一直想找寻一款好用的ChatGPT国内代理,但目前国内代理太多了,良莠不齐,用过好几款,但都因各种原因放弃了。
GPT 第三方 API 推荐
直到遇到了它 V3API
优点
- 能用的模型多:使用标准的OpenAI接口协议访问68+模型,支持ChatGPT(所有模型)、Claude3.5、Gemini、Glm-4等系列最新模型,支持联网、绘画、语音等多种功能。

更多支持模型请看这里
支持的模型列表
gpt-3.5-turbo
gpt-3.5-turbo-0125
gpt-3.5-turbo-1106
gpt-3.5-turbo-16k
gpt-3.5-turbo-instruct
gpt-4
gpt-4-0125-preview
gpt-4-0613
gpt-4-1106-preview
gpt-4-32k
gpt-4-32k-0613
gpt-4-all
gpt-4-gizmo-*
gpt-4-turbo
gpt-4-turbo-2024-04-09
gpt-4-turbo-preview
gpt-4-vision-preview
gpt-4o
gpt-4o-2024-05-13
gpt-4o-all
gpt-4o-mini
gpt-4o-mini-2024-07-18
claude-3-5-sonnet-20240620
claude-3-haiku-20240307
claude-3-opus-20240229
claude-3-sonnet-20240229
dall-e-2
dall-e-3
deepseek-chat
deepseek-coder
gemini-1.5-flash
gemini-1.5-flash-latest
gemini-1.5-pro
gemini-1.5-pro-latest
gemini-pro
gemini-pro-vision
glm-4
google-palm
mj-chat
moonshot-v1-128k
moonshot-v1-32k
moonshot-v1-8k
n-gpt-4o
net-gpt-3.5-turbo
net-gpt-3.5-turbo-16k
net-gpt-4
net-gpt-4-0125-preview
net-gpt-4-32k
net-gpt-4-turbo
search-gpts-chat
stable-diffusion
suno-v3
suno-v3.5
text-ada-001
text-babbage-001
text-curie-001
text-davinci-002
