啊,我说的是图床内容可以用 alist 管理,正常暴露了文件夹,如 /root/obcsapi/data/ 映射docker 内文件,如果是 alist ,应该可以管理文件夹中的内容。因为图床那部分只有上传功能,没有文件管理的部分。
明白了。另外我刚才有个思路,能否在你的云端图床增加ocr识别功能,应该有成熟的ocr库吧,把识别后文字存储的专门的区域,再开发搜索插件进行访问,虽然有点麻烦,是否是解决ob没有图像搜索功能的一个思路。
昨天把3000多个md文件放入了ob的文件夹,台式机通过self-hosted livesync上传都没问题,但是iphone和ipad同步,总是同步一会儿就报错,是不是livesync的配置有关,同步信息太多,需要打开哪里的配置?
比如这里?
云端图床 ocr,怎么说呢,就是不太值得。首先一般服务器上的 ocr 都是python运行环境,或者单独成一项服务,换句话说是另一个 docker,而且这个资源占用可能还不低。当然使用百度ocr等付费或者有免费额度的就不必搭建,直接调用就可以,就是注册之类的略微繁琐。
不过确实可以运行一个 python 脚本,定时跟新索引,上传 obsidian 。就是扫描文件夹,然后往索引里写。或者运行个图片上传拦截的中间层,处理 ocr。
至于上传问题,这个我也没大规模用这个插件上传过,而且你发的这个也没报错提示。建议去提 issue。
另外补充一下,如果图片放在本地,ios 系统搜索应该就会自动创建 ocr 的索引。算是可以暂时替代吧。
谢谢指导,我再研究一下,目前图片ocr确实是刚需,如果不解决,还得用印象笔记做辅助工具,比较麻烦。

如果浏览器也不能能访问,那就是路径错误。
4.0.8 图床返回链接可以在配置文件中设置 http/https 了,现在 url /url2 的值是一样的,未来可能删除返回 url2 。另外图床上传时可以触发百度ocr了,文档里有配置说明。试验性质的,可以试试。
厉害了,牛。ocr识别结果能否直接写入图片所在文件,如果单独写一个一个文件中,查询之后,无法定位到图片所在原文件吧?

不会找不到文件,格式是这样的
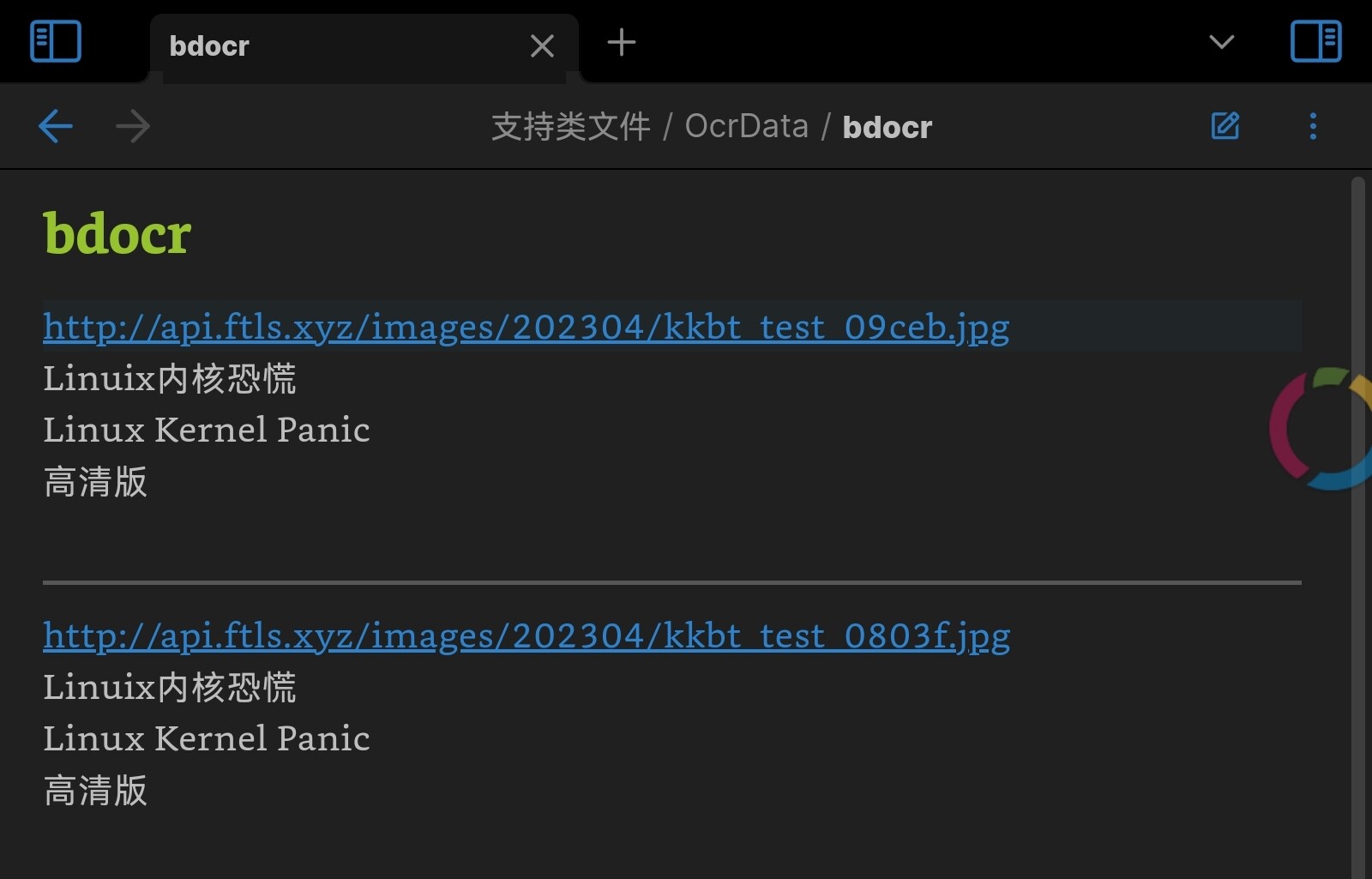
需要注意,需要新增的配置项,具体可看文档。
至于 access token 在这里有教程 https://ai.baidu.com/ai-doc/REFERENCE/Ck3dwjhhu 其中的 post 请求可以使用 curl Hoppscotch 或 Postman 。
多谢指导,我测试成功了。
我的意思是,我搜到图片中的文字,但是无法定位这个图片最早所在的原始笔记文档了。
有两个解决思路:一是在ocrdata中,加入源文档的链接。
二是将ocrdata直接写入图片所在笔记的隐藏区域。
