目的:
我笔记里有些网址链接, 形如 参考链接 [title](https://xxxxx.com/page/url)
或者更简单只有个 url, 形如 见网址 https://xxxxx.com/page/url 一些备注说明
想用 Text Generator 给这些链接快速方便的生成内容摘要
为啥不用网页版大模型?
其实我一直就这么干的, 现在想更懒点
网页版大模型, 做这事的步骤:
- 在笔记里复制链接, 可能需要从中挑出 url 部分
- 浏览器找到网页版大模型, 一般这是随时开着备用的
- 对话框里敲字:
总结这个网址的文章 要简单不要太长: - 之前复制好的链接, 粘对话框里:
(...接上面): https://xxxxx.com/page/url - 发送, 等它回复, 把对话复制下来贴笔记里
- 注意: 要求你的模型能联网读网页, 虽然现在这并不稀罕
而 Text Generator 理论上能做到的步骤:
- 使用场景A: 选中笔记里的 url, 运行 “总结文章”, AI 自动把摘要生成到链接底下, 完事
- 使用场景B: 全选十篇文章链接, 运行 “总结文章”, 摘要就自动填写到每篇的 url 底下 (内部可以是发一次或发十次对话请求, 分开还是合并, 要综合考虑便捷和价格)
可以看到使用 TextGen 插件的好处:
- 在当前笔记里做完所有事, 不切换窗口
- 提示词存档复用, 方便改进优化 (实践发现提示词还是要持续调试的, 没法一次定型, 道理跟代码一样)
- 预处理 “不必由 LLMs 出手的工作”, 比如抓取文章就属这类, TextGen 内置了网页提取器, 提交到 LLMs 时已是整理好的文本, 于是: 可以选择不能联网的大模型, 可以精确控制 tokens 成本
我想要的是, 争取实现 “使用场景B”, 以下为步骤
学习如何使用 Text Generator
1 配置模型
有模型 API 使用经验的朋友请略过本节
Ob 各家 AI 插件的配置方法都差不多, 通常需要准备好三个东西
# 以 OpenRouter 的免费 Mistral-7b 为例
请求地址: https://openrouter.ai/api/v1/chat/completions
模型名字: mistralai/mistral-7b-instruct:free
api_key: sk-or-v1-33dca1......
在 Text Generator 设置 → LLM Provider 新增一项 Custom 配置
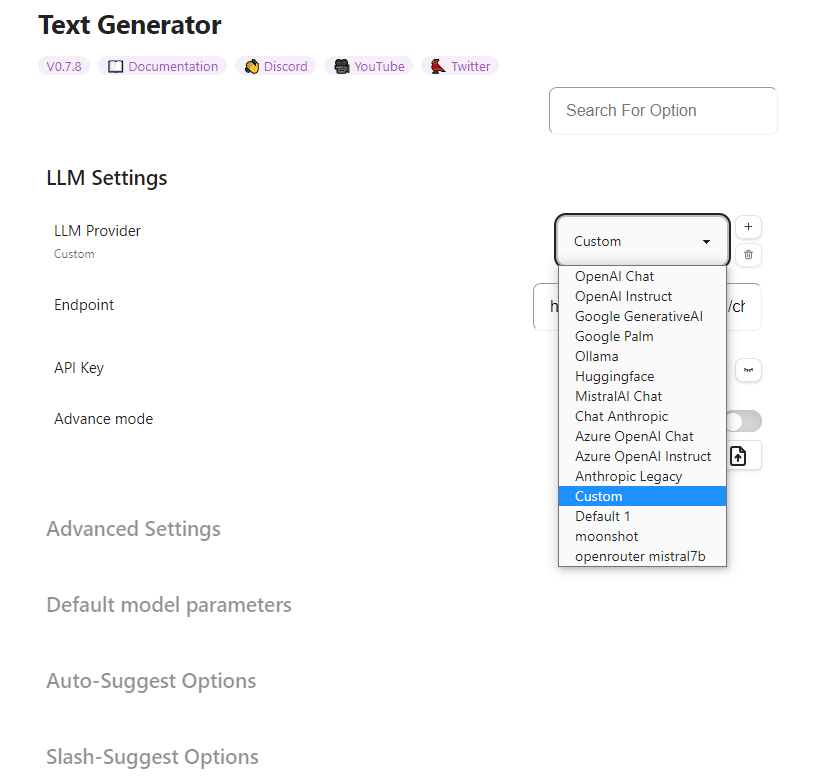
- 模型请求地址 填在 Endpoint 里
- 模型名字 填在 model 里
- api_key 填在 Headers 的 “Bearer apikey” 这里, 注意保留
Bearer这几个字
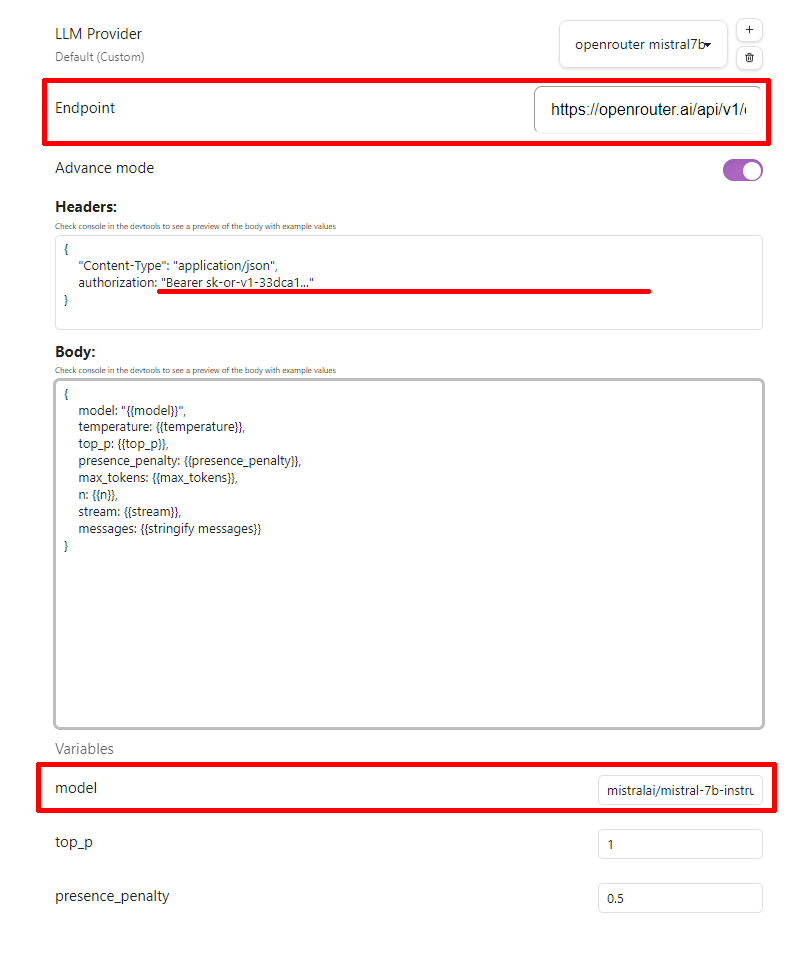
对于兼容 OpenAI 接口的大模型, 这样就完成了
其余的都是可选参数, 先默认就行
