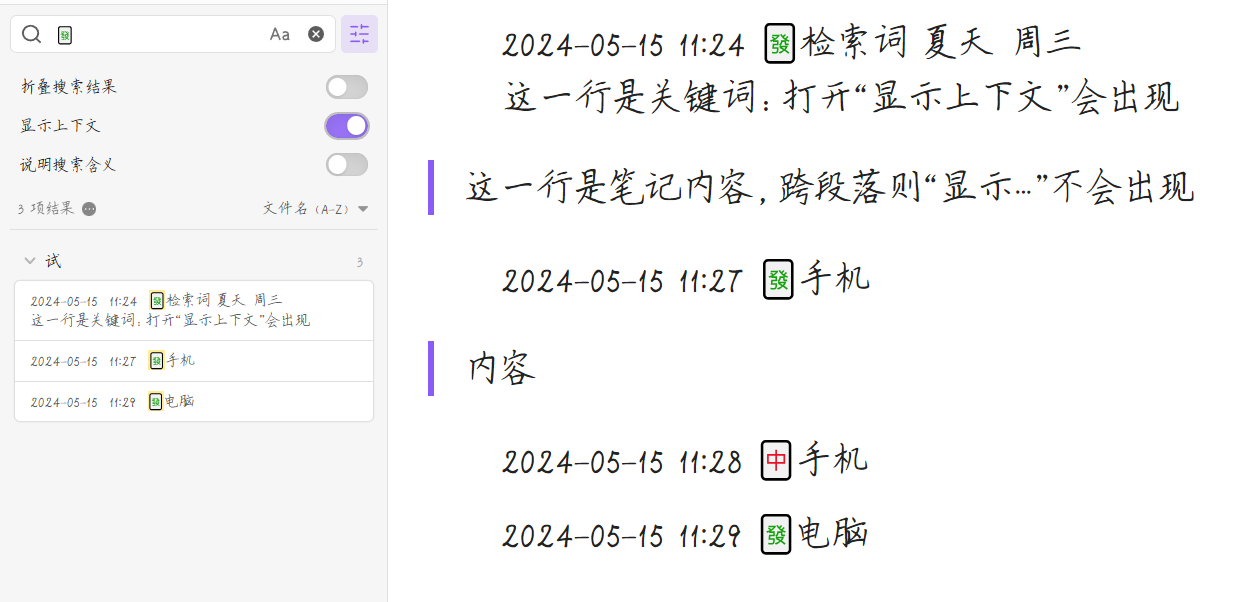
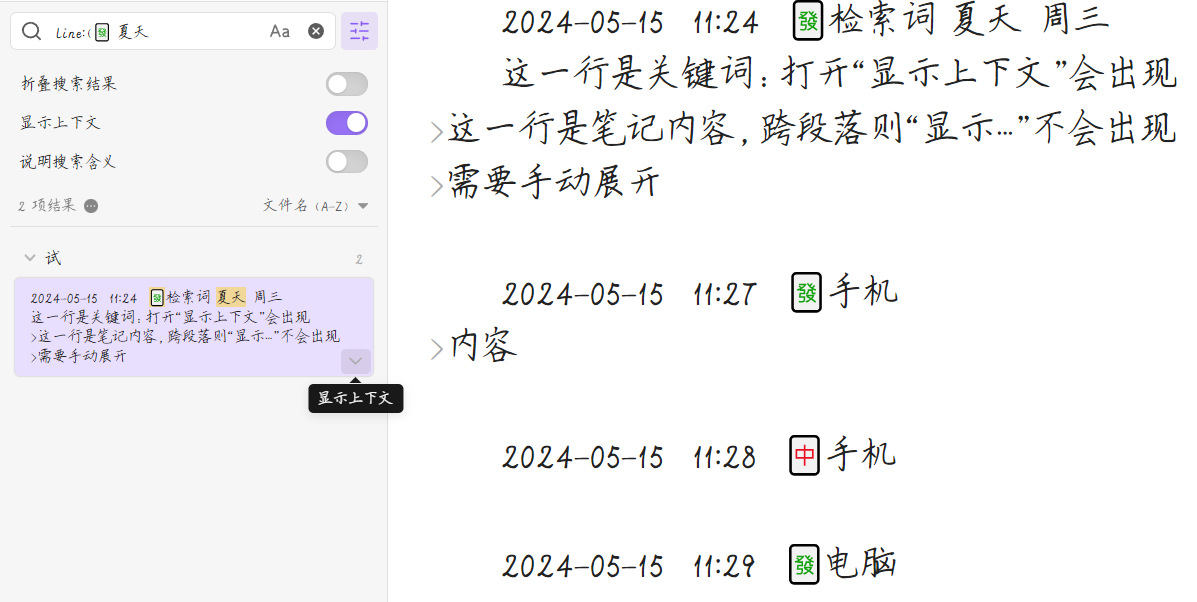
如题。最近在把 Obsidian 的库卡片化,文件数目多了不少,感觉自带的搜索已经有一点卡顿了(系统是 macOS Sonoma,Obsidian 版本是 1.5.12,还不是很明显)。
尝试了一下 Omnisearch 插件,但是不得不说对中文的支持确实不佳,安装中文分词插件以后也是。
所以很好奇,大佬们一般使用什么方案进行中文的高效检索?
