写在前面
Dataview可谓是ob用户的必备的插件了,当你积累了10+篇自己的笔记,可以用它来生成目录。
在此之前,我想对造轮子说两句(因为dataview是造轮子的利器)。
写笔记也好,做什么东西也好,我认为很忌讳的一点是过度设计,废了很大的功夫想要在一切开始之前造一个完美的轮子,结果造完之后极大可能你的记笔记热情已经没有了。
所以我不建议你等待,等待任何笔记流程的设计。不是有了完美工作流之后你才能开始工作,而是做着做着就根据自己的场景和需要慢慢铺就了适合你的工作流。
这也是渐进式笔记的概念。ob当时带着双链和关系图谱出现,本意就是让使用者渐进式的搭建自己的知识库。
渐进式的观点还能很好的改善完美主义。(刚看完《如何成为不完美主义》的一点小启发。)
这也就是我为什么说等你积累到10篇以上,会需要这篇文章。如果你才开始记笔记,请先放下一切问题,先记起来。
言归正传,来看看dataview的使用场景。
使用场景
假设你现在积累了一众笔记,这些笔记之间除了双链还有一些关联,现在你想要一个目录,可以一目了然的聚合这些笔记。
以下是一些场景:
-
生成包含同样关键字的笔记的目录
-
生成同一个标签的笔记的目录
-
生成同一个作者的书目的目录
这时候,dataview就派上用场了。
dataview可以生成MOC,或者你也可以跟我一样,不去管MOC是什么,就把它当作一个目录。
我们知道,目录是一篇文章的概览。dataview其实生成了你的多篇文章目录。
如果你有这种需要的话,就接着看下去吧。
安装插件
众所周知(如果你不知道,现在可以知道了),ob插件有两种安装方式:
-
直接在
第三方插件->社区插件搜索安装 -
下载到插件文件,一般是一个插件文件夹,然后放在库目录下的
.obsidian/plugins目录下。(至于从哪里下载,可以从github或者有些群会下载下来共享)
设置:该插件不需要修改任何设置即可使用。
接下来就开始生成目录吧!
使用
方法千千万,我只写三种生成目录的方式:
-
从名字
-
从标签
-
从作者
如果有更多的需求,说明你是个高阶使用者,请去查看更高阶的文章,或者去看插件作者的官网。
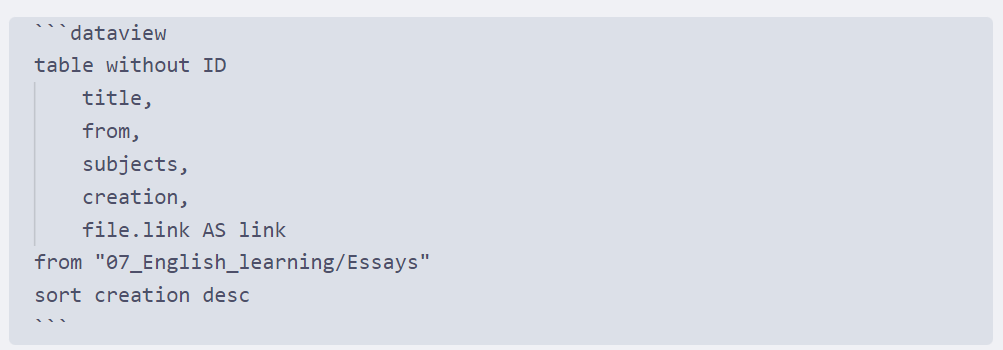
1.从文件名
场景:假设,现在你有多篇关于【习惯】的笔记,并且这些笔记的名称中都有“习惯”两个字。记录了好几个习惯养成的方法,今天你忽然意识到,关于习惯的方法论已经看了好几个了,想把它们列出来放到一起看看能不能产生什么化学效果。
老规矩,先贴一个语法和效果图:

下面讲讲规则,别害怕看“代码”,总共就5行,大部分还是不用改的,比如我上面的代码,其实你只用替换双引号里面的内容哟,是不是简单多了?