2 测试模型可用
光标停在笔记的任一处, 点击 “Ob 最左边图标按钮” 的 Generate Text
![]()
这会续写当前笔记, 大致等同于 “把光标前的全部段落粘贴给 AI, 之后 AI 给你回复”
这也为测试模型 api_key 是否配置妥了
3 写个简单模板
TextGen 用模板来管理各种不同功能的提示词
要在仓库根目录造文件夹 <仓库root>/textgenerator/templates/ 模板默认就放这里, 每个作者应该再造一级子目录
可以从 TextGen 的模板管理器里下载一些别人分享的, 或自己添加个模板试试, 例如:
---
promptId: test_simplify
name: 段落简化
description: 段落简化 改为简明易懂的描述
---
把以下段落简化, 改为简明易懂的描述, 输出化简文字就行, 别抄原文
{{tg_selection}}
模板也是个 .md 文件, 文件名不重要, FrontMatter 里的 promptId 和 name 重要
完后 Ob 里运行命令 Templates: Generate & Insert 选刚才的模板, 就能用了
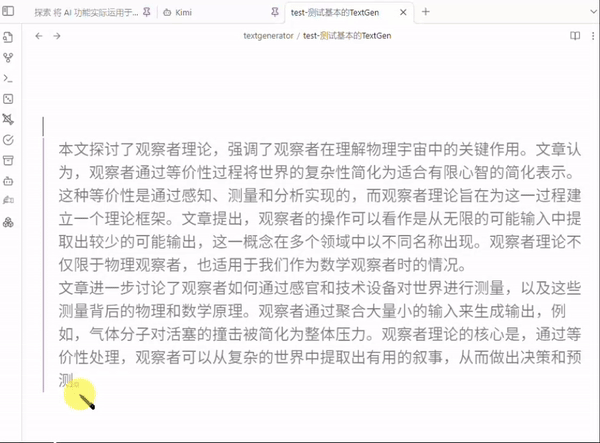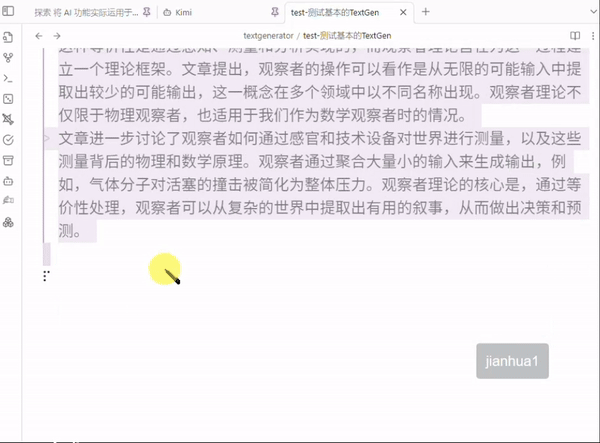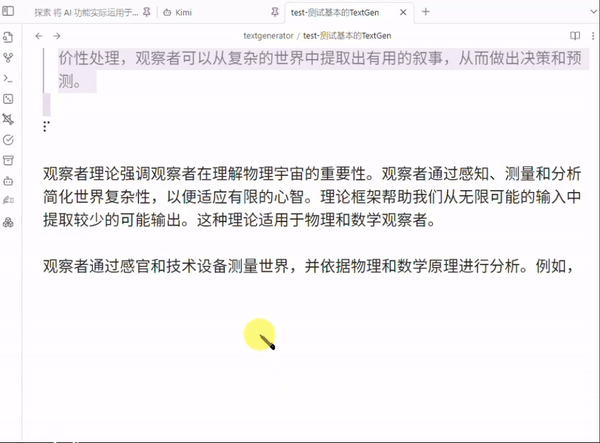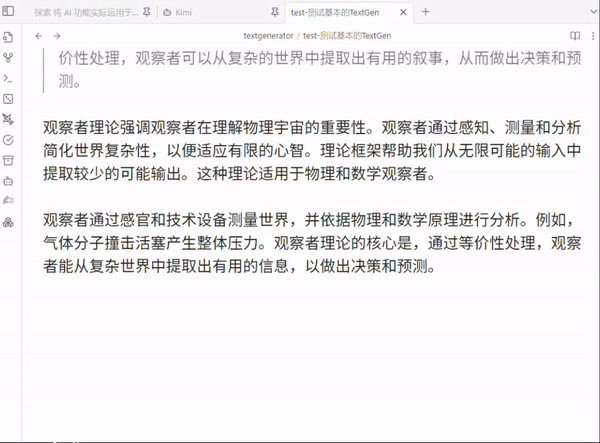
4 用 Playground 调试模板
Template Playground, 这是好东西, 调试必备, 可以看看你发给 LLMs 的精确文本到底是个啥, 比如:
- 模板里啥是
{{context}}? - 选区
{{selection}}和{{tg_selection}}的区别? - 当前句子
{{cursorSentence}}能认中文标点吗? - 反链列表
mentions.linked具体输出的啥格式? - … 更多见 Understanding Context 示意图挺清楚
以上都不用猜, 也别查文档了, 直接拿 Template Playground 预览一看便知
Playground 启动方式是 Ob 里运行命令 Open Template Playground
试试把下面的贴到 Playground 里, 然后选中一小部分笔记, 点一下 Preview
#### TG Selection:
```
{{tg_selection}}
```
#### Selection:
```
{{selection}}
```
#### Context:
```
{{context}}
```
#### Note Content:
```
{{content}}
```
Playground 点击预览按钮, 默认不会发请求给 LLMs
5 测试提取网页
TextGen 内置了抓网页的工具函数
完整语法见
// 单行写法
