话说回来,因为很少用task,我才发现dataview是可以同步修改task状态的,就是源文件也会变化
其实我也不喜欢用创建日期来计算,因为除了提前创建等问题,有时候文件同步时被覆盖,被删除然后找回的情况可能会改变创建日期,所以我计算时间一般靠yaml区的date属性,
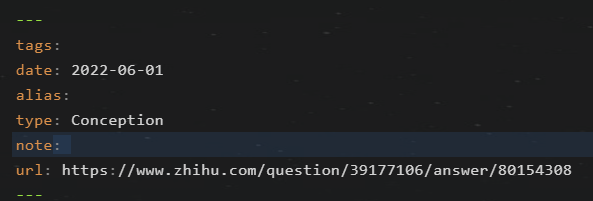
但考虑到也许有的人不用frontmatter,所以就算我的习惯改了,后面回复的代码依然用的是 file.cday,不过要改也很简单,file.cday 批量替换成 date(frontmatter)就行了
感谢大佬的解答,我已经试过了,查找一个月内未完成任务的需求已经可以了。
due是计划完成日期,在列task时可加入due关键字,如下:
- [ ] 2022-08-06需完成事项.[due::2022-08-06]
我把这条计划写在2022年6月6号的日记里边,加上due::2022-08-06的关键字,是计划在2022年08月06号实施的任务,如果计划日期小于当前日期,则此任务不会出现在汇总列表里边。due日期的话通过dataviewjs能索引到吗?
噢,原来是自己添加的属性啊,那简单,加一句话就行了
```dataviewjs
let files = dv.pages(`#日记`)
.filter(p=>
moment().subtract(1,'month') < moment(p.file.name.split('_')[0]) &&
moment() > moment(p.file.name.split('_')[0])
)
let tasks = files.file.tasks
.filter(p=>p.due?moment()>moment(p.due.ts):true)
dv.taskList(tasks)
```
抱歉,最后添的这一句没按我想要的工作,我想修改也是没看懂,能帮忙大体解释一下吗?.filter(p=>p.due?moment()>moment(p.due.ts):true)这句是取页面中due的值,并且通过moment函数转换成日期的格式,然后进行比较吗?p.due.ts和后边的true该怎么理解?没找到相关的资料,苦恼一下午了。 ![]() 我尝试把其中的大于号改成小于号,最终结果没啥变化,没搞懂原因。
我尝试把其中的大于号改成小于号,最终结果没啥变化,没搞懂原因。
嗯?等一下,你一边过滤出due小于当前日期的task
一边想要due小于当前日期的task不会出现![]() ,着实把我搞懵了
,着实把我搞懵了 ![]()
原理:a?b:c 称为三目运算符,a为条件判断,若为true返回b,若为false返回c
在此情景下,due属性可能有也可能没有。遇到没有due的task时,因为它是个未定义undefined变量,条件判断时会隐式转换为false;反之,一个有意义的对象会转换为true。所以意义就很明显了,若有due,则执行前面的语句,若没有,直接通过。
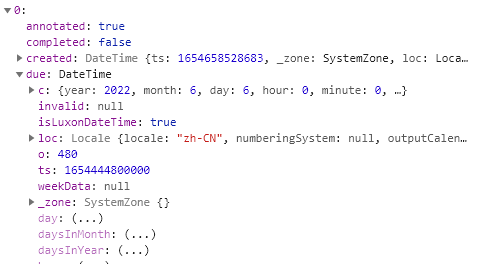
至于p.due.ts嘛,看这张图就知道了,我在另一篇介绍dataviewjs的文章中提到过,关于时间的字符串会被自动解析为datetime对象
是这样想的,文件的日期和当前的日记日期相比要相差小于一个月,有个-dur(1 month)的式子,但是当前笔记中的task因为也满足条件,所以也会出现在这里,我想排除,又增加了个小于当前日期的操作。想取的时间段应该是相当于一个月以前到昨天。
对啊,那跟due有什么关系呢
本意是对task进行细分,分成今天要完成的任务,已经过期但是尚未完成的任务,计划中尚未实施的任务三类。有due的会导致计划所在的页面的录入日期和due日期是不同的,本意是想剔除due日期在当前日期之后的task,不让它显示在已经过期但是尚未完成的里边。确实比较绕了,我让有due日期的task只在due日期的当天在今天要完成的任务显示吧。
看了您写的说明,总算是搞懂这个三目运算符和due.ts该怎么用了,现在用due判断也能写了,感谢~~
ok,能用就行 ![]()
请问有可能把这一段生成markdown文件吗,这样不装dataview插件的obsidian也可以用
你的意思是指把结果固定下来吗
大佬,最后一段代码,集合固定标题下的内容,对于日记来说,有一些日记没有固定标题下的内容,也筛选出来了,怎么改改,可以只显示有内容的?
