需要准备的calibre插件
-
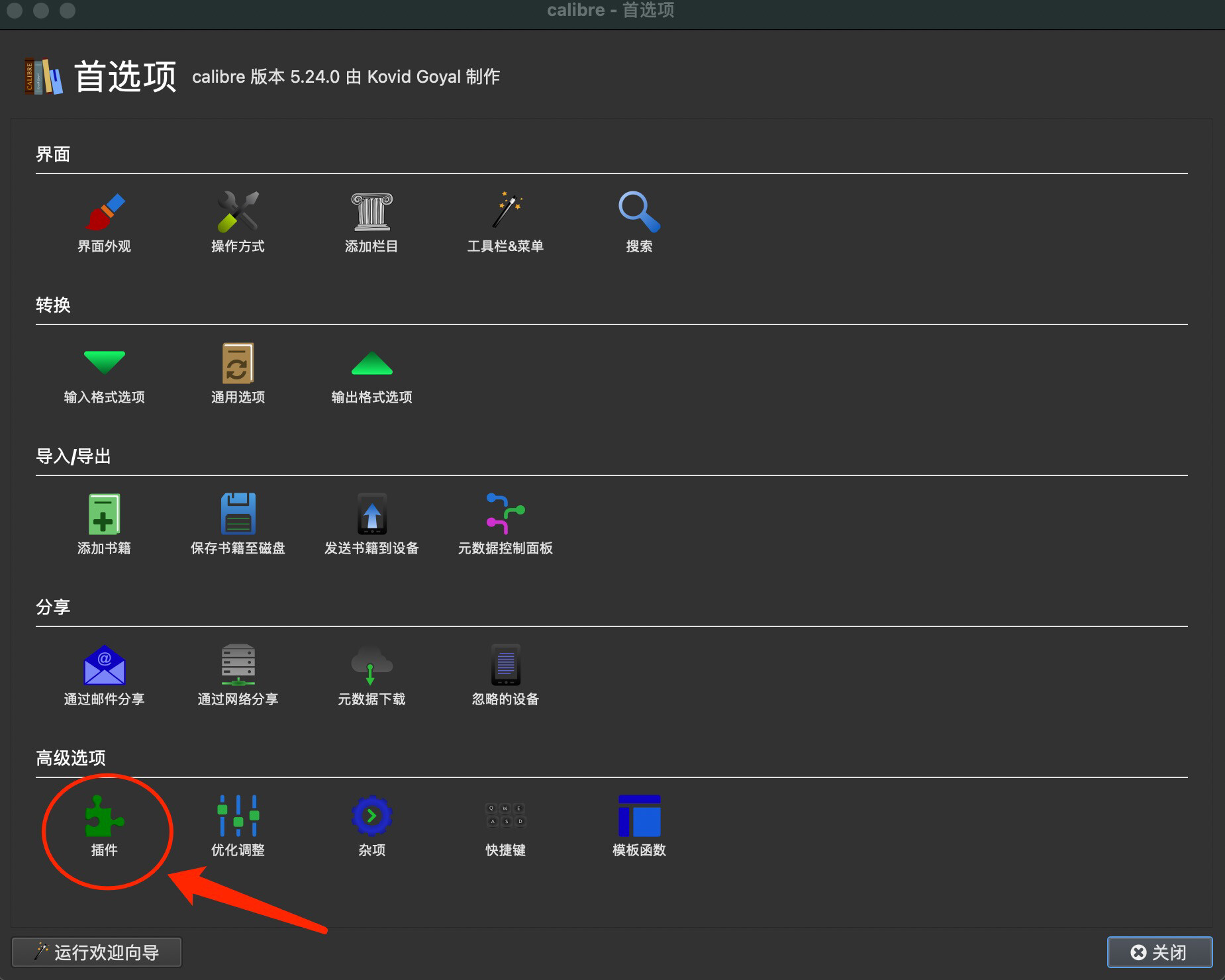
在首选项中找到插件选项
-
获取新的插件
-
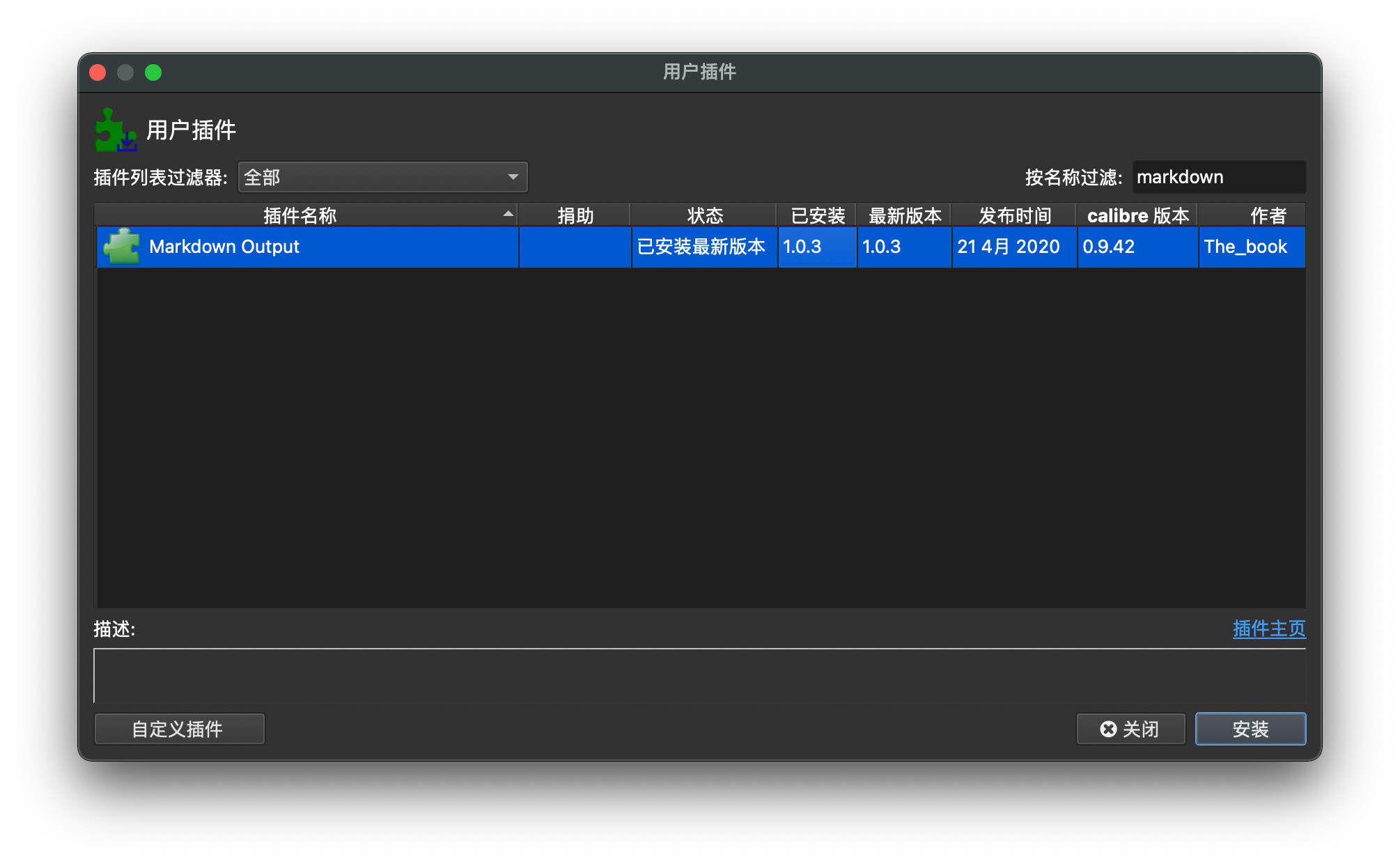
搜索 mardown output 插件并安装

步骤
纯文本电子书处理方式
- 打开calibre选择要转换的图书