{{extract "web_html" "https://lilianweng.github.io/posts/2024-02-05-human-data-quality/" "article"}}
// 块写法
{{#extract "web_md" "my_content" "article"}}
https://lilianweng.github.io/posts/2024-02-05-human-data-quality/
{{/extract}}
// 两个写法等价, 第二种可控性更好, 提取的结果存到 my_content 里
这一小段 extract 函数也是合法模板, 在 Playground 里测应该跑通,
顺便可以自己改改 extract 的参数:
extract "web" 默认格式化 markdown, 即 "web" 等同于 "web_md"
extract "web_md" 见上
extract "web_html" 格式化为 html
extract "web" "https://xxxxxxxx" "article"
"article" 是 cssSelector, 用于提取网页网页的特定部分
如果改成
extract "web" "https://xxxxxxxx" "a"
这个 "a" 就是只提取该文档里的链接的意思
省略 "article" 这参数, 就是默认提取整个页面
实践 造个总结文章模板
现在工具全了, 开整
level1 选中单个 url 提取正文并总结
先来实现: 让 TextGen 访问笔记当前选中的 url, 抓取正文, 以中文总结文章说了啥
整理完善的模板如下
---
promptId: SummaryArticleFromWebPageURL_lv1
name: 总结一个网页level1
description: 总结一个网页, 要求选中 url 部分, 暂不支持 [title](url) 和 [[my_local_note]] 两种形式
---
根据以下文章, 使用简短清晰的语言做 "总结摘要", 注意事项:
- 可以适当抄原文的段落或重点, 要多提及文章亮点和独特之处
- 不要写基本的背景知识介绍
- 对英文文章也生成中文摘要, 不要生成英文摘要
- 不要去读文章里的链接, 图片, 只关心我提供的文字就行
- 摘要必须尽量短小
- 如果原文里有写类似 "总结" 的段落, 可在摘要后, 原样抄一遍 "总结" 部分, 你的摘要和原作者总结都保留
- 直接回复最终生成的摘要文本即可, 不必说其他的
- 如果文章正文明显有误, 例如文章太短, 或文章只含一个 url, 就回答: 无法做摘要, 并原样输出这个错误的正文
以下是需要摘要的正文, 位于 "-------------" 之间 :
-------------
{{#extract "web" "main, article, div#main"}}
{{tg_selection}}
{{/extract}}
-------------