另外能不能日记的时间顺序,降序排列吖。
对的,这样我用其它方式打开文件,也能看明白
```dataviewjs
dv.paragraph('```\n'+
dv.pages(``)
.filter(p=>moment(Number(p.file.cday)).get("year")==2021)
.sort(p=>p.file.cday,'desc')
.map(p=>moment(Number(p.file.cday)).format('yyyy-MM-DD')+' >> '+p.file.link)
.join('\n')
+'\n```')
```
这样运行一遍再把结果复制出来
```dataviewjs
const term = "日常记录"
const files = dv.pages(`"600-日常" and #日记`).sort(p=>p.file.name,'desc')
const b = files.map(async function(p){
var x = await app.vault.readRaw(p.file.path);
x = x.split("\n### ").find(p=>p.startsWith(term));
if(!new RegExp(term+'\s+?').test(x))
dv.paragraph("## "+p.file.name+"\n\`\`\`ad-note\ntitle: DailyNote\n"+x.slice(term.length)+"\n\`\`\`");
})
```
嗯,加个空值判断就行了
尝试了一下,降序貌似成功了,但是并没有剔除无内容的日记。
能看一下日记的格式吗,至少这在我的库里边是有效的
---
author:
created: <% tp.file.creation_date("YYYY-MM-DD HH:mm") %>
alias:
- <% tp.file.title %>
tags:
-
---
---
updated :: <%+ tp.file.last_modified_date("YYYY-MM-DD HH:mm") %>
---
# <% tp.file.title %>
## 任务
## 记录
## 收获
## 最近7天的新建任务
```dataview
task from -"00.个人生活/checklist" and -"模板" and -"收集箱" and -"01.工作/归档" and -"01.工作/工作资料"
where !completed and created >= date("<% tp.file.title %>") - dur(1 week) and created <= date("<% tp.file.title %>") + dur(1 day)
sort file.mtime desc
group by section
```
## 相关文件
```dataview
table file.path as path,file.mtime as mtime
from [[<% tp.file.title %>]]
sort file.mtime desc
```
## 最近7天完成的任务
```dataview
task from -"00.个人生活/checklist" and -"模板" and -"收集箱" and -"01.工作/归档" and -"01.工作/工作资料"
where completed and 完成 >= date("<% tp.file.title %>") - dur(1 week) and 完成 <= date("<% tp.file.title %>") + dur(1 day)
sort file.mtime desc
group by section
```
## 今日更新
```dataviewjs
dv.header(3,'创建时间')
dv.list(dv.pages().filter(p=>moment(p.file.cday.ts).format('yyyy-MM-DD')==dv.current().file.name).sort(p=>p.file.ctime).map(p=>p.file.link+' - '+moment(p.file.ctime.ts).format('a HH:mm')))
dv.header(3,'修改时间')
dv.list(dv.pages().filter(p=>moment(p.file.mday.ts).format('yyyy-MM-DD')==dv.current().file.name).sort(p=>p.file.mtime).map(p=>p.file.link+' - '+moment(p.file.mtime.ts).format('a HH:mm')))
```
我要统计出来的那部分是 `收获`的那部分。
谢谢了太奇怪了,很正常的格式啊,再试试这个吧
```dataviewjs
const term = "收获"
const files = dv.pages(`#aaaaa`).sort(p=>p.file.name,'desc')
const b = files.map(async function(p){
var x = await app.vault.readRaw(p.file.path);
x = x.split("\n## ").find(p=>p.startsWith(term));
if(!RegExp(term+'\n*?$').test(x))
dv.paragraph("## "+p.file.name+"\n\`\`\`ad-note\ntitle: DailyNote\n"+x.slice(term.length)+"\n\`\`\`");
})
```