首先,dv语法要写到代码块里,如果有了解过markdown的小伙伴,应该对代码块不陌生。上下三个上撇,就是一个代码块。
在首行写上dataview,插件就可以识别这部分代码了。
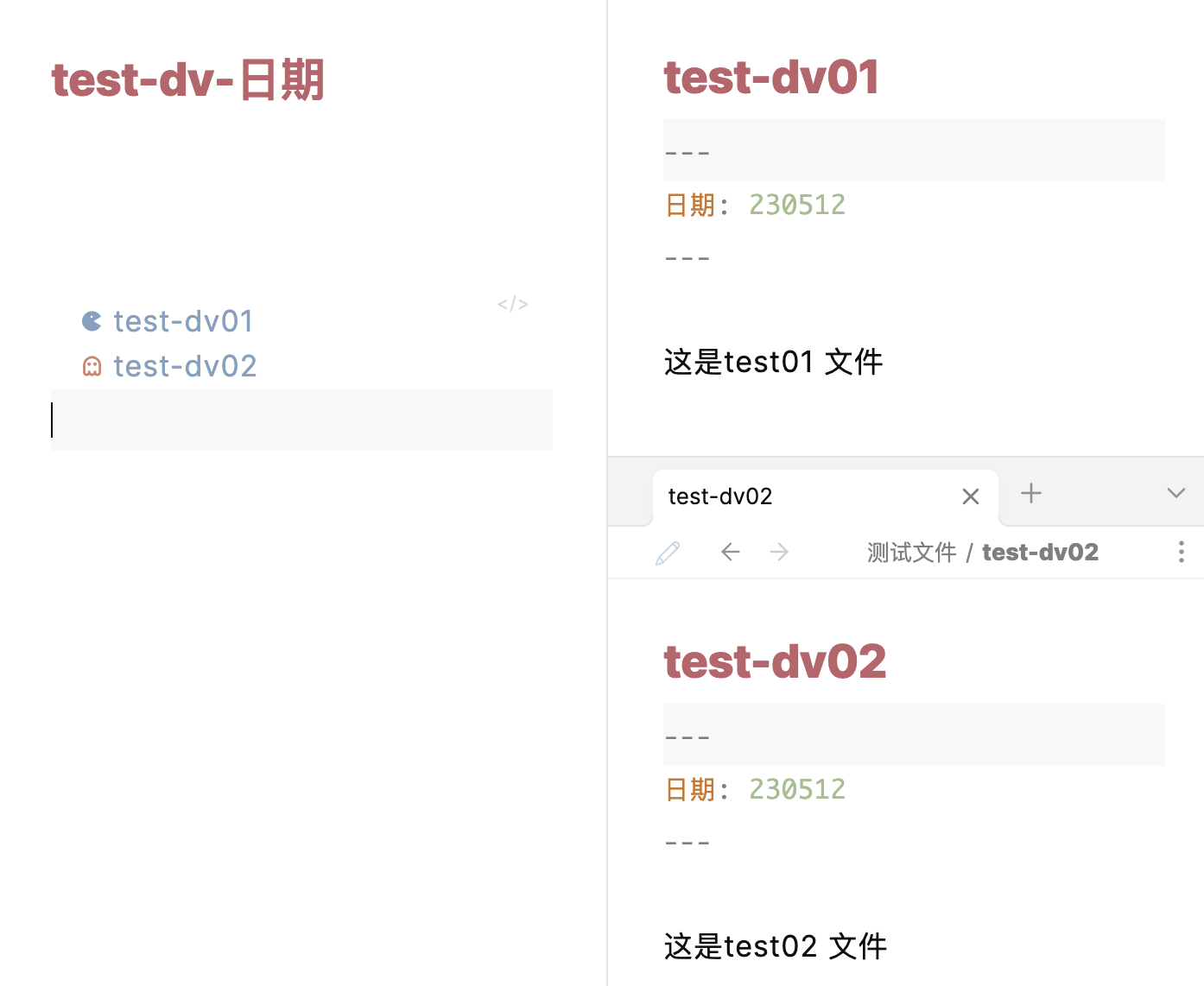
以上解释希望你看懂了。下面我举一个例子,还以开头的假设场景为例,你要怎么写呢?
