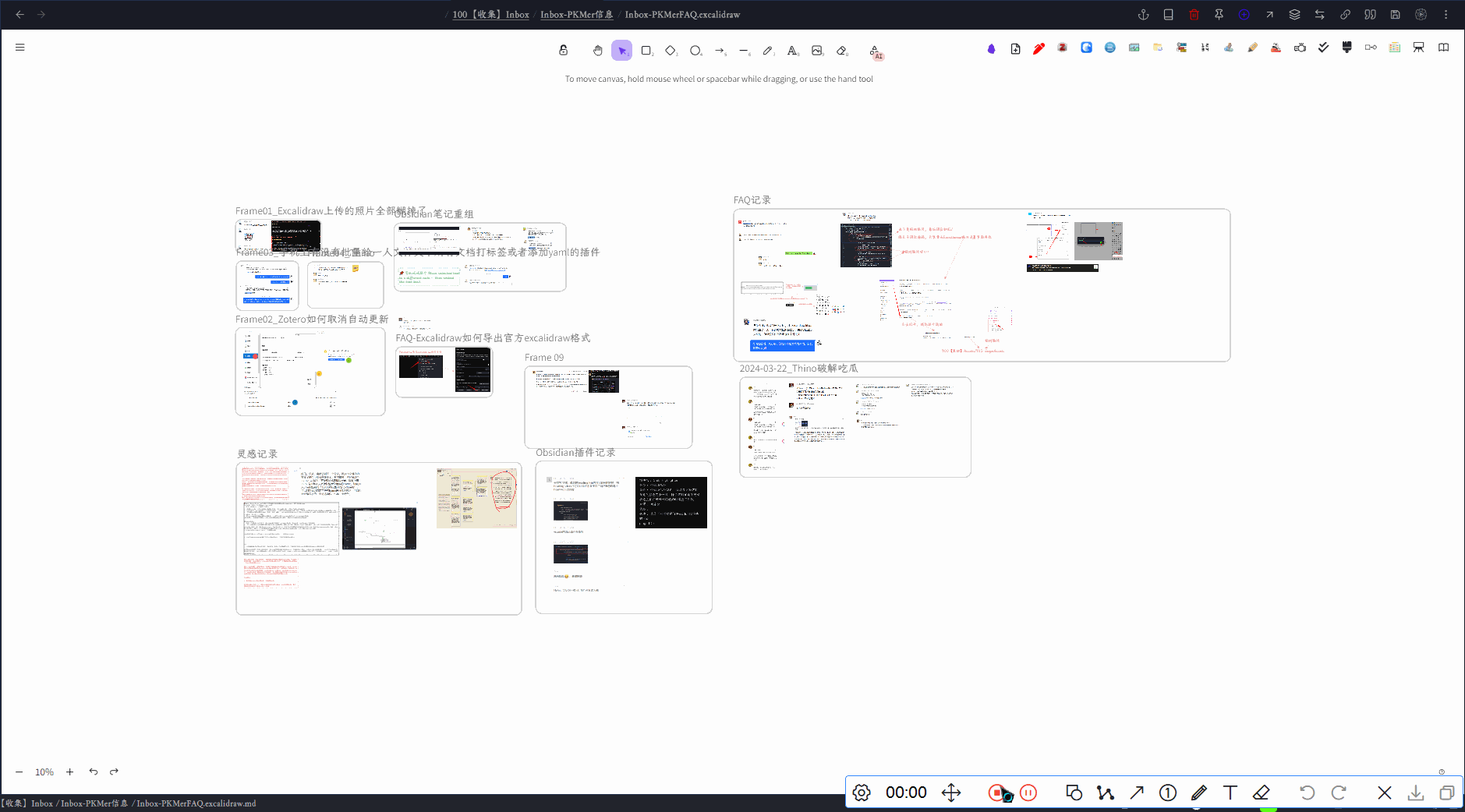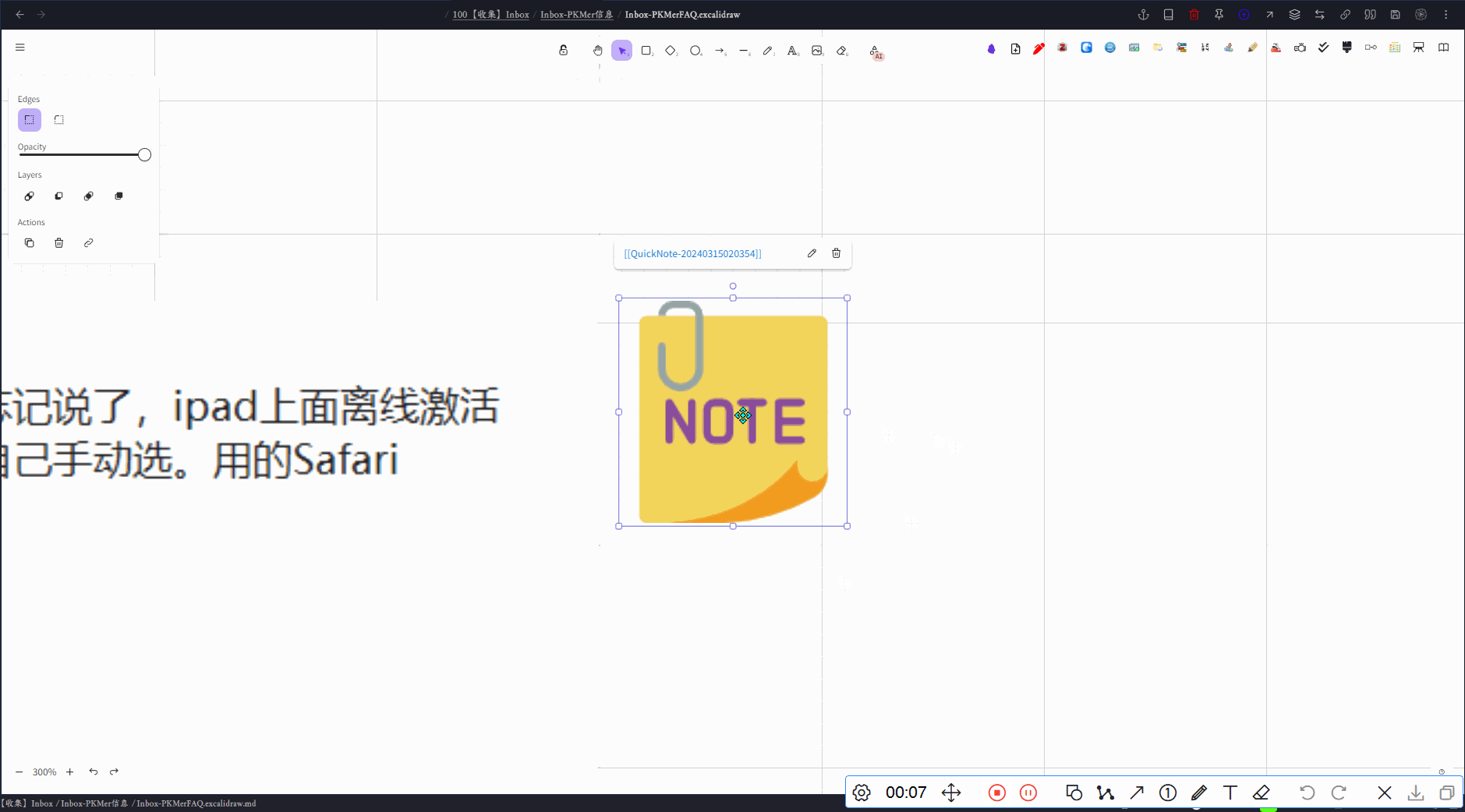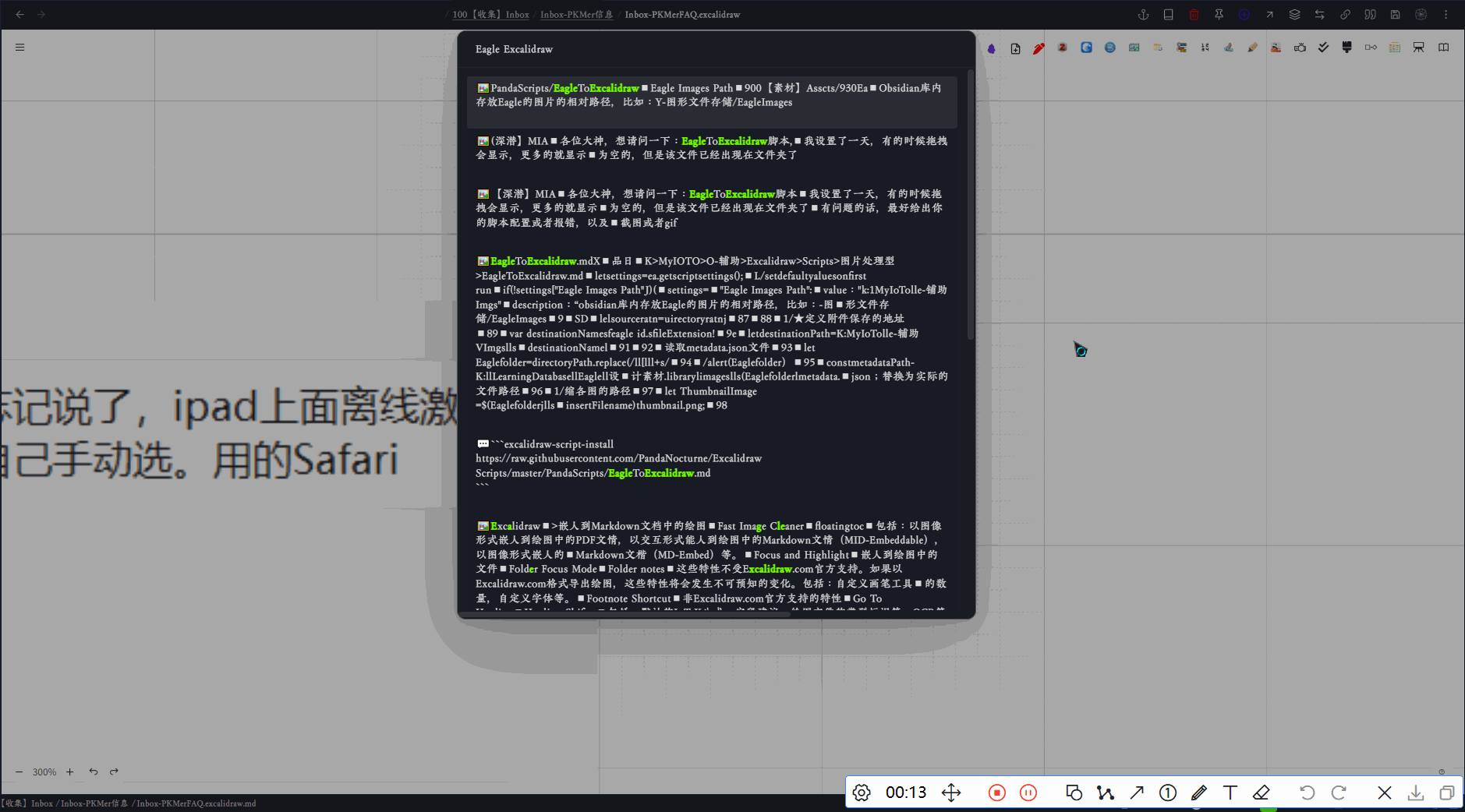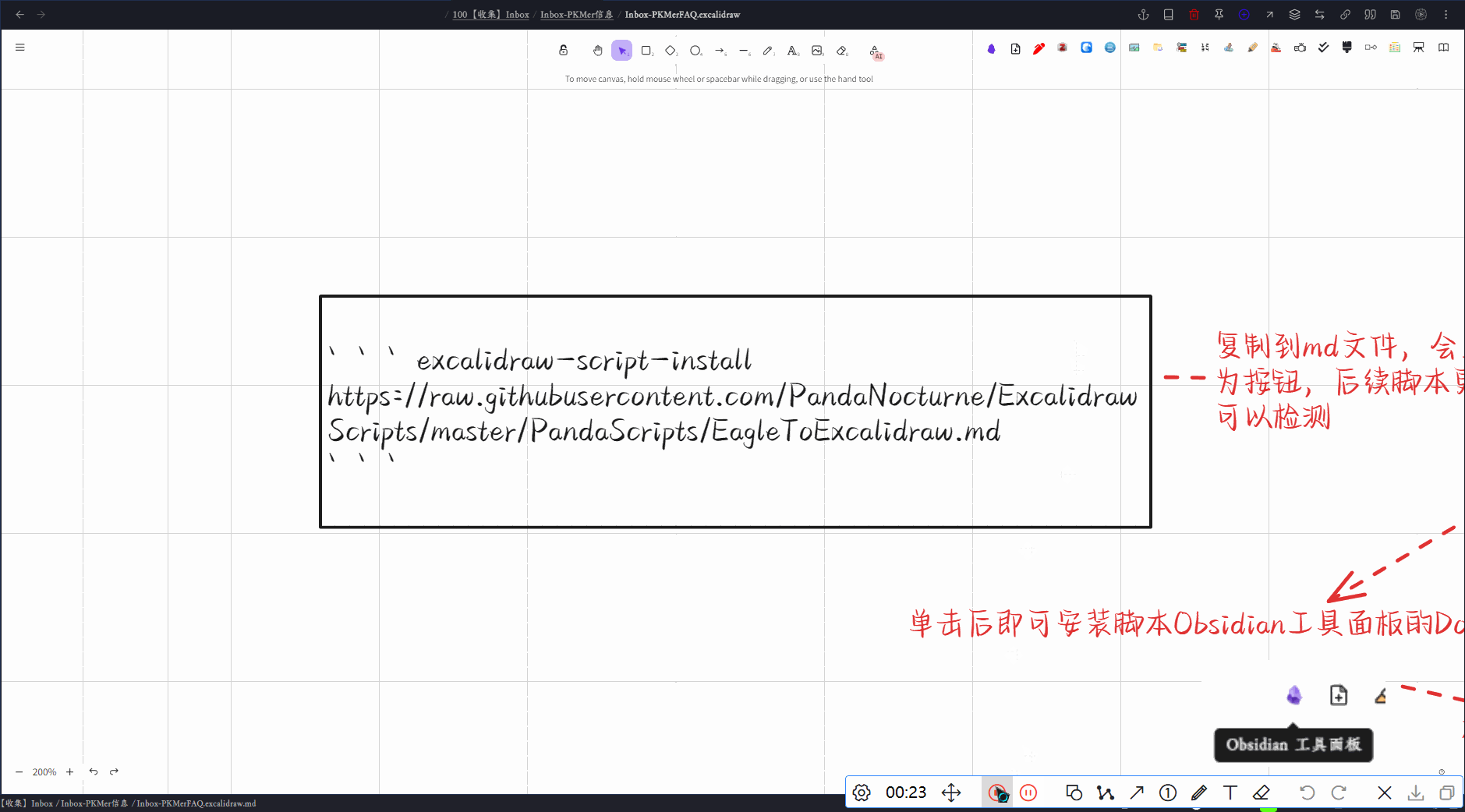
全局搜索对于笔记类应用程序是一个非常重要且实用的功能。用户经常需要在大量的文本、图片和嵌入文档中快速定位信息,以提高工作效率和信息管理。在 Excalidraw 这样的图形绘图工具中,实现画布全局搜索功能可以帮助用户更快速地查找和定位关键信息。
该脚本实现了基于 Excalidraw 画板的全局搜索功能。可以选择不同选项,搜索![]() 文本元素、
文本元素、![]() 图片元素(采用 PaddleocrOCR 或者 Obsidian 的 Text Extractor 插件进行 OCR)、
图片元素(采用 PaddleocrOCR 或者 Obsidian 的 Text Extractor 插件进行 OCR)、![]() 嵌入的文档 (wiki 链接或者 embeddable 文档)、以及画板的
嵌入的文档 (wiki 链接或者 embeddable 文档)、以及画板的![]() 全文搜索 (包含所有元素选项),并通过选择的搜索结果聚焦到该元素。
全文搜索 (包含所有元素选项),并通过选择的搜索结果聚焦到该元素。
PS:
全文搜索不会自动 OCR 图片,只会显示已经被 OCR 了的检索结果,
图片 OCR选项会自动 OCR 未被 OCR 的图片。
使用技巧
你可以在全文搜索中通过、
标识符来限定
Tip、PS、FAQ、Q&A都可以作为关键词进行筛选。另外推荐快捷键设置Alt + F。
图片 OCR 模型
支持本地 Paddleocr 以及 Obsidian 的 Text Extractor 插件 2 种识别模式:
本地的 Paddleocr 识别
本地的 Paddleocr 需要专门下载模型以及其他配置,这里我就将模型文件 (一百多 M 上传不了 GitHub) 上传到百度网盘,需要的自取:百度网盘:Excalidraw全局搜索.zip
Text Extractor 插件识别
TextExtractor 模式需要安装 Text Extractor 插件,在里面最好勾选 chi_sim 简体中文选项,不过该模式对中文识别率也不太好,速度也比较慢,建议采用本地 Paddleocr 模型。
脚本链接
https://raw.githubusercontent.com/PandaNocturne/ExcalidrawScripts/master/PandaScripts/ExcalidrawGlobalSearch.md
d
源代码
await ea.addElementsToView(); // 等待所有图片都加载完成
const quickAddApi = app.plugins.plugins.quickadd.api;
const fs = require('fs');