text-davinci-003
text-davinci-edit-001
text-embedding-3-large
text-embedding-3-small
text-embedding-ada-002
text-embedding-v1
text-moderation-latest
text-moderation-stable
tts-1
tts-1-hd
whisper-1
或这里查看模型列表及价格
-
价格便宜透明:对于使用 GPT4 来说,官网按月购买价格昂贵,且国内用户不易操作,还会有封号风险,而使用第三方API 则不会有封号风险,不限时间不限每日使用次数、按量计费、价格公道,人民币兑美刀比例大概在 2.0-2.5:1 左右(意思是1刀=2.00~2.5元),可参考上面的价格列表。
-
插件众多:它支持非常多的插件,包括utools插件,Chatbox插件,BotGem(移动端),ChatAir(安卓端),ChatGPTBox(浏览器)等。
GPT 第三方插件推荐
utools 的 GPT 好友,文档见链接
- 支持建立根据 prompt 建立并保存多个角色进行对话,支持清空对话后保留之前单个角色的聊天记录
- 完美兼容第三方的 v3 API,可以查询 v3 API 的使用余额
- 支持上传图片,支持 AI 绘画
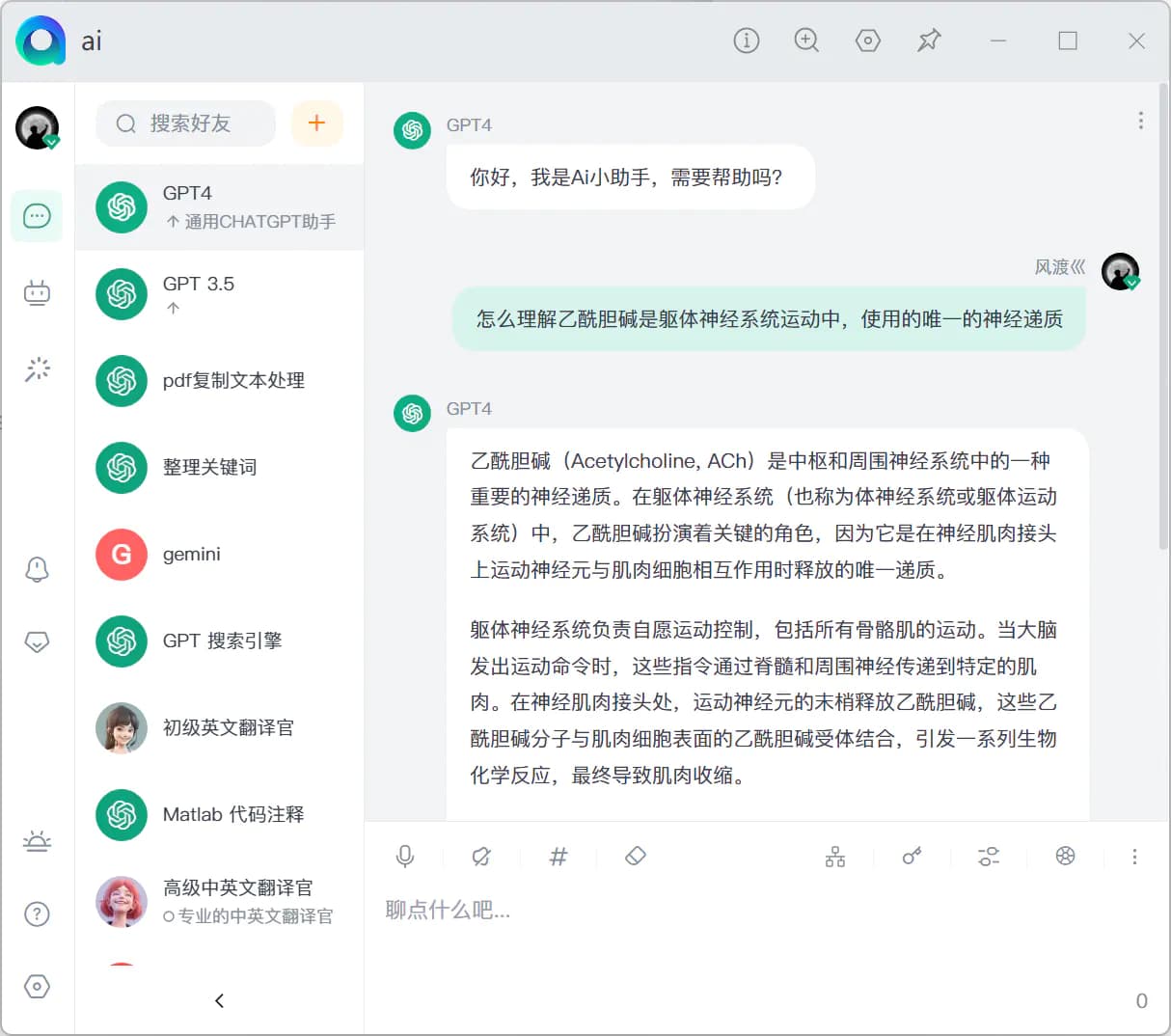
Chatbox,官网见链接
- 支持根据 prompt 建立并保存多个角色进行对话,根据建立 thread 的方式来重新新建 context 对话,之前的对话依然保留在页面上,能滚动查看
- 有网页端、桌面端和安卓端,支持导出所有数据
- 支持上传图片,支持绘画
- 对第三方 API 的兼容稍差
更多插件支持查看这里
ChatGPT.好友 (推荐)
OpenAI官方库
NextChat
ChatBox
LobeChat
BotGem(移动端)
ChatAir(安卓端)
ChatGPTBox(浏览器)
CodeGPTGPT
VSCode沉浸式翻译
或到这里查看插件列表及使用方法
GPT API调用支持
完全兼容OpenAI接口协议,支持无缝对接各种支持OpenAI接口的应用。
所有聊天模型(包括非openai模型)都支持openai官方库,请求url和格式请都遵循openai的请求方式。
详细使用方法请看 V-API - 为您提供稳定可靠的Openai ChatGPT、Gemini、Claude、Deepseek、Grok、openclaw等API直连中转服务!
