经验分享区最近都没什么方法论方面的文章,搬点自己的东西过来。
今天来聊聊怎么把个人笔记库融入到我们的学习、工作、生活中。
我们如何利用知识
在开始讲这个问题之前,我们首先得明白人类是怎么利用知识的。
其实人类利用知识,是遵循“问题→知识→问题”这样一个模式的。当我们遇到问题的时候,我们首先会利用大脑的长时记忆能力,去回想过去类似问题的经验、知识,然后再把这些经验、知识套用到当前的问题情境中。
举个例子,比如领导让你分析一下公司最近的销售情况。首先,你会去找销售部门拿到公司最近的销售数据,把销售数据可视化成图表。然后,你就会观察这些图表,看看图里有没有波峰、有没有波谷。再看到具体的波峰、波谷后,接着你就会到记忆里去寻找,看看过去的经验和知识中,这些波峰、波谷分别代表着什么。最后,你再将回忆起的这些东西套用回现在的销售数据上,从而完成了对公司最近销售情况的分析。
再比如,朋友问你怎么去某家医院看病。首先,你会去回想最近一次在这家医院看病是什么时候,具体流程是什么,有什么需要注意的地方。等到回忆清楚后,你就会把这些经验通过对话告诉给朋友。
甚至说,哪怕我们学生时代经常面对的考试,也是一样的道理——我们看到试卷上具体的题目以后,大脑马上开始调动曾经学过的知识点和解题技巧,在找到合适的知识点和技巧后,再把它们用到当前题目上。
以上都是关于解决问题的例子。不少朋友比较关注写作、演讲之类的输出场景,但其实这些场景背后的模式其实是共通的。
大家可以想想我们平时是怎么写文章的。首先,我们会确定一个选题。然后,我们会在记忆中去搜索与选题相关的素材。最后,我们把需要的素材有机地整合起来,谋篇布局、遣词造句,最终形成一篇文章。在这里,素材其实也是那些我们看过的信息、习得的经验或知识。所以说,写作之类的输出场景和前面说的问题解决场景是类似的。
知识库的作用
那么,个人知识库在这个过程中有什么作用呢?或者说能帮到什么呢?答案很简单,个人知识库的核心意义就在于帮我们加速回忆的过程,提高我们获取所拥有的知识和经验的效率。
正如前面说的,无论是问题解决还是写作输出,核心都在于对过去习得的经验知识的回忆与使用。但是,人类的大脑毕竟是有极限的,我们不可能记住所有事情。一些久远的或者长时间没有使用的知识,我们往往是很难立马回忆起来的。当我们需要使用这些知识时,我们往往需要一定的时间去冥思苦想,甚至需要去查找过去的课本、记录来提示自己。而这就是拖累我们问题解决效率、写作输出效率的一个重要原因。
比如,你在分析公司销售数据的时候,忘了一些数据的意义。这时候你就只能暂停手下的分析工作,先去翻箱倒柜把数据字典文件找出来,把数据含义查清楚再说。再比如告诉朋友怎么去特定医院看病,如果你本身就没去过这家医院几次,上一次在这家医院看病又是一两年前,恐怕你也得绞尽脑汁一阵才能想起来这家医院的看病流程。考试那就更不用说了,忘了知识点的话题目就压根没法回答了。写作也是同理。如果我们抓耳挠腮都想不出适合题目的素材,那么就更不用谈后面的谋篇布局、遣词造句了。
但假如这些时候我们有个人知识库进行辅助,那就又不一样了。忘了数据含义,我们停下个半分钟到知识库里看一看数据含义就行了;忘了上一次看病的经历,去笔记库里搜索一下那天的日记一下就想起来了;忘了知识点,根据知识的名称速查一下,看看这个知识点是怎么定义的,就能继续作答了。
所以,笔记库就是一个存储个人知识的仓库。在我们需要知识、但是却忘记了知识的具体内容的时候,能够供我们快速的查找——我们能够依赖各种各样的手段在文字中快速找到所需的知识、经验、信息。这样,我们的问题解决过程和写作输出过程就不会因为查找知识、查找素材而暂停卡顿,从而提高了我们的解决问题和写作输出效率。为什么大家觉得卡片笔记法有用,原因就是它能让我们在写作的时候参考自己过去的思考结果,从而避面了“无米之炊”的尴尬。
为什么是个人知识库
这时候你们可能就会说,那为什么非得是个人知识库,我查百科、查搜索引擎不也一样吗?