const path = require('path');
const activeFile = app.workspace.getActiveFile();
const { exec } = require('child_process');
let settings = ea.getScriptSettings();
//set default values on first run
if (!settings["ocrModel"]) {
settings = {
"ocrModel": {
value: "Paddleocr",
valueset: ["Paddleocr", "TextExtractor", "无"],
description: "选择 OCR 模型,有本地的 Paddleocr(需要本地文件)、Obsidian 的 Text Extractor 插件 API",
},
"PaddleocrPath": {
value: ".obsidian/paddlleocr/PaddleocrToJson.py",
description: "选择 paddlleocr 文件夹路径下的 PaddleocrToJson.py 文件"
},
};
ea.setScriptSettings(settings);
}
// 获取文本元素
const textEls = ea.getViewElements().filter(el => el.type === "text" && el.text.length >= 4);
// 获取嵌入文档元素
const fileEls = [...ea.getViewElements().filter(el => el.type === "embeddable"), ...ea.getViewElements().filter(el => el.type !== "embeddable" && el.link && el.link.endsWith("\]\]"))];
// 获取图片元素
const imageEls = ea.getViewElements().filter(el => el.type === "image");
const imgOcrEls = imageEls.filter(el => el.customData && el.customData["ocrText"]);
const imgOcrErrorEls = imgOcrEls.filter(el => el.customData["ocrText"] === "...");
const imgOcrNum = imageEls.length - imgOcrErrorEls.length;
const imgUnOcrNum = imageEls.length - imgOcrEls.length;
const zoom = [2, 2, 2, 3];
const icon = ["✒", "💬", "🖼", "📝"];
// 获取库的基本路径
const basePath = (app.vault.adapter).getBasePath();