以下段落当成测试例子应该不错, 这些文章都很长, 且博客列表页没给你提供摘要
Introducing Chat Notebooks: Integrating LLMs into the Notebook Paradigm—Stephen Wolfram Writings
https://writings.stephenwolfram.com/2023/06/introducing-chat-notebooks-integrating-llms-into-the-notebook-paradigm/
Can AI Solve Science? (很长, 8k 模型不够, 32k 可以)
https://writings.stephenwolfram.com/2024/03/can-ai-solve-science/
Observer Theory (很长, 8k 模型不够, 32k 可以)
https://writings.stephenwolfram.com/2023/12/observer-theory/
执行模板前, 要精确选中 url, 周围可以有换行和空格, 但不要多选到标题文字上
大部分网页的正文都在 main, article, div#main 之类的标签里
抓取别的网站, 要自己把正文所在 css selector 写到 extract 第三参数里
level2 智能识别各种格式链接
如果选中文本里的链接有各种形态, 比如类似下面这样的
ChatGPT出来后,我们是否真的面临范式转变
https://hub.baai.ac.cn/view/22901
[LLM Powered Autonomous Agents | Lil'Log](https://lilianweng.github.io/posts/2023-06-23-agent/)
> [!tip]
> 这篇其实更早啊, 原文叫 "A Closer Look at Large Language Models Emergent Abilities"
> Notion 原文 [A Closer Look at Large Language Models Emergent Abilities](https://yaofu.notion.site/A-Closer-Look-at-Large-Language-Models-Emergent-Abilities-493876b55df5479d80686f68a1abd72f)
> Notion 译文 [深入理解语言模型的突现能力](https://yaofu.notion.site/514f4e63918749398a1a8a4c660e0d5b)
- [ ] Chat Notebooks 试试
- https://writings.stephenwolfram.com/2023/06/introducing-chat-notebooks-integrating-llms-into-the-notebook-paradigm/
现在要去掉无关文字, 只想要里面 url 部分, 怎么搞?