- 选择批量转换
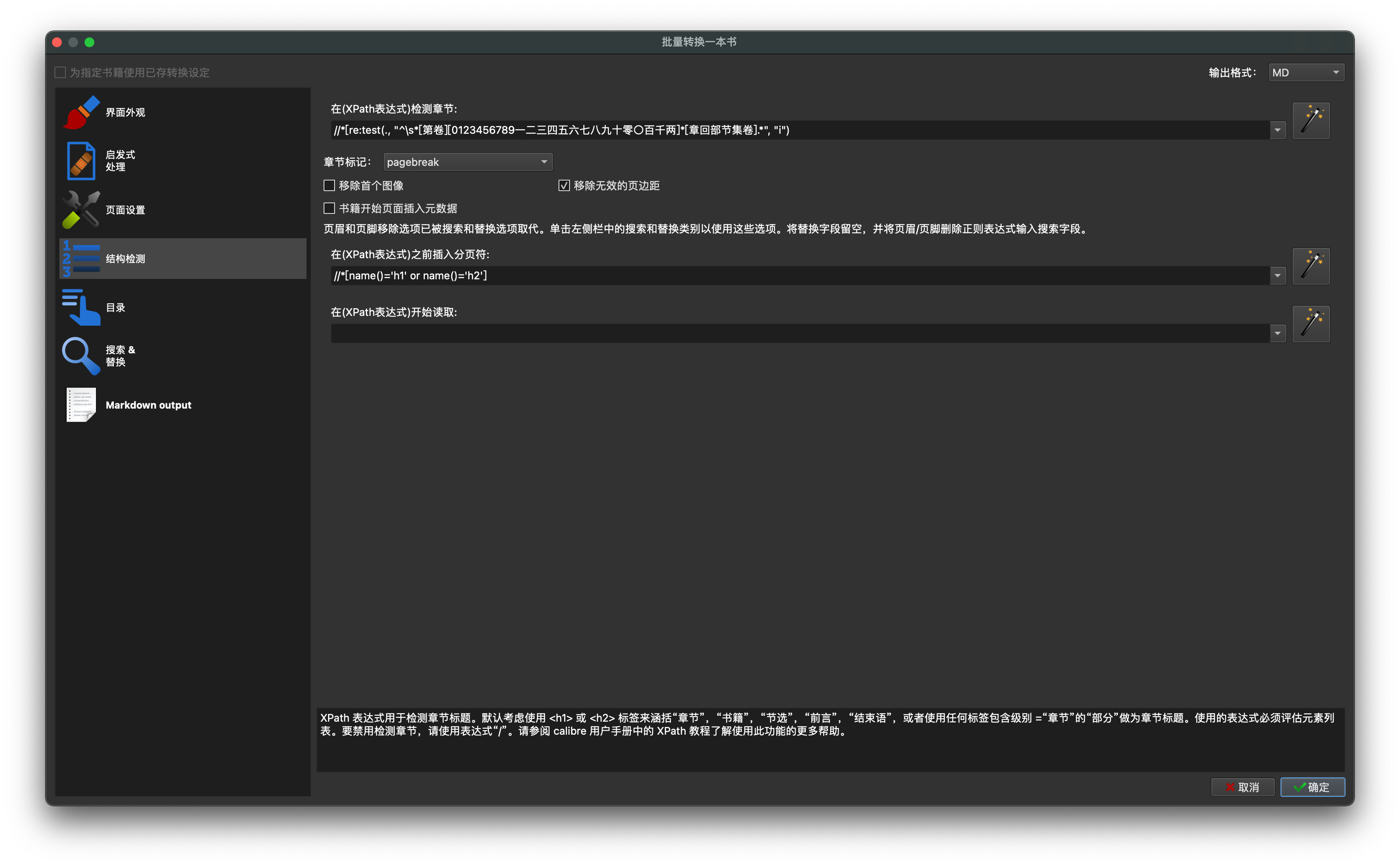
- 输出格式设置为MD,中文书籍需要修改XPath表达式。
//*[re:test(., "^\s*[第卷][0123456789一二三四五六七八九十零〇百千两]*[章回部节集卷].*", "i")]
- 选择图书导出单一格式,选择md格式