省钱小技巧
要想省钱,我们首先得了解计费方式。
要了解计费方式,首先得了解几个概念。
提示(prompt),顾名思义,就是你的问题了,加上你对问题背景的描述和要求。
补全,就是ai给你的回复的答案。
tokens,一个单词就是一个tokens,一个中文是一个tokens,一个标点符号也是一个tokens。
基准,就是 价格/1K tokens 为基础,计算某个模型的收费标准与它的关系。
倍率,就是把当前模型的收费标准与基准对比,计算出来的倍数关系。
模型倍率,不同模型的收费价格不一样,与基准的倍数关系就是模型倍率。
补全倍率,就是回复价格和提示价格之间的倍数关系。
倍率的目的主要为了直观的感受某个模型的价格,比如倍率越高,通常价格越贵,也意味这模型可能更强大,模型的维护成本可能更高。
然后有了这些概念,我们就可以自己计算每个模型收费是怎样的了。
比如:gpt-4o
模型倍率:2.5
提示 $0.005 / 1K tokens
补全倍率:3
补全 $0.015 / 1K tokens
1K tokens可以大致理解1000个字,模型倍率2.5说明比基准收费高2.5倍,补全倍率3说明回复的费用是提示词费用的3倍。这里基准是$0.0.2,这个基准值一般是根据市场和成本精细计算出来的,是个常数,通常不会变。
注意,这里的美元不是按美元比人民币 ,1比7.x去算的,这里的美元比人民币是1比2.0-2.5,这样的话,实际上同样的钱能买到更多的tokens。
然后我们根据公式算算这个模型每1k tokens多少钱?
根据公式:按量计费费用 = 分组倍率 x 模型倍率 x (提示token数 + 补全token数 x 补全倍率)/ 500000
注意:这里的分组倍率一般指不同用户群体或使用场景的不同收费标准,比如,企业用户和个人用户,教育行业和商业行业可能会有不同的分组倍率。这里的500000是一个常数,用来将计算结果标准化。这个数值之所以选择500K也是综合计算出来的,使得计算结果不会出现很多小数点,易于理解和对比,也使费用结果会更加直观,用户看起来更易接受。
好了,按量计费费用 = 1 x 2.5 x (1000 + 1000 x 3) / 500000 = 0.02 美元
然后对比下上面的价格,是不是就是: 提示$0.005 / 1K tokens + 补全 $0.015 / 1K tokens = 0.02 美元了。