// 综合选项
const choices = [`${icon[0]}全局搜索(${textEls.length + imgOcrNum + fileEls.length}-${imgUnOcrNum})`, `${icon[1]}文本数据(${textEls.length})`, `${icon[2]}图片(OCR)(${imgOcrNum}-${imgUnOcrNum})`, `${icon[3]}嵌入文档(${fileEls.length})`,];
const choice = await utils.suggester(choices, choices);
// 图片的OCR并不会记录在Yaml区而是记录在自定义数据中
const getImgOCR = async (imageEls) => {
// 图片计数
let n = 0;
// 汇集所有文本集合
const allImageText = [];
const allImageEls = [];
for (let el of imageEls) {
const currentPath = ea.plugin.filesMaster.get(el.fileId).path;
const file = app.vault.getAbstractFileByPath(currentPath);
// 获取图片路径
const imagePath = app.vault.adapter.getFullPath(file.path);
// console.log(`获取图片路径:${imagePath}`);
// !初始化
let ocrText = ""; n++;
if (!el.customData) {
el.customData = {
ocrText: ""
};
}
if (el.customData["ocrText"]) {
// console.log(`图片已存在OCR文本`);
ocrText = el.customData["ocrText"];
} else if (settings["ocrModel"].value === "Paddleocr") {
// new Notice(`图片OCR中......`);
// 执行Paddleocr,如果报错则会保留ocrText的值
const scriptPath = `${basePath}/${settings["PaddleocrPath"].value}`;
console.log(scriptPath);
await runPythonScript(scriptPath, imagePath)
.then(output => {
// 在这里处理Python脚本的输出
console.log(output);
let paddlleocrJson = JSON.parse(output);
let paddlleocrText = paddlleocrJson.data.map(item => item.text);