- 直接进文件夹拖动转换后的文件进obsidian库
针对对有大量图片的电子书处理方式
这里视频的方法有误,会造成图片混乱,感谢评论指出。(我太天真了,想懒到只用一个软件一动不动没那么容易QUQ)
- 转换图书时进入搜索&替换,输入图中两个正则表达式替换内容。
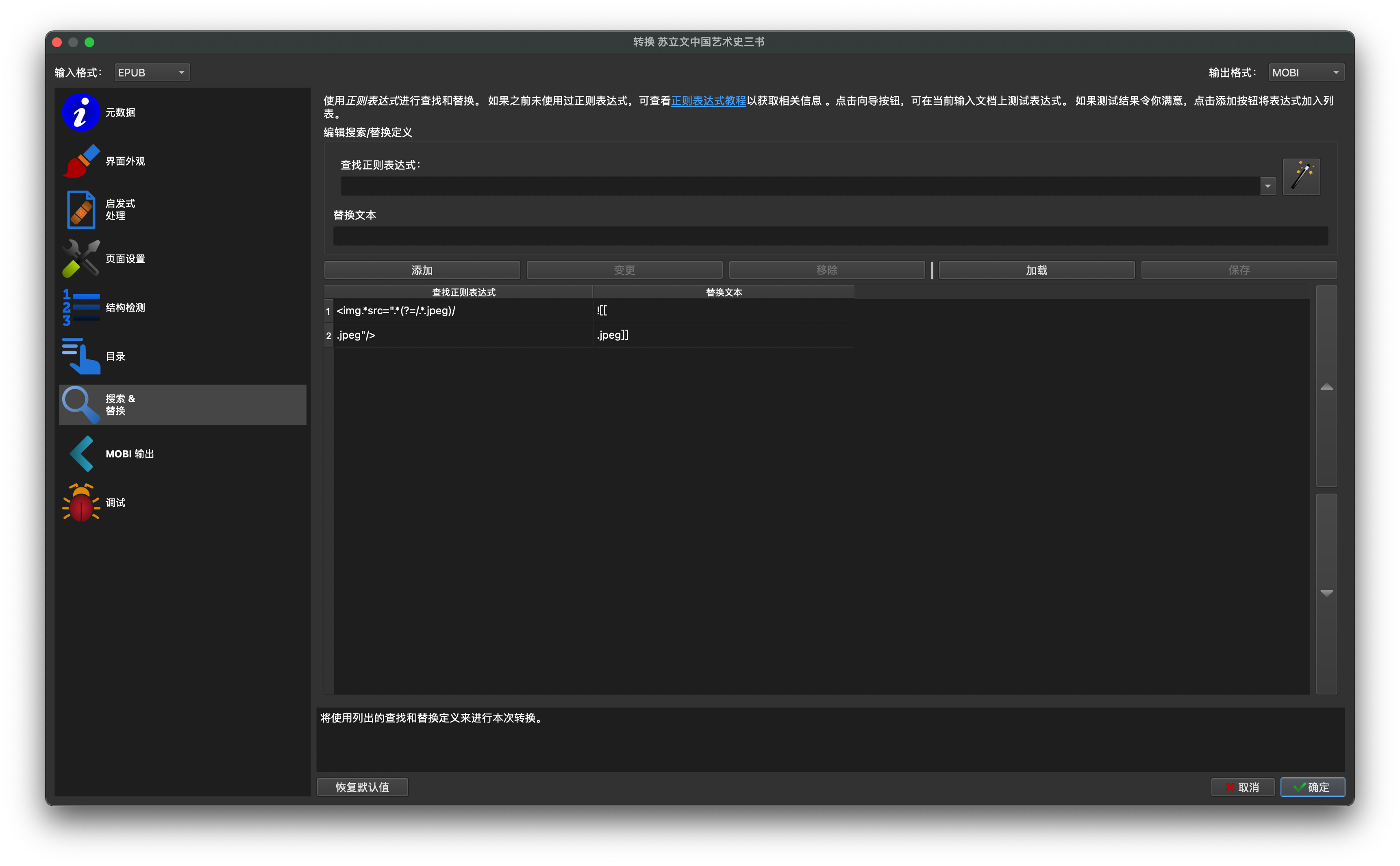
- 查找正则表达式:
<img.*src=".*(?=/.*.jpeg)/替换文本:![[ - 查找正则表达式:
.jpeg".*(?=.*/>)/>替换文本:.jpeg]]
因为每本图书的html文档不同,这个表达式可能会出bug,我靠我的菜鸟正则水平已经尽量试了好几本了QUQ。
如果出错可以在编辑书籍里搜索 img 来确认一下要修改哪里。
我基本上只用obsidian,所以这里直接用了wiki链来修改,方便接下来的懒人步骤。
如果有大佬提供更好的正则表达式我再换上。
-
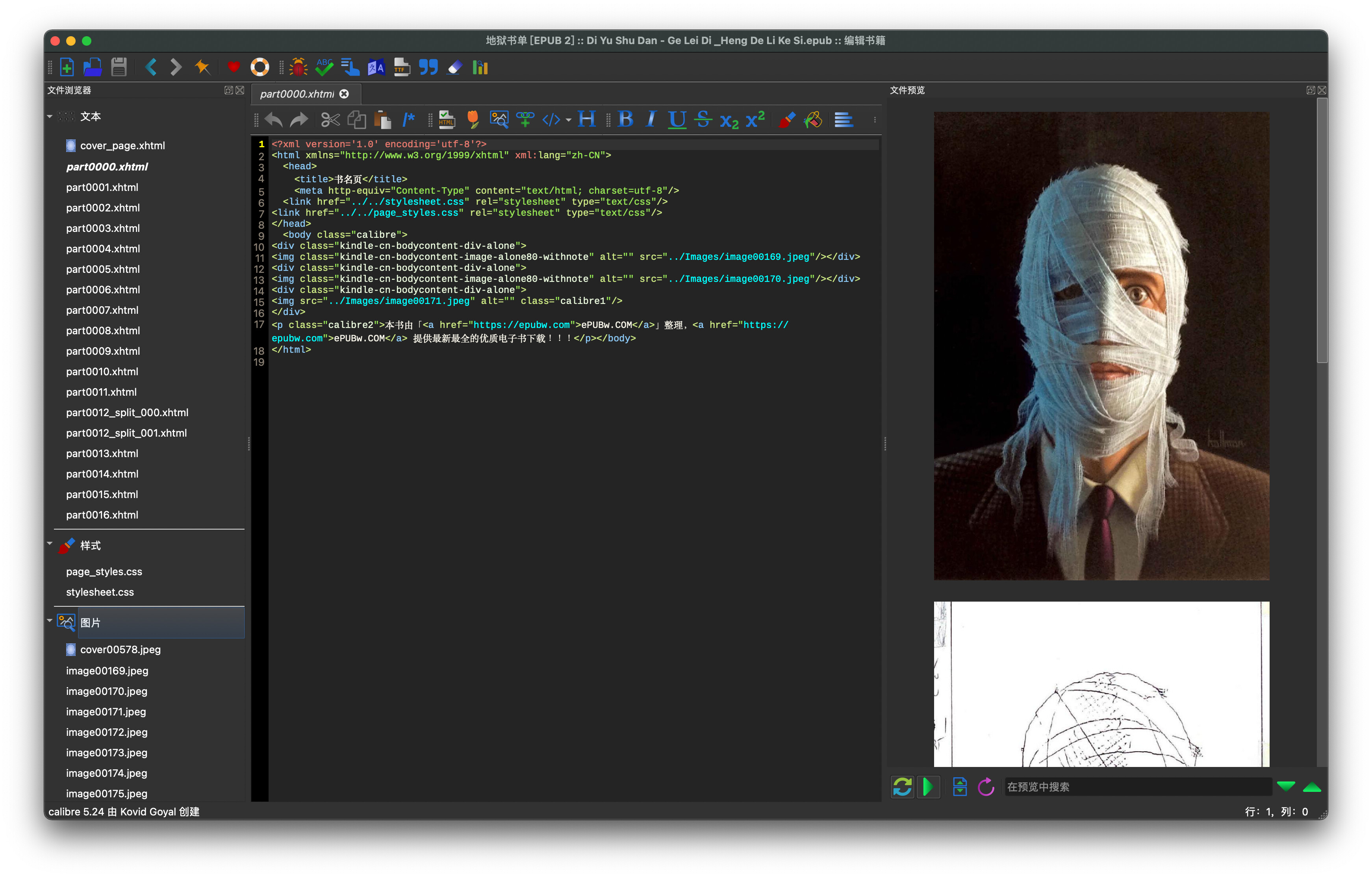
进入编辑书籍页面
-
左侧找到图片
-
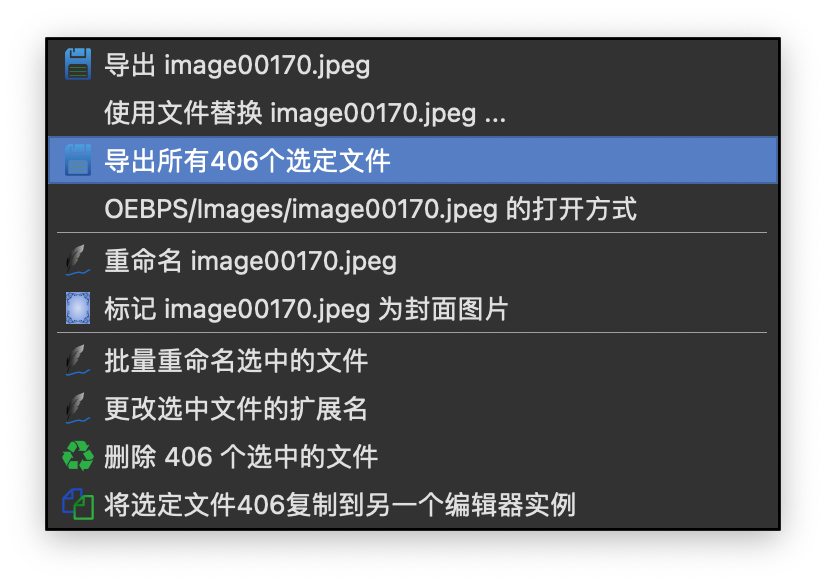
全选并导出(封面图可以跳过,没转换封面。不过也可以自己在文件开头再给编辑加上)。
-