巧了,好像刚好就是基准价格,哈哈哈。
然后再转换为人民币,这里按 2.25汇率 x 0.02 = 0.045人民币。
这说明,你的问题1000字,加回复1000字,然后选择gpt-4o模型,一次回答需要花费0.045人民币。
嗯,感觉是不是还是挺贵的,但通常你的问题极少出现1000字的情况,回复1000字以上的情况也不多,chatgpt的回复还是挺简洁的。
那么,知道了这些,怎么省钱相信你也知道了,我们能操作的空间,也只有 减少提示词和选择模型了,还有就是减少提问次数。
从这三点出发我们看看:
减少提示词,就是你的提示词尽可能的短且明确。不需要用多余的词,比如客套,寒暄,直接问你的核心问题就行。ai不是人,没有感情,更不理解文字本身,只是基于算法的文本时输出而已,说白了和小狗做算术类似。
选择模型,这个就需要根据自己的需求,选择合适的模型了,以达到性价比最高。
减少提问次数,这是本次省钱的重点,无论什么模型,减少提问次数肯定是最省钱的办法了。
那么这就涉及到优化提示词了,优化提示词,能让你用最少的提问,得到最好的回复,而不需要反复问,这样就能最大程度的为你省钱。
具体优化措施有(但不限于这些)
明确和具体: 确保你的提示词清晰明确,避免模糊或歧义的词语。
提供上下文和背景: 提供足够的上下文和背景信息,以帮助AI理解你的需求。例如,提供一些背景信息或具体的例子来说明你所需要的内容。
分步骤引导: 如果任务复杂,可以将其分解为几个步骤,每个步骤单独提示。例如,先让AI生成一个大纲,然后再让它扩展每个部分。
使用示例: 给出你希望的输出格式或风格的示例。
使用专业术语: 领域特定词汇可以帮助AI更好地理解问题。
结构化提示: 格式化你的问题,使其结构更清晰。
限制条件: 如果有必要,可以添加限制条件来约束生成的内容。
使用模板: 反复迭代,找到最好的提问方式,针对不同的场景或问题类型使用相应的模板。
总之,优化提示词就是经验之谈了,不同模型和行业可能有所不同,可以自己找资料学习学习。
也可参考这篇文章:https://ld246.com/article/1696246170187
还有一点,我们要注意,gpt是按token收费的,会话历史也是提示词的一部分,因此,为了减少提示词数,尽可能的减少历史或不使用历史,因为历史会导致重复收费。
比如,我通常限制历史3个以内,争取3个问题把问题问清楚。然后新问题就用新聊天窗口。