ocrText = paddlleocrText.join("\n");
new Notice(`第${n}张片已完成OCR`, 2000);
})
.catch(error => {
new Notice(`Paddleocr识别失败,跳过`);
ocrText = "...";
console.error(error);
});
} else if (settings["ocrModel"].value === "TextExtractor") {
const text = await getTextExtractor().extractText(file);
new Notice(`第${n}张片已完成OCR`, 500);
ocrText = processText(text);
}
// 更新数据源,存储在元素中
if (ocrText === '...' || ocrText === '◻◻◻◻◻◻') {
el.customData["ocrText"] = "...";
} else {
el.customData["ocrText"] = ocrText;
// 收集提取的信息
allImageText.push(ocrText);
allImageEls.push(el);
}
await ea.addElementsToView(false, false);
}
ea.copyViewElementsToEAforEditing(imageEls);
await ea.addElementsToView(false, true);
return { allImageText, allImageEls };
};
const getFileText = (files, fileEls) => {
const allFileText = [];
const allFileEl = [];
for (let el of fileEls) {
const filePath = getFilePath(files, el);
if (!filePath) continue;
if (filePath.endsWith(".md") && !filePath.endsWith("excalidraw.md")) {
// 读取文件内容
const markdownText = getMarkdownText(filePath);
allFileEl.push(el);
allFileText.push(`${filePath}:\n\n${markdownText}`);
}
}
return { allFileText, allFileEl };
};
if (choice === choices[0]) {
if ((imageEls.length - imgOcrEls.length) >= 1) {
new Notice(`💡全局搜索中存在${imageEls.length - imgOcrEls.length}个未OCR的图片没被检索`);
}
let allElText = [];
