遥远
1
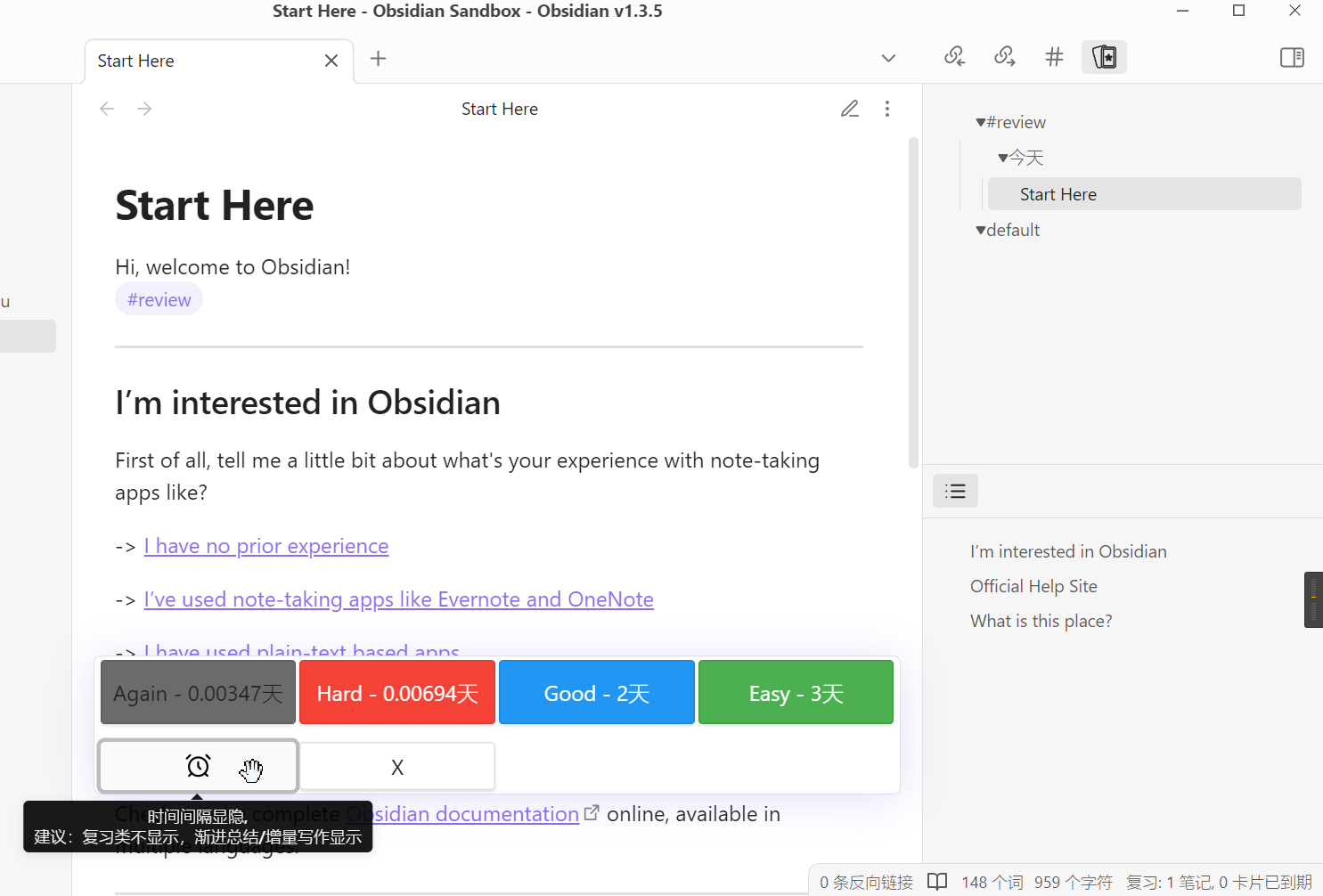
相对原版的obsidian-spaced-repetition,做了一部分魔改:
- 复习时间信息可以保存在单独文件内,不修改原笔记文件内容;
- 在复习笔记时可以显示悬浮栏(跟复习卡片时类似),方便选择记忆效果,且可显隐到下次重复的时间间隔;
- 可以只转换复习笔记到卡片组,而不是全部库的笔记都转换;
- 算法可以切换:默认的Anki优化算法、Anki算法、Fsrs算法;
- 其他待发现的小改动;
注意
没有使用过obsidian-spaced-repetition插件的可以直接用,正在使用obsidian-spaced-repetition插件的话,建议试用前先备份 
欢迎大家试用讨论
适用场景
- 间隔重复复习;
- 渐进式总结;
- 增量写作;
下载
推荐BRAT直接添加github链接更方便些
由于仓库转移了,请换用新地址 github: GitHub - open-spaced-repetition/obsidian-spaced-repetition-recall: Fight the forgetting curve by reviewing flashcards & entire notes on Obsidian.md · GitHub
11 个赞
iccth
2
原笔记修改内容后, 复习时间信息还能锁定该条笔记吗?