- 以前的想法: 写个正则提取 url
- 现在的想法: 先丢给大模型试试…
以下提示词可以做到, 输入 当前选中文本 (文本含数个链接), 输出 一行一个url
可以把它看做一个 “LLMs 工具函数”
---
promptId: ExtractURLsFromSelectingText
name: 提取段落里的链接 Extract Web Links
description: 提取文本中的链接, 要求选中带链接的文本块
---
提取以下文本段落中的链接 (url), 链接可能混在段落里, 形如 `[title](url)`, 或者链接是单独在一行里的 `标题 url 附带描述`
只需要保留 url, 提取后, 按照一行一个 url 输出, 不用说别的话, 不要每行起始时带特殊语法格式, 不要包在代码块里
下面是需提取链接的文本段落, 位于 "-------------" 之间 :
-------------
{{tg_selection}}
-------------
这提示词我自己测大多数时候是可用的, 极少数情况 LLMs 会给你乱改返回格式
那么接下来, 要让外层的 “生成摘要的模板”, 调这个 “提取链接的模板”
首先, 确保上面这个模板 (将被调用, 负责提取链接) 放在这个路径里:
<仓库root>/textgenerator/templates/my_tmpls/模板文件名.md
模板文件名随意
但promptId必须是ExtractURLsFromSelectingText
然后, 让外部模板 (负责生成摘要) 调用它, 语法是
{{#run "my_tmpls/ExtractURLsFromSelectingText" "block_with_urls"}}
{{tg_selection}}
{{/run}}
外层模板调用 `my_tmpls/ExtractURLsFromSelectingText`,
结果存到 "block_with_urls" 里
外层模板最终输出:
{{get "block_with_urls"}} <-- 变量要 get
{{log vars.block_with_urls}} <-- 提取到的链接, 多行字符串, 不要有别的符号
{{notice vars.block_with_urls}}
把上面代码搁 Playground 里试试, 会看到 TextGen 的模板可以相互调用
当然, 用 LLMs 来提取简单段落里的 urls, 这是大材小用了,
也可以使用代码方式, 如下:
// 输入一段复杂文本, 输出每行一个url, 使用 LLMs 引擎
{{#run "my_tmpls/ExtractWebLinksFromSelection" "block_with_urls"}}
{{tg_selection}}
{{/run}}
// or 使用正则提取 url,
// 两者都是把当前选区的 urls 存到 block_with_urls 变量, 二选一, 别都用
{{#script}}
function extractUrls(text) {
const urlRegex = /https?:\/\/[^\s]+\b/g;
let urls = [];
let match;
while ((match = urlRegex.exec(text)) !== null) { urls.push(match[0]); }
return urls;
}
this.vars.block_with_urls = extractUrls(this.tg_selection).join('\n\n');
return "";
{{/script}}
{{notice vars.block_with_urls}}
{{log vars.block_with_urls}}
这里只做到提取 urls, 先不做抓页面和总结, 已解析到链接如下:
{{vars.block_with_urls}}
测试可行后, 在 level2 先来实现: 选中一堆文字, 总结第一个遇到的 url (之后再遇到 url 不管)