let allElements = [];
// 获取图片文本
const { allImageText, allImageEls } = await getImgOCR(imageEls.filter(el => el.customData && el.customData["ocrText"]));
// 获取文本文本
const allTexts = textEls.map(el => `${icon[1]}${el.text}`);
// 获取文件文本
const files = app.vault.getFiles();
const { allFileText, allFileEl } = getFileText(files, fileEls);
allElText = [
...allTexts,
...allImageText.map(img => `${icon[2]}${img.replace(/\n+/g, "◼")}`),
...allFileText.map(txt => `${icon[3]}${txt}`)
];
allElements = [
...textEls,
...allImageEls,
...allFileEl];
// 因为Excalidraw的utils.suggester建议框有数量限制,这里选用QuickAdd的api
const selected = await quickAddApi.suggester(allElText.map(txt => `${txt}` + `\n`.repeat(2)), allElText);
const index = allElText.indexOf(selected);
const selectedElement = allElements[index];
if (selectedElement) {
// 执行跳转到选定元素的操作
api = ea.getExcalidrawAPI();
api.zoomToFit([selectedElement], zoom[0]);
}
return;
}
// 💬文本搜索
if (choice === choices[1]) {
// textEls.map(el => el.text)
const selectedElement = await quickAddApi.suggester(textEls.map(el => `${icon[1]}${el.text}` + `\n`.repeat(2)), textEls);
if (selectedElement) {
// 执行跳转到选定元素的操作
api = ea.getExcalidrawAPI();
api.zoomToFit([selectedElement], zoom[1]);
}
return;
}
// 🖼图片搜索
if (choice === choices[2]) {
console.log(`检测到${imgUnOcrNum}张图片未进行OCR识别...OCR识别中`);
