- | --- |
| #代办 | todo | 还没有开始的项目 |
| #进行中 | doing | 已经开始,正在进行中的项目 |
| #已完成 | done | 已经完成的项目 |
或者写下
# 状态
## Wiki链接
| 链接 | 同义词 | 描述 |
| --- | --- | --- |
| [[代办]] | todo | 还没有开始的项目 |
| [[进行中]] | doing | 已经开始,正在进行中的项目 |
| [[已完成]] | done | 已经完成的项目 |
或者将一个文件夹"data/状态/"作为一个数据库表格,将相关的属性写好
可用的工作流
| 待办 |
进行中 |
已完成 |
已取消 |
| todo |
doing |
done |
canceled, cancelled |
| later |
now |
done |
canceled, cancelled |
| wait, waiting |
in-progress |
done |
canceled, cancelled |
1 个赞
吼吼,明白了,感觉是自定义词典啊,用于标准化用词的
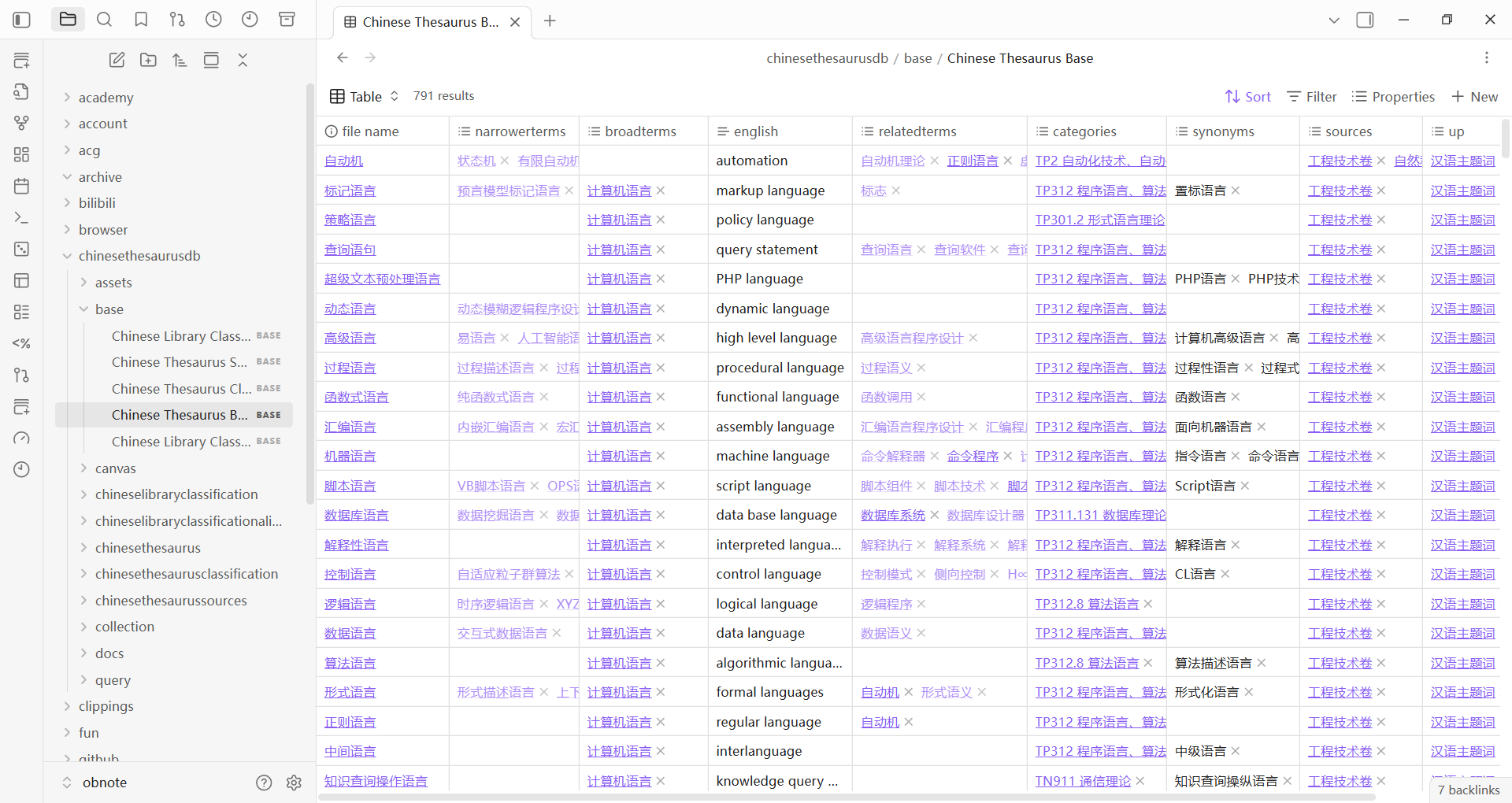
分享一个自己写的油猴脚本,可以自动将《汉语主题词表服务系统》的主题词的网页剪藏成 Obsidian Markdown 文件(用一秒就可以剪藏一个主题词)
截图:最近的进展
1. Base视图截图:已经剪藏了 791 个主题词
2. 笔记截图:对 “主题词计算机软件” 的笔记