该模板大致写成这样:
---
promptId: SummaryArticleFromWebPageURL_lv2
name: 总结一个网页level2
description: 总结一个网页, 要求选中文本中含有任意格式的 urls, 例如 [title](url) 和 单行的 "标题 url 额外备注" 等形式, 只会处理第一次遇到的 url
---
{{#run "my_tmpls/ExtractURLsFromSelectingText" "block_with_urls"}}
{{tg_selection}}
{{/run}}
{{notice vars.block_with_urls}}
{{#script}}
const first_webpage_url = this.vars.block_with_urls.trim().split('\n')[0];
this.vars.first_webpage_url = first_webpage_url
return "";
{{/script}}
{{notice vars.first_webpage_url}}
根据以下文章, 使用简短清晰的语言做 "总结摘要", 注意事项:
- 可以适当抄原文的段落或重点, 要多提及文章亮点和独特之处
- 不要写基本的背景知识介绍
- 对英文文章也生成中文摘要, 不要生成英文摘要
- 不要去读文章里的链接, 图片, 只关心我提供的文字就行
- 摘要必须尽量短小
- 如果原文里有写类似 "总结" 的段落, 可在摘要后, 原样抄一遍 "总结" 部分, 你的摘要和原作者总结都保留
- 直接回复最终生成的摘要文本即可, 不必说其他的
- 如果文章正文明显有误, 例如文章太短, 或文章只含一个 url, 就回答: 无法做摘要, 并原样输出这个错误的正文
以下是需要摘要的正文, 包裹在 "-------------" 之间 :
-------------
{{#extract "web" "main, article, div#main"}}
{{vars.first_webpage_url}}
{{/extract}}
-------------
我最后没搞定以它现有的 helper 函数, 怎么把多行字符串按行 split 之后放进 #each 迭代, 所以拆分 url 还是先用 script 解决的…
level3 批量总结多个文章
至此已经有如下工具:
- 模板A
SummaryArticleFromWebPageURL_lv1- 输入一个 url, 内部自动访问网页, 输出该文章的中文简要总结
- 模板B
ExtractURLsFromSelectingText- 输入多行文本, 输出其中 urls, 每行一个
- 懒, 直接发给 LLMs 去干的
- 模板B2
ExtractURLsFromSelectingTextRegExp- 功能同上, 老实以 js 函数实现的
- 模板C
SummaryArticleFromWebPageURL_lv2- 输入多行文本, 只把第一个遇到的 url 做总结
- 在内部调用 模板B (或 模板B2)
- 主要为测试模板间怎么调用
把所有的工具整合一下, 并对 模板C 做升级, 最终就可以实现: 输入多行文本, 提取其中所有 urls, 对所有文章做总结摘录
---
promptId: SummaryArticleFromWebPageURL_lv3
name: 总结多个网页level3
description: 批量总结网页, 要求选中文本中含有任意格式 urls, 例如 [title](url) 和 "标题 url 额外备注" 等形式, 自动抓取正文聚合后一次性总结, 相近主题的文章可能被总结在一起
---
{{#script}}
function extractUrls(text) {
const urlRegex = /https?:\/\/[^\s]+\b/g;
let urls = [];
let match;
