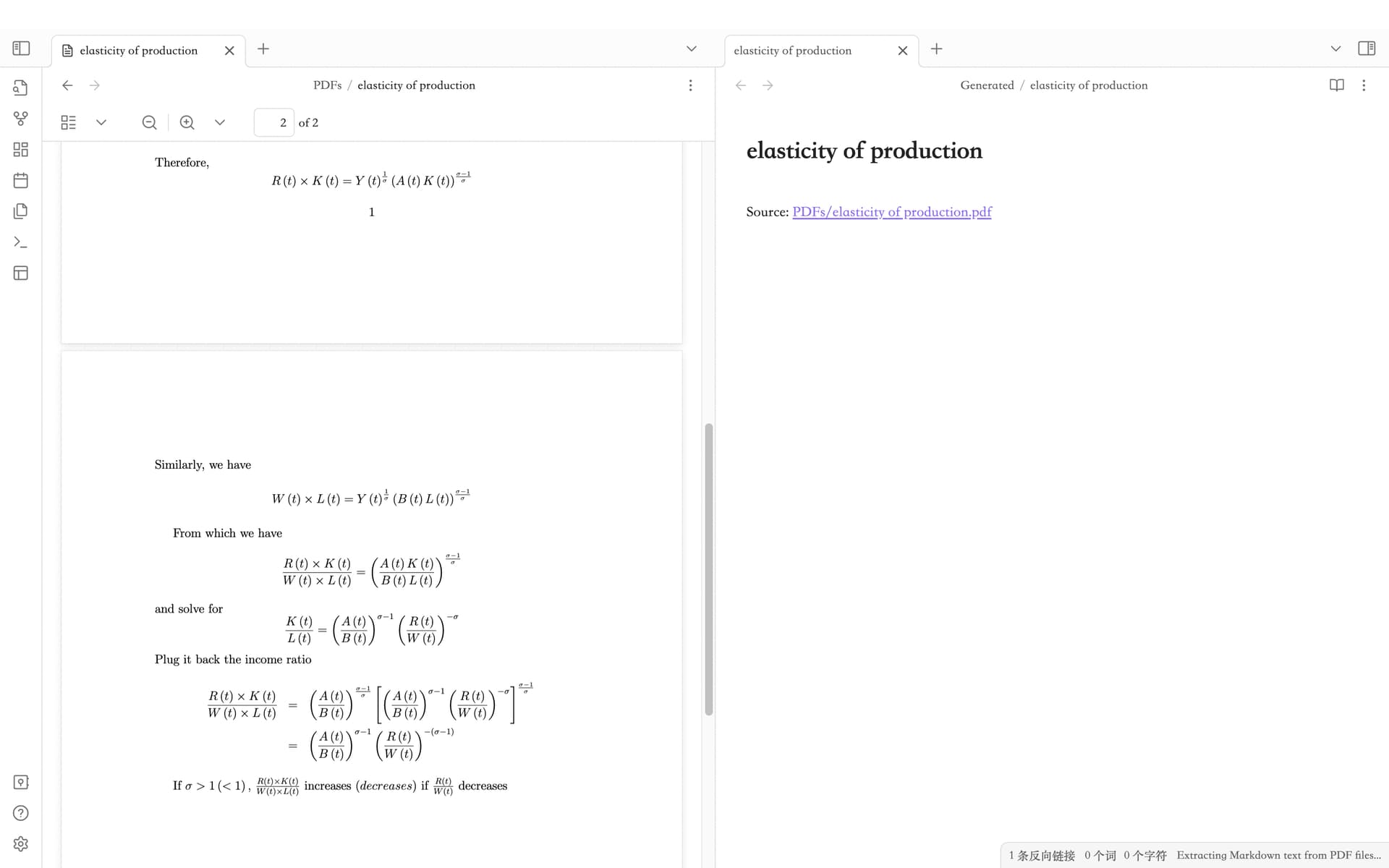
问题:为什么我转换出来的结果只有一行标题?
该插件作者地址:https://github.com/liammagee/obsidian-topic-linking#extract-pdf-content
大概看了一下,但没找到该怎么做。求大佬指点
问题:为什么我转换出来的结果只有一行标题?
该插件作者地址:https://github.com/liammagee/obsidian-topic-linking#extract-pdf-content
大概看了一下,但没找到该怎么做。求大佬指点
你是怎么用的,我下载好了插件并且启用了,但是不知道怎么把pdf转成markdown
插件作者自己写了 “This plugin is highly experimental”
我自己卡在 pdf 生成 markdown 时, 它一定要给还原 pdf 中的字体,
然后报错只留下个空壳文件, 里面就一行 source
具体说, 我卡在 main.js line:50618 } else if (fnType === this.pdfjs.OPS.setFont) { ... } 这一段设置字体是跑不通的
禁用后, 起码 pdf 转 markdown 能生成出来 (不排除某些 pdf 还是转不了)
附: 简单禁用可以编辑
else if (fnType === this.pdfjs.OPS.setFont)
=>
else if (false && fnType === this.pdfjs.OPS.setFont)
完后, 可以 pdf 转 markdown, 可以 Link Topics,
但没看懂他这 Topics 咋用, 用 LDA 扫关键字好在哪? 适合啥样子的文档? 如果中文能否有效利用? 这些全都没看懂
so, 老哥现在用的是什么方案呢?
如果指pdf转文字:
现在我是用 Umi-OCR, Paddle-OCR, 各种云平台等,
且老老实实的, 尽量事先做好图片预处理, 分栏, 删页头页脚等,
感觉宁可前期麻烦一点, 也比提交 ocr 之后再修文字要好
如果指 LDA 扫主题和对文档评分:
这个 topic linking 插件简单看了一眼, 它连中文分词都没做啊, 就只一个 .split(" ")
也许对英文文本的分析是能胜任的, 但跟我需求不太相符
后来没太关心这个, 我还在继续折腾向量嵌入…