笔记可以。
卡片目前还有些不准确,如果不修改卡片信息所在行或改内容不改行,基本也没问题;同时修改内容和行号就找不准确这个卡片的时间信息了 
iccth
6
插入内容改变行号还是挺频繁的, 我现在对笔记的洁癖也没要求了,要不还是让用户自己选怎么保存复习记录吧
嗯,是可选的,可以像原来那样处理,不过我改动时是以独立保存为基础的,如果要卡片时间信息保存到原笔记中,推荐还用原来的插件就好。
我卡片复习用的不多,主要想重复整个笔记的,不想复习个笔记,原笔记内容就修改了。
哇!好棒
不过如果能用FSRS4ANKI的optimizer就好了
有一个bug,当我使用FSRS算法的时候,如果我去修改request_retention,修改过之后重新打开obsidian,request_retention会重新变成默认的0.9.
不过只是在obsidian中显示的是0.9,如果打开data.json的话,会发现request_retention已经变成我修改过的数值了,即便是重新打开也不会变化。
遥远
11
这块当时大概看了下,代码量太大,没看懂,就先不管了,你可以试着fork一份加进去 
我也不懂 ,我除了MATLAB之外啥编程语言都不会。不过其实可以问问叶大,看看optimizer有没有办法直接输入复习数据
,我除了MATLAB之外啥编程语言都不会。不过其实可以问问叶大,看看optimizer有没有办法直接输入复习数据
我在知乎问叶大关于optimizer对第三方软件的支持,叶大说remnote端的optimizer支持导入CSV文件,我看看remnote的FSRS插件是什么样的以及导出的CSV格式是怎样的–不过我肯定是没有能力让这个插件支持optimizer
FSRS4remnote导出的CSV结构大概是这样的,我觉得cid是卡片的ID,id是某一次复习的ID,前者一个卡片复习多少次都是同一个ID,后者每次复习ID都不一样。两个ID似乎都是unix时间戳,前一个是创建时间的时间戳,后一个是复习时间的时间戳
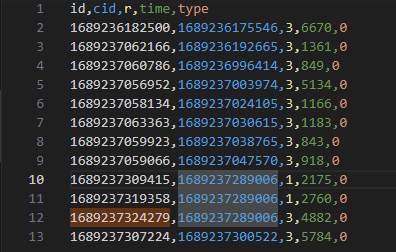
按理说,只要照着导出的CSV按照相同的格式导出就行,id用复习的时间转换成UNIX时间戳,cid的话,我猜想可以用卡片在插件里的ID的哈希替代。
遥远
15
但用remnote的optimizer又要再转手一次,后边我请教下他,看能不直接输出一个日志文件,在他的fsrs4anki_optimizer上跑
用remnote的optimizer倒也不算是又转手一次,毕竟都是叶大写的,代码大部分也都一样,不过remnote的optimizer确实更新的比FSRS4ANKI的optimizer慢不少,估计FSRS4.0算法的支持也会晚一些。
JarrettYe
(Jarrett Ye)
18
Optimizer 用的都是同一个包,同步更新的。另外 Anki 导出的数据库,Optimizer 在预处理的时候也是要转成 csv 的。
1 个赞
遥远
19
感谢叶学委的回复,但看你的optimizer中,说是生成的./revlog_history.tsv,点开这个链接后并没有看到示例文件(我没有使用Anki,无法自己导出数据跑一个 )。
另外,请教下,表格文件的各列含义(df.columns = ['id', 'cid', 'usn', 'r', 'ivl', 'last_ivl', 'factor', 'time', 'type'])
比如,id 是每次的复习的时间(单位s),cid是首次复习时间?
希望能抽空完整说明下,最好带有示例表格文件 
FEI
(FEI)
20
老哥你得点回复,不然楼上是收不到邮箱的消息提醒的。
遥远
21
是点的回复叶学委,但似乎论坛没按点的方式回复。。。。呵呵了