其实还真不一样。
首先是在内容上。百科或者搜索引擎收录的内容都是相对大众化的,或者说是别人的。我们过去那些经验和见解,特别是那些与工作、个人生活强相关的内容,百科和搜索引擎并不会有。比如,女朋友准备生日了,你需要送一份礼物。虽然各类网站上都会有“女朋友最喜欢的礼物”之类的经验贴,但是这些推荐并不一定比得上半年前被你不经意记录在知识库里的那句“她好喜欢永恒花园的手办”。如果你能快速找到这则经验,礼物不就不用愁了。
其次是在搜索上。虽然搜索引擎提供了强大的检索功能,但是这种搜索针对的是网页,而不是知识。相信你们也有这样的经历,翻了十几个搜索引擎给出的网站,却没有一个想要的结果。举个例子,比如我们在做销售数据可视化的时候,需要做一个曾经做过的、比较复杂的数据图。这时候如果我们去搜索引擎里搜索,得到的是几十个网页。这几十个网页里都罗列了做图的步骤,看似是把图的制作方法告诉我们了。但实际上并不是每个网页的内容都是符合我们需要的,可能有一部分、甚至所有网页罗列的作图方法都不能满足我们的要求。我们一个个试过去的话,不仅浪费了时间,还没法把图做出来。但如果我们用的是个人知识库,那么我们就能比较快地找到过去那个已经成功用过的做法。
这两点实际上就给我们的个人知识库提了两个很严格的要求。
首先,我们的知识库需要保存的是那些被自己验证过的、可以复用的知识或信息。这里的关键并不是很多观点说的“要用自己的话”、“要原创”,而是说要能清楚的表述知识或信息本身,说清楚事情是什么,为什么对、为什么错。如果是涉及方法步骤的内容,我们还要详细描述过程,让我们哪怕过了十年来看还能知道怎样做。如果你能把这些要点记录清楚,笔记里使用非原创内容其实也没什么问题。毕竟这是个人知识库而不是发表的文章,核心在于保存所需知识而不是论文的草稿。当然,这里我还是要提醒一下,如果要在笔记中使用非原创内容,那么最好给非原创部分做好标记,让我们过了十年也能明白这是别人的原创内容并能找到内容的出处,以便在使用时注意内容原创性的问题。