const { allImageText, allImageEls } = await getImgOCR(imageEls);
const selectedElement = await quickAddApi.suggester(allImageText.map(txt => `${icon[2]}${txt.replace(/\n+/g, "◼")}` + `\n`.repeat(2)), allImageEls);
if (selectedElement) {
// 执行跳转到选定元素的操作
api = ea.getExcalidrawAPI();
api.zoomToFit([selectedElement], zoom[2]);
}
return;
}
// 📝嵌入文档搜索,目前只支持embed格式
if (choice === choices[3]) {
// 获取库所有文件列表
const files = app.vault.getFiles();
const { allFileText, allFileEl } = getFileText(files, fileEls);
const selectedElement = await quickAddApi.suggester(allFileText.map(txt => `${icon[3]}${txt}` + `\n`.repeat(2)), allFileEl);
if (selectedElement) {
// 执行跳转到选定元素的操作
api = ea.getExcalidrawAPI();
api.zoomToFit([selectedElement], zoom[3]);
}
return;
}
// 调用 Text Extractor 的 API
function getTextExtractor() {
return app.plugins.plugins['text-extractor'].api;
}
// 格式化文本
function processText(text) {
// 替换特殊空格为普通空格
text = text.replace(/[\ue5d2\u00a0\u2007\u202F\u3000\u314F\u316D\ue5cf]/g, ' ');
// 将全角字符转换为半角字符
text = text.replace(/[\uFF01-\uFF5E]/g, function (match) { return String.fromCharCode(match.charCodeAt(0) - 65248); });
// 替换英文之间的多个空格为一个空格
text = text.replace(/([a-zA-Z])([\u4e00-\u9fa5])/g, '$1 $2');
// 删除中文之间的空格
text = text.replace(/([0-9\.\u4e00-\u9fa5])\s+([0-9\.\u4e00-\u9fa5])/g, '$1$2');
text = text.replace(/([0-9\.\u4e00-\u9fa5])\s+([0-9\.\u4e00-\u9fa5])/g, '$1$2');