另外,能否批量识别以前已经存储的图片,能否控制只识别部分文件夹图片,能否控制识别部分图片,或者靠插件控制?等等,我觉得这个功能大有可为,需要好好想想需求。
百度的免费ocr额度,每月1000张,对于个人用户绝对够用了。
ocrdata每月一个文件?都放在一个文件,会越来越长
当然这是一个实验性质的,你可能还没想好如何优化。
不过挺佩服你行动能力的,很快就搭好架构了。
可能只能开发插件,才能回传obscapi更新数据,否则只是上传图片,ocr是无法做出更多功能的。
原始文档很难定位,因为这个上传都不一定是什么客户端传的,可能都没有原始文档。。写入原始文档也不太可能,因为图片通过插件调用 picgo 上传,这中间想操作需要好几个软件程序。甚至涉及,如果文档位置移动了,怎么处理的问题。毕竟受限于markdown 本地存储和 obsidian 特性。所以顶多是复制粘贴,html 的 detail 标签就能隐藏文字,不过手动很繁琐。所以不如直接在文本中搜索 URL 。微信保存到图片倒是可实现ocr的 detail 和图片一起存到日记里。
已经存储好的文件,或者在库里文件,这个写个 python 脚本就可能全 ocr 完成。写个遍历 .jpg 后缀名的图片挨个 ocr 就行。百度的额度,似乎验证个人身份能增加到 5000。其实 ocr 也支持 pdf ,但是额度确实有限。
以后可能改成一月一文件,现在是 markdown 可读格式,可以随意分割,改名文件。正常应该使用数据库之类存储,而且这个数据库应该放在服务器上。用 api 进行检索之类的,或一个网页检索。确实是应该配合相应本地插件的。现在只能算是可用。
调用 ocr api 不算难事,不到50行代码吧,但是跨软件操作就难以实现,所以现在功能只能说鸡肋。
不知道你对开发ob插件是否熟悉,最好在插件上调用百度的ocr api,而不是在云端服务上调用,这样能够做出更多的功能,将ocr数据直接存储在笔记里面,不能专门放到一个文件夹下,便于今后查找使用
与其说不熟,可以说没接触过。我个人 obsidian 用的插件也是个位数的。。不如去现有的 ocr 检索插件中提 issue ,请求支持移动端。
明白了。期待将来有机会,继续优化ocr功能。
下面obcsapi版本迭代,你想引入哪些功能?
可能会先优化下公开文档功能。新功能可能会有每天早上发邮件提醒未完成任务?这也是很早以前的想法了,不过觉得 outlook 提醒效果类似,还更简单且专业实用,而微软 todo 或 滴答清单的 api 都很复杂,从解析到使用可能都略微麻烦。毕竟也只是个辅助软件,所以大概会不有什么大更新。
你有什么想法有可以讲讲,可能不会全实现但是也可参考。
邮件提醒,现在很少有人用吧?建议研究一下,利用微信公众号推送之类的提醒,更好一些吧?类似于思源笔记的微信推送提醒