dataview list from "" where contains(file.name,"习惯")
这样就可以了。
-
list:你创建了一个列表/清单。
-
from:留空就是不筛选文件夹和标签,从所有笔记文件去找。
-
where条件:匹配(contains)了文件名(file.name)中包含“习惯”两个字的笔记
如果你需要排序,就写sort,不需要,留空就可以。
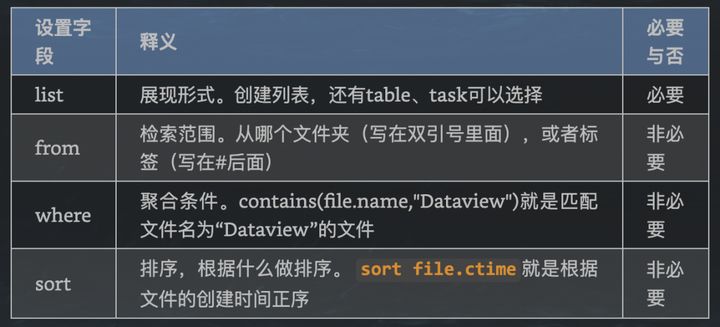
你应该发现了file.name和file.ctime的写法,没错,这是dataview内置的。下面是dataview官网中描述的支持的元数据,都可以供搜索和排序语法使用。在后面将要说到的创建table,还可以作为列显示。

上面的从文件名创建列表你看懂了的话,用从标签创建列表练习一下吧~其实上面有包含哦,但我们还是练习以下,以防有人没看懂。
2.从标签
场景:假设,你有几篇笔记,打了同一个标签,比如#时间管理。现在你想要把时间管理标签下的笔记形成一个目录。
你该怎么写dataview语句呢?
还记得上面的4个关键设置字段吗?from是检索范围,既可以从文件夹,又可以从标签。
dataview list from #时间管理
不需要排序的话,代码就是这么简单。
你学会了吗?
如果学会了,下面我们可以加点好玩的东西。
3.从作者
场景:假设,你最近读了同一个作者的几部作品(论文、书书籍、视频、电影都是一样的),形成了几篇笔记。笔记多了以后,你就想弄一个该作者的专题。这时候,有什么办法能做到呢?
哎,dataview的支持元数据里可没有作者这个属性啊,怎么办呢?
我们自己加属性!
这时候,yaml 就派上用场了。
![]() 用yaml给笔记加点元素
用yaml给笔记加点元素
简单的说yaml是一种标记语言。顺便说一下markdown也是一种标记语言。朴素的理解就是以某种规则写的一种文本。
各位,用工具的时候,我们可以不求甚解,拿过来学会怎么用就可以了,甚至,你只用知道怎么在自己的需求中用就可以了。
所以不需要特别去了解yaml。我们来看看yaml怎么为我们所用吧。
yaml语法大概长这样:
— title: 标题名字 author: 作者名 tags: [标签1] —
yaml的规则:
1、只要写在6个横杠符号之间,yaml就可以被识别。够简单吧?
