目前粘贴效果:

没有空格就行。
遇到的问题
预期的效果
复制文本的时候没有空白格
已尝试的解决方案
尝试了以纯文本粘贴,不行。
看网站上说linter,然后尝试打开几个选项,还是不行。
是所有pdf都出现吗?
空白格是行内还是换行处?
最好附个案例,楼主描述的这么简单,会让人觉得不像是提问,而是闲聊
单纯删除空白格可以用text format插件,有删空白行、合并内容之类的操作;配合editing toolbar可以放在笔记编辑页面上方的工具栏上
已经重新更新问题了,是行内的空白格,太松散了看着,还尝试了替换,没想到不行哈哈。我试试您说的插件。
我注意到你的空格都出现在缩写名称、数字和符号中。你可以检测一下在PDF中这些部分是不是特殊的格式。
删除空格的方法最简单的就是按下Ctrl+H查找替换,但是在下方提到不起作用。因此我怀疑其中包含的是Unicode空白符,你可以把文本加上引号输入控制台检查一下。
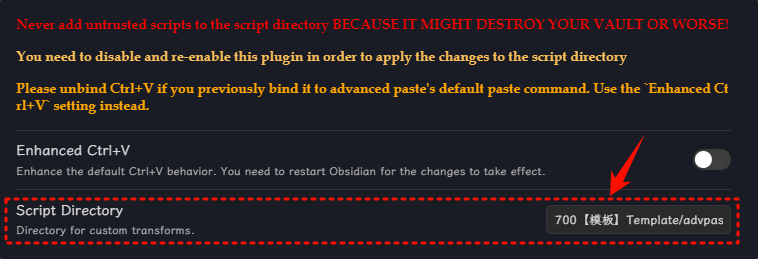
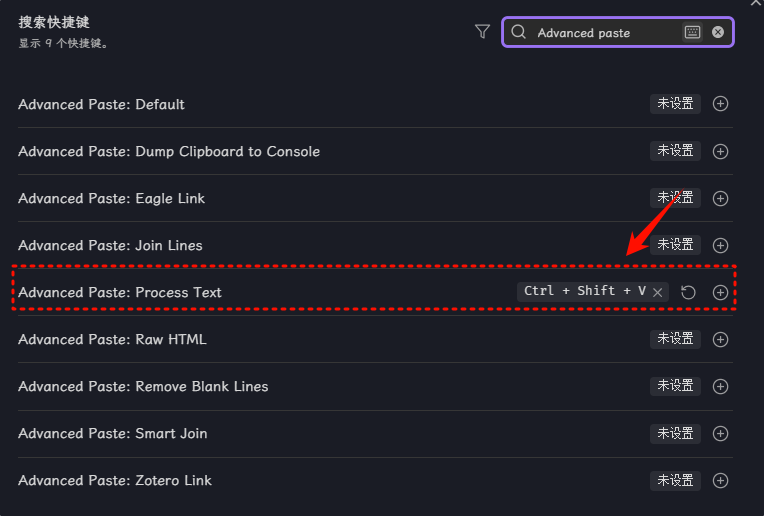
应该是PDF的格式问题吧,里面的英文还是全角的看得好别扭,如果你是win系统的话,用Quicker应该好解决,如果只想在obsidian内解决倒是可以用Advanced paste或者quickadd专门设置个格式化粘贴。
以下是Advanced paste插件处理的流程:
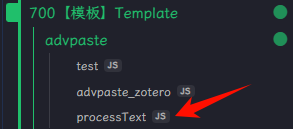
// 文本格式化处理
export function processText(text) {
// 替换特殊空格为普通空格
text = text.replace(/[\ue5d2\u00a0\u2007\u202F\u3000\u314F\u316D\ue5cf]/g, ' ');
// 将全角字符转换为半角字符
text = text.replace(/[\uFF01-\uFF5E]/g, function (match) { return String.fromCharCode(match.charCodeAt(0) - 65248); });
// 替换英文之间的多个空格为一个空格
text = text.replace(/([a-zA-Z])([\u4e00-\u9fa5])/g, '$1 $2');
// 删除中文之间的空格
text = text.replace(/([0-9\.\u4e00-\u9fa5])\s+([0-9\.\u4e00-\u9fa5])/g, '$1$2');
text = text.replace(/([0-9\.\u4e00-\u9fa5])\s+([0-9\.\u4e00-\u9fa5])/g, '$1$2');
text = text.replace(/([\u4e00-\u9fa5])\s+/g, '$1');
text = text.replace(/\s+([\u4e00-\u9fa5])/g, '$1');
// 在中英文之间添加空格
text = text.replace(/([\u4e00-\u9fa5])([a-zA-Z])/g, '$1 $2');
text = text.replace(/([a-zA-Z])([\u4e00-\u9fa5])/g, '$1 $2');
return text;
}
整体设置有点麻烦,不过一劳永逸,如果还想进一步优化,可以借助GPT以及查看它的说明文档。
我让KIMI给我写了一个小程序,批量替换空格和英文标点