其次,我们的知识库需要进行良好的组织,以保证后期搜索的效率。毕竟个人知识库的关键在于高效的个人知识搜索效率。在过去几年的实践里面,我总结出了一个5秒原则,就是说我们要能在5-10秒左右在自己的知识库里找到自己所需要的知识。只有这样,我们的知识库才是成功的,才能为我们的工作生活服务。超过了这个时间,我们很有可能就找不到想要的内容而烦躁了,最终的结果就是放弃寻找,这样我们的知识库存在意义就大打折扣了。而快速查找这一要求就需要我们尽可能地在前期通过标签、分类等方式去管理内容,去尽可能地为知识提供多途径的搜索渠道。管理方法每多一种,后期快速找到所需知识的把握就多一分。
此外,快速查找还要求我们尽可能地去做到面向知识进行保存,争取让知识库的基本单元是一个知识而不是一篇文献或一本书籍。并且在管理的时候,合并相同的知识内容,去除冗余的部分。这样我们后期查找的时候才能精准直达所需知识,而不是看着搜索结果里的一串书单或者文献列表懵逼。
实践案例
理论说了这么多,那么具体该怎么实践呢?这里我用一些案例演示一下。
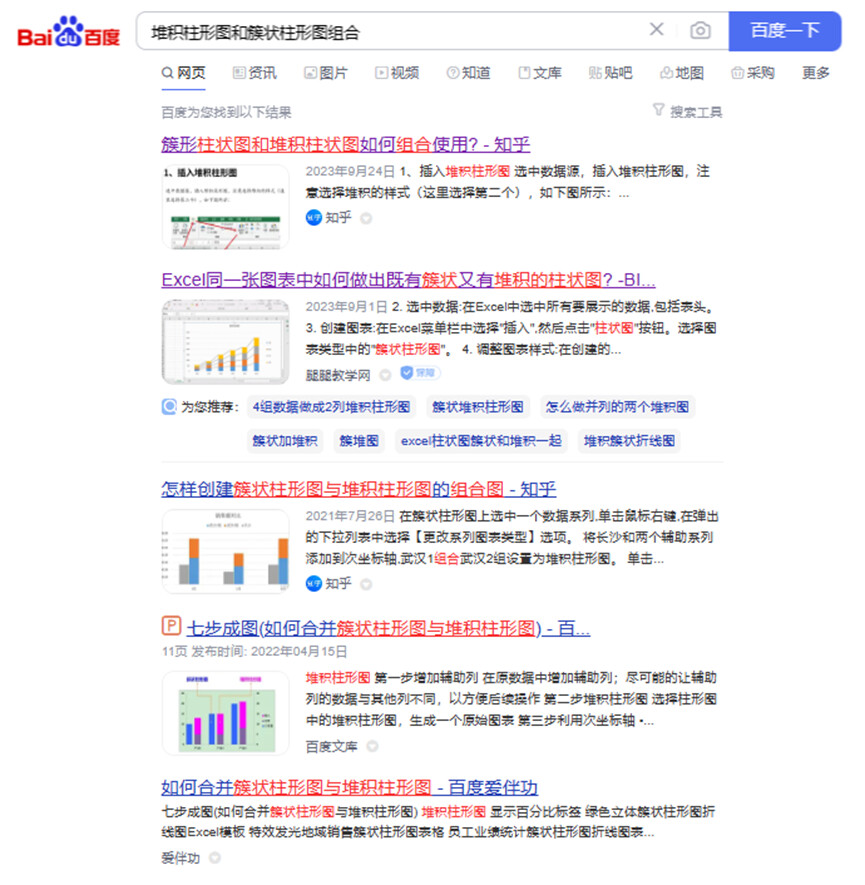
这里还是假设需要给销售数据作图这个场景,比如我需要作一个组合簇状柱形图和堆积柱形图的图。这里我只需要联合 #簇状柱形图 和 #堆积柱形图 两个标签在知识库里进行搜索就可以了。如果搜索的结果过多的话,我还可以借助分类将内容限制在TP计算机大类下,从而让结果更精准。
在这里,我并没有把做的步骤一五一十的用自己的话转述出来,而是直接指明了原文所在的位置,但这并不影响我对这个知识的使用。所以这就像前面说的,知识库的核心是说清楚知识是什么,至于写作发表的注意事项,我们完全可以在写作的时候再说。
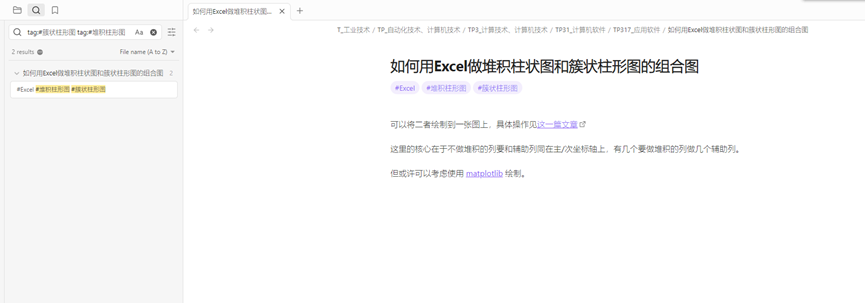
再比如,假设我们需要写一篇关于管理的小短文,那么就可以到“C93-0 管理学理论与方法论”这个分类下,找到与管理学相关的笔记。我们可以把这些笔记先快速浏览一遍,然后就可以根据自己的思路,把这些笔记中有用的内容挑选出来。接着,把挑选出来的素材拼成大致的顺序,然后再优化一下措辞。这样,一篇文章初稿就完成了。