while ((match = urlRegex.exec(text)) !== null) { urls.push(match[0]); }
return urls;
}
this.vars.block_with_urls = extractUrls(this.tg_selection).join('\n\n');
notice(`当前 urls 总共:\n ${this.vars.block_with_urls}`);
return "";
{{/script}}
{{#script}}
```js
// block_with_urls 可能是 LLMs 返回的, 此时是多行文本, 需按行拆开
this.vars.url_list = this.vars.block_with_urls.split('\n')
.map(line => line.trim())
.filter(line => line.startsWith('http'));
notice(`准备获取 ${this.vars.url_list.length} 篇文章:\n${this.vars.url_list}`);
const article_list = [];
for (let index = 0; index < this.vars.url_list.length; index++) {
const url = this.vars.url_list[index];
// 文章主体部分可能在多种标签里 例如 main div#main article 不好统一
const selector = "main, article, div#main, div.site-body-center-column, div#content";
article_list.push(await extract("web", url, selector));
}
this.vars.article_list = article_list;
notice(`已获取 ${article_list.length} 篇文章正文, 总字符数 ${article_list.map(article => article.length).reduce((sum, charCount) => sum + charCount, 0)}`);
return "";
```
{{/script}}
{{#script}}
```js
// 对所有的文章正文, 控制一下总体字符数
// 拼接提示词时, 多篇文章共享 25000 字的总额度
// 最好是按 tiktoken 去算
const max_chars = 25000; // 适合 32k token 模型
function truncate_article(content, limit) {
// 删减到指定字数, 尽量保留头尾, 在换行处截断, 不要截到单词中间
if (content.length <= limit) { return content; }
const head_length = Math.floor(limit * 0.7);
const tail_length = limit - head_length;
const content_head = content.slice(0, head_length);
const content_tail = content.slice(-tail_length);
return `${content_head} ... 以下省略约 ${content.length - limit} 字... ${content_tail}`;
// const content_lines = content_head.split('\n') + [`... 以下省略约 ${content.length - limit} 字...`] + content_tail.split('\n');
// return content_lines.join('\n');
}