导出后的文件拖入obsidian库中
-
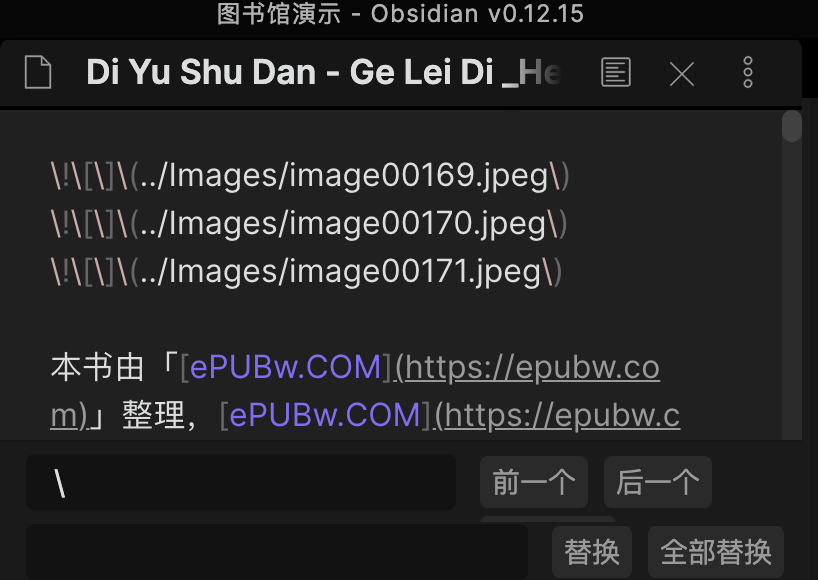
批量替换来删除多余的
\(这里要确认一下,如果是编程书籍原文可能会有\不能删除,不过如果看编程书籍了,大佬一定能自己解决对不对QUQ)

- 到这里虽然已经完成,但我开始觉得用calibre操作图片书籍一点都不懒人了。。。继续找下一个懒惰的办法