通过日记流水账方式零碎的记一些工作上的事,利用dataviewjs将标题汇总在相关标题的页面中,方便查看。
页面:2024年1月3日、2024年1月2日、2024年1月3日、日常工作、项目A、项目B
文件名:2024年1月1日
内容:
# [[日常工作]]
电话联系了谁谁谁。
干了什么什么。
- [ ] 记得打电话给谁谁谁说什么什么
# [[项目A]]
进度到了XX程度
预览效果:

文件名:2024年1月2日
内容:
# [[日常工作]]
电话联系了谁谁谁。
干了什么什么。
- [ ] 记得打电话给谁谁谁说什么什么
# [[项目A]]
进度到了完工程度
# [[项目B]]
开工了
预览效果:

文件名:2024年1月3日
内容:
# [[日常工作]]
电话联系了谁谁谁。
干了什么什么。
- [ ] 记得打电话给谁谁谁说什么什么
# [[项目B]]
进度到了完工程度
预览效果

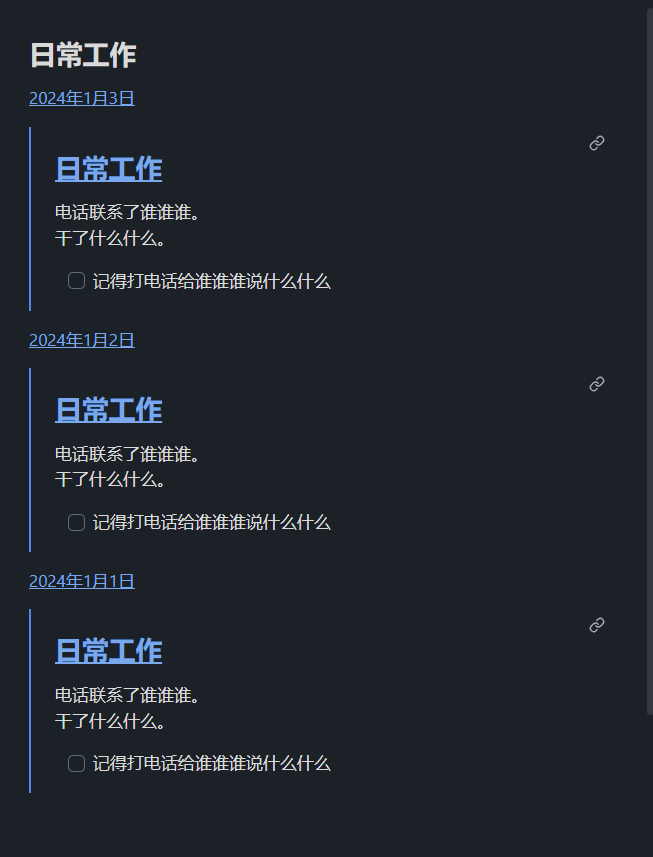
文件名:日常工作
内容:
dv.pages('[[日常工作]]').sort(f => f.file.ctime ,'desc').forEach(p => {
dv.paragraph(dv.fileLink(p.file.name))
dv.paragraph(dv.fileLink(p.file.name+"#日常工作", true))
})
预览结果:
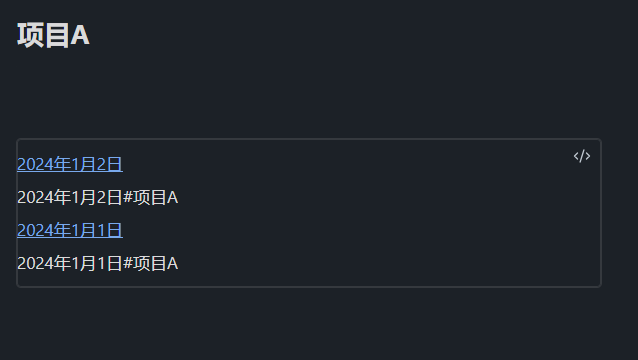
文件名:项目A
内容:
dv.pages('[[项目A]]').sort(f => f.file.ctime ,'desc').forEach(p => {
dv.paragraph(dv.fileLink(p.file.name))
dv.paragraph(dv.fileLink(p.file.name+"#项目A", true))
})
预览结果:

文件名:项目B
内容:
dv.pages('[[项目B]]').sort(f => f.file.ctime ,'desc').forEach(p => {
dv.paragraph(dv.fileLink(p.file.name))
dv.paragraph(dv.fileLink(p.file.name+"#项目B", true))
})
预览结果:

问题来了
看似全部汇总了,把流水日记中标题下的内容全部引用过来了.
但是
如果把文件 2024年1月3日里内容调整下
# [[日常工作]]
电话联系了谁谁谁。
干了什么什么。
- [ ] 记得打电话给谁谁谁说什么什么
# [[项目B]]
进度到了完工程度
改为
# [[日常工作]]
电话联系了谁谁谁。
干了什么什么。
- [ ] 记得打电话给谁谁谁说什么什么
# [[项目B]]
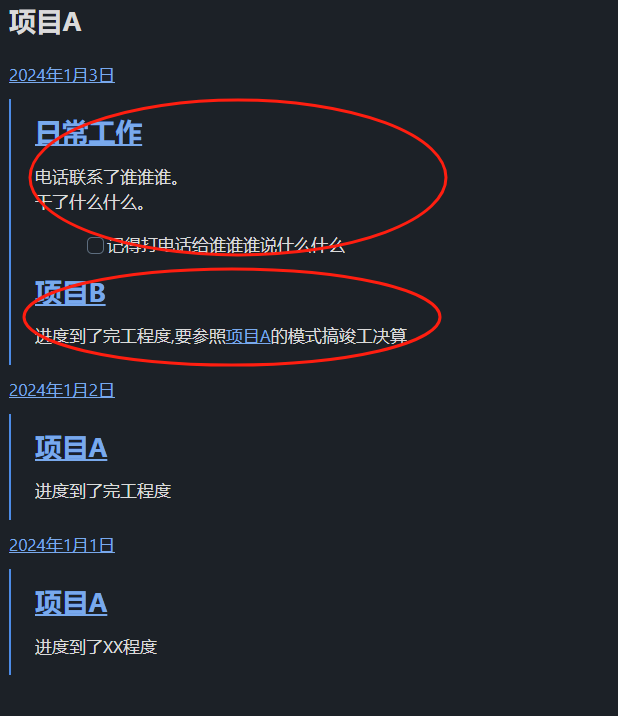
进度到了完工程度,要参照[[项目A]]的模式搞竣工决算
之所以用[[项目A]]这个字眼,是因为实际的项目名称会很长用到[]这个相当于是代码自动完成.减少输入错误和快速输入的目的
但是dataviewjs通过连接搜索到 [[项目A]],会生成一个![[2024年1月3日#项目A]],实际上文件2024年1月3日中没有 项目A 这个标题.等同于把无效信息拉取过来了,变成了![[2024年1月3日]]这种的结果,把整个2024年1月3日页面全部拉取过来了.
想到了通过dataviewjs来把不是包含 # [[XXX]] 的页面过滤掉.
1.通过修改项目A页面的内容为
dv.pages('[[项目A]]').sort(f => f.file.ctime ,'desc').forEach(p => {
const file =await app.vault.readRaw(p.file.path)
if (content.match(/\# \[\[项目A\]\]/) !=null){
dv.paragraph(dv.fileLink(p.file.name))
dv.paragraph(dv.fileLink(p.file.name+'#项目A', true))
}
})
const file =await app.vault.readRaw(p.file.path)
提示必须要在第一层使用 await 关键字.
改
const file = app.vault.readRaw(p.file.path)
提示 content没有match这个方法.
2.改用for循环.修改项目A页面的内容为
let files=dv.pages('[[项目A]]').sort(f => f.file.ctime ,'desc')
for(let i of files) {
let content = await app.vault.readRaw(i.file.path)
if (content.match(/\# \[\[项目A\]\]/) !=null){
dv.paragraph(dv.fileLink(i.file.name))
dv.paragraph(dv.fileLink(i.file.name+'#项目A', true))
}
}
这样确实能排除掉 不是标题的 [[项目A]],但是双链变没了,变成了正文.