text = text.replace(/([\u4e00-\u9fa5])\s+/g, '$1');
text = text.replace(/\s+([\u4e00-\u9fa5])/g, '$1');
// 在中英文之间添加空格
text = text.replace(/([\u4e00-\u9fa5])([a-zA-Z])/g, '$1 $2');
text = text.replace(/([a-zA-Z])([\u4e00-\u9fa5])/g, '$1 $2');
return text;
}
// 获取文件路径下的 md 中的文本(排除 Yaml)
function getMarkdownText(filePath) {
// 获取文件的完整路径
const fileFullPath = app.vault.adapter.getFullPath(filePath);
// 读取文件内容
const fileContent = fs.readFileSync(fileFullPath, 'utf8');
// 排除首行YAML区域
const markdownText = fileContent.replace(/---[\s\S]*?---\n*/, '').replace(/\n\n/, "\n");
return markdownText;
}
// 由文件列表和 el 元素获取文件路径(相对路径)
function getFilePath(files, el) {
let files2 = files.filter(f => path.basename(f.path).replace(".md", "").endsWith(el.link.replace(/\[\[/, "").replace(/\|.\*]]/, "").replace(/\]\]/, "").replace(".md", "")));
let filePath = files2.map((f) => f.path)[0];
console.log(filePath);
return filePath;
}
// 运行本地 Python 文件
function runPythonScript(scriptPath, args) {
return new Promise((resolve, reject) => {
const command = `python "${scriptPath}" "${args}"`;
exec(command, (error, stdout, stderr) => {
if (error) {
console.error(`执行命令时发生错误: ${error.message}`);
reject(error);
}
if (stderr) {
console.error(`命令执行返回错误: ${stderr}`);
reject(stderr);
}
resolve(stdout.trim());
});
});
}