当然,这里使用标签或者关键词进行搜索也是可以的。只是不同的方法在检索结果上存在着差异。
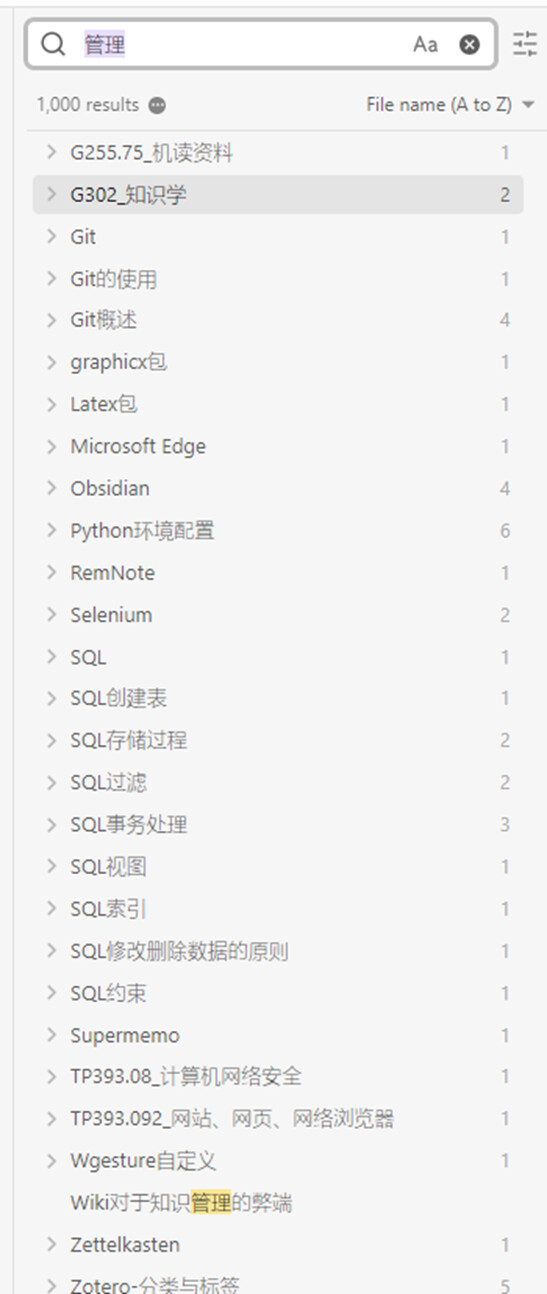
比如以关键词法为例,我在2000多篇笔记的老知识库中搜索“管理”这个词,能得到1000个结果。显然,这些结果并不完全是与我们“管理”这个写作主题强相关的。虽然这1000个结果或多或少能开阔我们写作的思路,但总的来说并不能提高我们的写作效率,更像是一种干扰。所以靠关键词搜索这种管理方法,虽然在前期省去了管理的成本,但是在后期我们应用知识的时候往往需要付出更多的精力——我们需要想办法构建更精准的检索式才能找到想要的东西。所以我比较推荐把关键词搜索作为一种保底救命的手段,在有条件的情况下,还是需要在前期对我们的知识进行整理。
那么AI行不行呢?其实就我的实践来看,可以说可以,也可以说不可以。如果知识库很小,或者我们对搜索出来的内容要求不那么高的话,现在的大模型确实是一个不错的选择——即便前期没有有序管理笔记,也能得到一个不错的搜索速度和搜索结果,唯一需要考虑的就是部署的费用问题以及部署难度问题。但如果我们的库很大,或者说我们对搜索的结果要求很高,现有的大模型就不够看了。这一方面是知识库的解析费用很高,另一方面就是当前的大模型还没法把非常大量的内容塞到对话上下文里,这就使得在这种情景下得到的结果仍然不够准确。此外,对于一些工作相关的涉密内容,你根本没有办法让大模型来访问这些数据。所以,就目前这个情况下,我们还是要掌握一些手动构建知识库的方法和技巧,先把当下照顾好了,再去期待完全智能化的明天。
小结
最后,我们来总结一下。要想个人知识库有用,想让它能帮助我们的学习、工作、生活,核心是保证知识库记录的是被验证过的、可以复用的个人知识,同时保证我们能快速找到这些知识。这样,个人知识库才能成为我们的“第一外脑”,在我们决策、写作的时候提高我们的效率。