const article_list = this.vars.article_list;
const total_chars = article_list.map(article => article.length).reduce((sum, charCount) => sum + charCount, 0);
const truncated_articles = article_list.map((article, i)=> {
const limit = Math.floor(article.length * max_chars / total_chars);
const truncated = truncate_article(article, limit);
return truncated;
}
);
this.vars.output_articles = truncated_articles.map((truncated, i) => {
return `第${i+1}篇文章:\n\nurl: ${this.vars.url_list[i]}\n\n${truncated}`
}).join('\n\n\n\n@@@@@@@@\n\n\n\n');
return "";
```
{{/script}}
根据以下一到多篇文章, 使用简短清晰的语言做 "总结摘要", 注意事项:
- 如果有多篇文章, 可以把主题近似的文章一并总结, 可以调整文章顺序
- 要保留 "第n篇文章" 和 url, 让人能知道总结和原文的对应关系
- 可以适当抄原文的段落或重点, 要多提及文章亮点和独特之处
- 不要写基本的背景知识介绍
- 对英文文章也生成中文摘要, 不要生成英文摘要
- 不要去读文章里的链接, 图片, 只关心我提供的文字就行
- 摘要必须尽量短小
- 如果原文里有写类似 "总结" 的段落, 可在摘要后, 原样抄一遍 "总结" 部分, 你的摘要和原作者总结都保留
- 直接回复最终生成的摘要文本即可, 不必说其他的
- 使用 markdown 格式化你的回答, 可以适当加粗 `**需要加粗的字**`, 划重点一些文字 `==需要高亮的字==`, 可以保留图片 `` 可以保留关键概念的链接 `[keyword](url)`
- 如果文章正文明显有误, 例如文章太短, 或文章只含一个 url, 就回答: 无法做摘要, 并原样输出这个错误的正文
以下是需要摘要的一到多篇文章的正文, 每篇文章以 "@@@@@@@@" 分割, 所有文章位于 "-------------" 之间 :
-------------
{{vars.output_articles}}
-------------
这里为防止写的过于复杂, 我又把 js 脚本搁回一个模板里了,
实践中, 不同功能拆分比较好, 让模板能灵活使用,
然后以互调方式实现综合功能
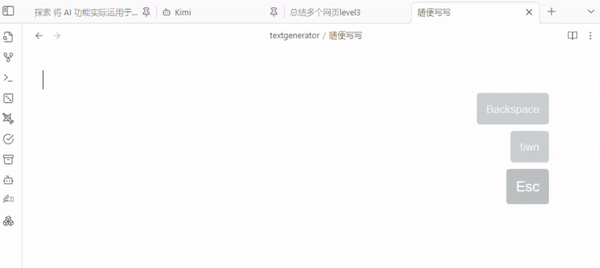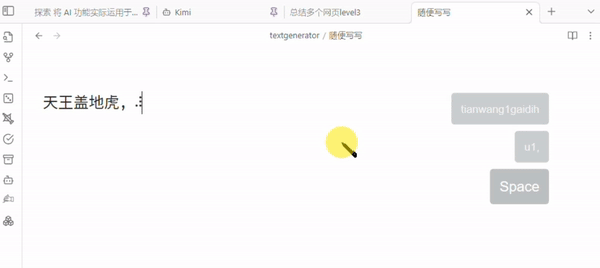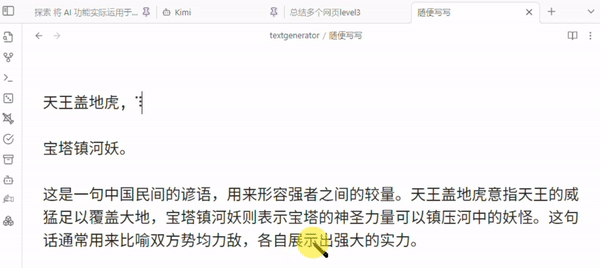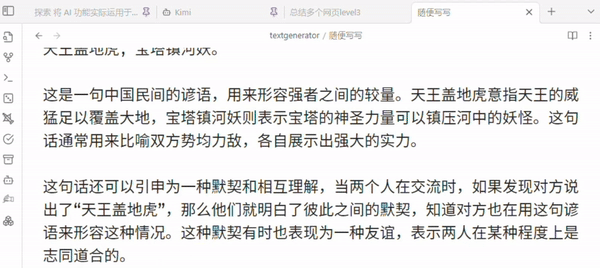
最后效果如下
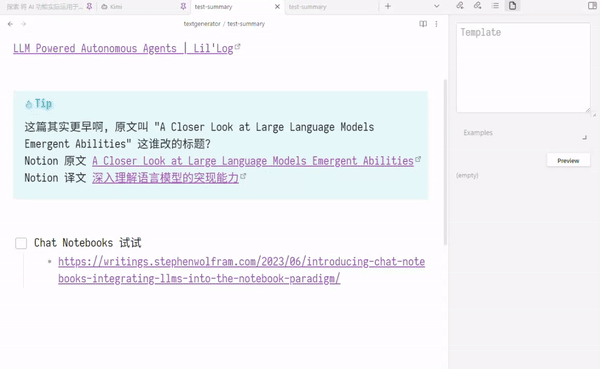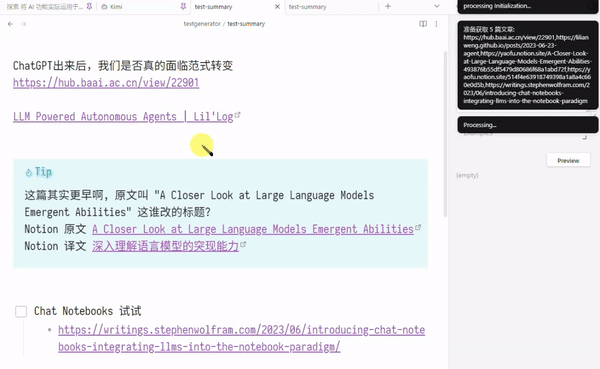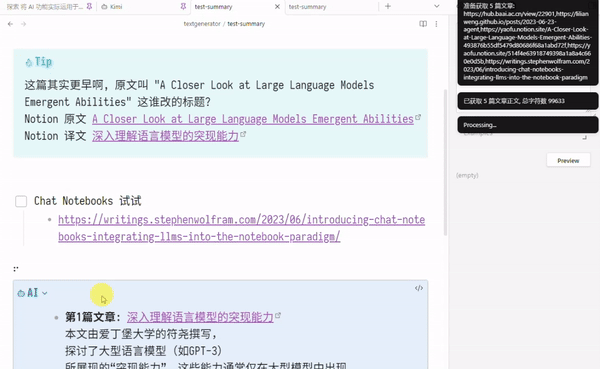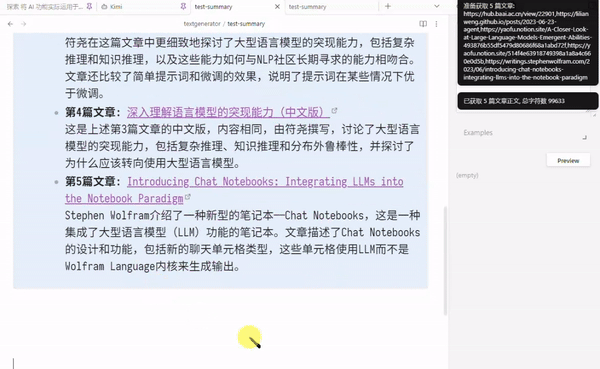

注: 这里提交给 LLMs 的仅是 “第几篇文章 + url + 文章正文删减版”
并未包括 “页面标题和来自笔记的提示信息” 如 原文 译文 字样 (但正文里译者一般会提)
例子中, 第三篇和第四篇是内容近似的文章, 被总结时, AI 顺便提了一嘴这俩文章有关
至此我已基本达到目的,
显然这方案仍有许多可优化之处, 以后再慢慢鼓捣吧, 感谢大家看到这里