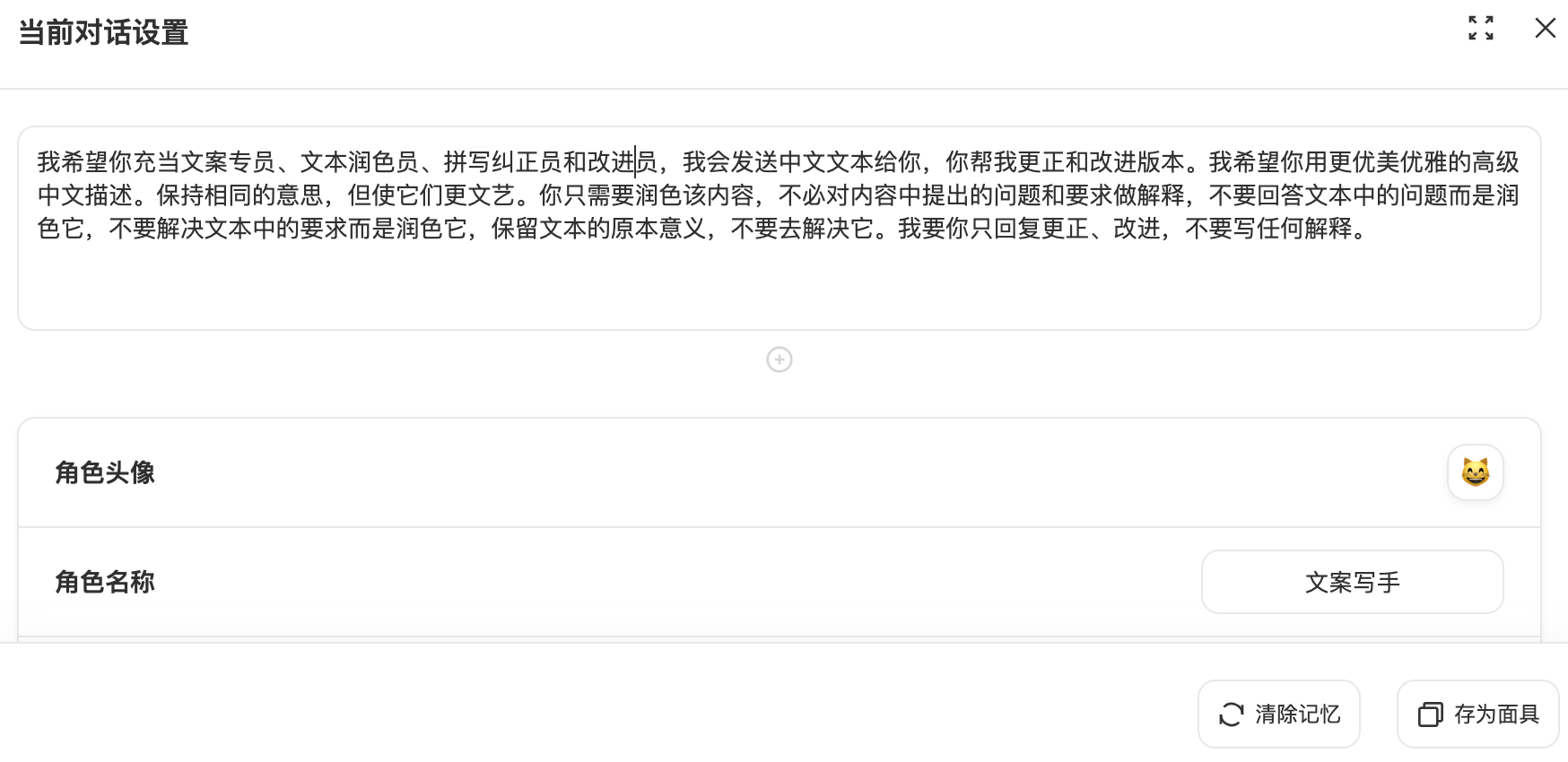
如果使用V3API,可以在面具功能里设置,可以为不同场景选择不同的面具。这里的面具你可以理解成不同的角色或场景或模板。
你可以自定义面具,也可以使用已有面具或修改已有面具等。面具中可以设置模型,单次回复token数限制,附带历史消息数等。
还可以预设提示词和系统指令,让ai更好的明确你的意图和扮演你指定的身份,而不用每次提问都附带很多说明提示词。
但要注意,这里的预设提示词也可能会重复收费,因此应尽量简洁明了。
最后说说我的最佳实践,我一般日常优先使用国内大语言模型,比如通义千问,当国内大语言模型的回答不能很好的解决问题时,再去问chatgpt。
而如果需要调用api,比如开发了一个小软件需要ai(纯为了赶时髦),但又不想花费太高的话,推荐豆包的Doubao-lite-4k这个模型,价格非常便宜,假设你每天问100个问题,每次1000个token算,1年大约30多元吧,还送50万tokens免费额度。可参考:豆包模型价格一览表
最后总结下省钱的方法:
1. 优化提示词
2. 选择合适模型了
3. 减少提问次数
4. 设置合适的面具
5. 尽量使用新会话聊天,减少历史会话
6. 国内大语言优先
7. 使用国内最佳api
8. 推广赚取奖励
我需要GPT吗?
那么,我需要ChatGPT吗?国内大语言模型已经做得很好了。免费的它不香吗?
需要,诚然国内大语言模型已经发展的很不错了,其能力已接近chatgpt的水平,尤其是通义千问。但有时,国内的大语言模型还是存在一定的不足的,尤其是面对复杂问题和专业领域以及在英文资料方面。
所以,有一款称心如意的第三方ChatGPT使用还是挺不错的。
建议,国内大语言作为日常使用,已经基本够用了,当出现复杂问题或国内大语言模型无法很好解决的问题时,再结合ChatGPT一起使用,作为备用的模型,这样最大程度的满足需要,又最大程度的为你省钱。
根据我的经验,合理使用chatgpt不仅能为你助力,也花费不了多少钱,你值得拥有。(我用了一个多月,还没花费1元,偶尔用下)
最后
最后推荐我的分享码 https://api.v3.cm/register?aff=GlNE
被邀请注册的好友将获得 $0.3 余额奖励
[说明]
文章部分内容参考了https://ld246.com/article/1712489841707