2、必须写在文件最上方
里面的title、author我们叫它key,也就是你给这个字段起的名字,所有的key都是自己定义,没有必要的规则,就像你给表格起列名一样。yaml的key也支持中文名哦。例如这样:
作者: 鲁迅
我就给笔记加了“作者”这个属性。
然后我们就可以使用“作者”作为条件建立目录了。
另外根据读者反馈,增加两个注意点:
![]() 1. 字段名后面的冒号需要用英文,也就是半角符号
1. 字段名后面的冒号需要用英文,也就是半角符号
![]() 2. 冒号后面跟一个空格
2. 冒号后面跟一个空格
![]() dataview使用yaml的元素
dataview使用yaml的元素
where和sort就可以直接使用你在yml中设置的key了。看看下面的写法:
dataview list from "" where contains(作者,"鲁迅")
看下效果:
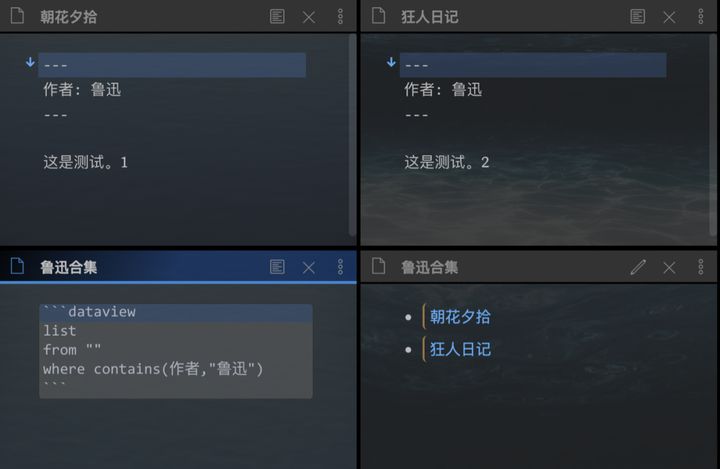
上面依次是:包含作者为“鲁迅”的原笔记、聚合作者为“鲁迅”的目录编辑模式、聚合作者为“鲁迅”的目录预览模式。
嗯哼,鲁迅合集就做好了。
扩展:创建一个书目列表吧!
上面你已经学会了限制检索范围、模糊搜索文件名来创建列表,学会了从标签创建列表,还学会了用yaml定义的key当作字段做条件,基本的检索语法你已经学会啦。
现在我们想在展示形式上有所改变,比如书目列表。我不想只展示作品的名字,我还想展示作者、阅读日期、标签。
还记得上面列表中的展示形式吗?
对,就是dataview语法的第一行那个list,现在我们来变一下,写个table吧。
不过我们的语法有一点小小的改动。既然是table,那么列名就必不可少。
先贴一下代码看看吧:
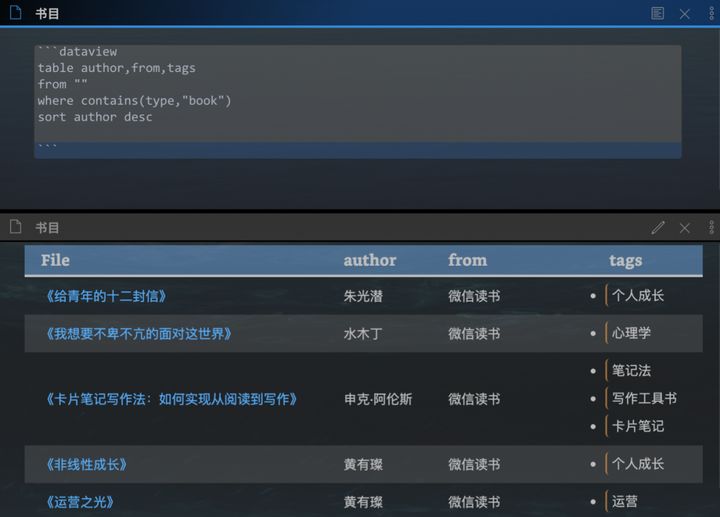
上面唯一的变化就是table这一行:
table author,from,tags
table后面这三个字段就是我为表格设计的列。而author是我为笔记中的作者元素,from是书籍来源,tags是标签。这三个元素都写在来yaml,如今被dataview识别,就可以展现我想要的列表。
where条件里,我写的匹配字段是type,这也是我yaml里面的元素,表示输入内容,自定义了三个值:book、page、video。
sort这句,用author字段排序,后面跟了一个desc,表示倒叙。
怎么样,你学会了吗?
- End -
以上,dataview常用的内容就讲完啦。task展示类型就暂时不讲了,笔者本人使用的不多。
如果你有什么不明白的,也可以在留言区告诉我
谢谢你看到这里
 。
。