请仔细说明自己遇到的问题,以下是参考模板。这里不要求非得按模板发帖,但内容中包含相关要素能让大家更好地帮助你。
遇到的问题
小红书网页版的文章有很多的表情符号,复制到obsidian新建页时这些表情图片显示为
!(https://xxxx)的链接,要手动一个个的删除,效率太慢了。
预期的效果
有没有能批量删除单个页中所有!(https://xxxx)的方法或是插件?新手小白真诚求教!!!
已尝试的解决方案
试着在各个视频平台搜寻类似的问题,但可能是我对软件背后的语言原理不熟悉的缘故,没有找到与我类似的案例和解决方法,或者是我没用对关键词搜索,很抱歉!
1 个赞
只看描述,用正则表达式可以做到。但目前 Obsidian 没有内置的通配替换,需要使用其他插件或软件来实现,有图形化的也有通用的,你可以使用类似关键词搜索,找个自己喜欢的。‘批量 正则 查找’ 的搜索结果 - Obsidian 中文论坛
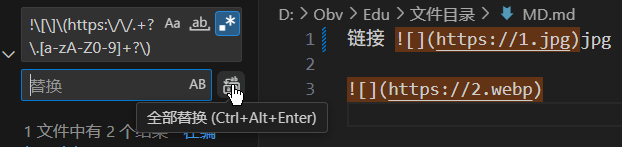
只说正则表达式就是这个了 !\[\]\(https:\/\/.+?\.[a-zA-Z0-9]+?\)。如果不是这个就和 AI 描述需求让 AI 帮忙写正则吧。
用正则表达式处理,你可以使用quickadd或者template执行下面这串代码
// 获取当前编辑器实例
const editor = app.workspace.activeEditor.editor;
// 获取当前文档的全部内容
const content = editor.getValue();
// 定义正则表达式,匹配 Markdown 图片语法 
const markdownImageRegex = //gi;
// 清除匹配到的图片语法
const newContent = content.replace(markdownImageRegex, ‘’);
// 将处理后的内容写回编辑器
editor.setValue(newContent);
quickadd在当前页面使用js代码的方法:
- 进入quickadd插件的控制页面
- 下方add添加一个capture(注意命名)
- 随后点击新capture一旁的小齿轮,在新出现的页面中①开启Capture to active file,②随后开启Capture format
- 为了让quickadd识别这是js代码,需要用js quickadd代码框的格式把代码框起来,比如本次的代码:
```js quickadd
const editor = app.workspace.activeEditor.editor;
const content = editor.getValue();
const markdownImageRegex = /!\[.*?\]\(.*?\)/gi;
const newContent = content.replace(markdownImageRegex, '');
editor.setValue(newContent);
```
可以直接复制粘贴
- 点击小闪电让capture能够在obsidian命令中显示
- 在你需要的网页,按下ctrl+P,随后搜索到这个capture的名称,点击就可以了
linter插件,支持正则。 正则具体这么写,问AI就行
还可以用cursor或者trae这类编辑器打开,让AI给你写个python脚本,可以用来批量处理文件夹内的所有笔记。