以及一个想法:能在本地部署一个专业的搜索项目,让 Obsidian 乃至其他文本类软件都调用这个项目的接口进行搜索吗?
如题。最近在把 Obsidian 的库卡片化,文件数目多了不少,感觉自带的搜索已经有一点卡顿了(系统是 macOS Sonoma,Obsidian 版本是 1.5.12,还不是很明显)。
尝试了一下 Omnisearch 插件,但是不得不说对中文的支持确实不佳,安装中文分词插件以后也是。
所以很好奇,大佬们一般使用什么方案进行中文的高效检索?
以及一个想法:能在本地部署一个专业的搜索项目,让 Obsidian 乃至其他文本类软件都调用这个项目的接口进行搜索吗?
想法很好,可以搞一个全文索引。
可以考虑用Anytxt做全文搜索
FoxTrot Professional Search,或者把Obsidian库索引到DEVONthink中,这两个方案体验都不错。
用 Another Quick Switcher 调用本地 ripgrep 进行全文搜索
你好,我个人认为对于自己的资料检索,最好不依赖于平台、插件,采用最朴实无华的方式最佳!
“小说” 、“电影” 、“肖申克”,这3个关键词都能得到电影《肖申克的救赎》,但可能冗余(提到小说、电影的笔记都会出现)固而此时采用“前缀”,可使检索结果精确。譬如随便来一个我省特产🀅,在检索的时候使用:“🀅小说改编电影” 就能确得到《肖申克的救赎》,前提仅仅是在写笔记时在《肖》这部电影的笔记页面写一行:🀅小说 改编 电影。
用一个符号,或者一张图、一句词诗就能使检索结果精确,我甚至能用TXT格式的记事板完成对笔记的检索,电子笔记最重要的就是避免冗余,精确检索,符号的作用是使笔记内容跟“检索词”分离,可以适当多几个(学习型、实践型……)这是我的方法,也是我经年笔记工作觉得最有效的一条经验,分享给您![]() 抛砖引玉。
抛砖引玉。
@zhouwei15301 @dayu @F8a 感谢几位大佬的推荐。几个项目我都去试了下(AnyTXT 除外,没有 Windows 电脑 qaq),感觉各自都有优点吧。不过对于我这个体量的笔记而言,还是稍显沉重了点(笑)
@wilson @ADYR禅云 感谢两位大佬。窃以为二位的观点有相似性,都是在笔记内容和标题之外使用笔记某种形式的元数据进行搜索(乃至于全面转向元数据),感觉这也是很好的方法。
700w-800w字的库,不懂有没有说服力…
从我个人的使用经验来看,全文关键字还是太慢了。这里不是说通过各类工具检索得慢,而是说构建检索式、等待返回结果、再从众多结果中找到自己真正所需内容这整个过程快不了。少说也得奔30秒以上去,这和我的使用场景(5-10秒要能定位库中大部分内容)不符。
至于基于算法的检索,无论是本地语义还是大模型,全文索引是个很难搞的问题(基本需要几个小时起步,没有夸设备迁移性)…
我目前用这样的三行来做工作流:

如果你能允许其它软件的根目录成为Obsidian库的一个文件夹,在记笔记的时候使用自己的检索规则,就能实现在Obsidian中检索所有笔记,并且不止文本,或许你可以建立一个专门用来存放电影的库:我的意思是将电影文件存放在这个子库的“附件”文件夹内,新建立一个子库可以避免污染主力库。我并没有这样做,因为我的原则是从简,我使用了序号,如:
从硕士到工作,所有要用的知识都往里存 ![]()
具体来说就是用了很多信息组织方法去辅助搜索,这些方法还找不到才转向全文检索
我也是主要基于标题搜索。 很少使用全文搜索
Windows端可以用FileLocatorPro,另外社区有人分享了一键将md文件在Obsidian中打开的方法,跳转还是很方便的。对于打开方式有更高需求的,可以用f4menu
用 cwim 跑了一下我的库,大概是 1800 万字,Omnisearch 对中文支持不好,目前还是用内置搜索,速度也不是不可以接受,大概几秒钟吧,滚动条走不到10下。