如果有人感兴趣的话,我也可以写篇帖子分享一下更具体的dataviewjs语法(挖坑ing)
1 个赞
感谢大佬,非常感谢大佬迅速的回复。
我把array 改成string ,p.tags 改成 p.file.tags, indexOf 改成 includes
最后const files 被我改成下面的样子,成功的完美的实现了我的目的 ![]() :
:
const files = dv.pages(‘“2_Research/paper”’).filter(p=>String(p.file.tags).includes(‘test’)).sort(p=>p.file.mtime)
其中 2_Research/paper 是我的文件夹 , test 是我的需要标签名
感谢大佬,真就很棒!
最后,我把大佬下面一句:
dv.paragraph(“## “+p.file.name+”\n```ad-note\ntitle: DailyNote\n”+x.slice(term.length)+“\n```”);
中p.file.name 改成p.file.link 方便我从这一页面回去
1 个赞
生命在于折腾 ![]() ,我的态度是这样,对于别人我一般是劝告一切以笔记(知识)优先,少折腾
,我的态度是这样,对于别人我一般是劝告一切以笔记(知识)优先,少折腾
我本来也是学编程的,入门个新语言查询个东西还是很快的 ![]() ,折腾这东东可能没啥用,但它快乐啊
,折腾这东东可能没啥用,但它快乐啊
3 个赞
代码都是大佬逐字逐句敲出来的么? ![]()
js为什么看起来长又chou ![]() 不知道哪里断句的赶脚
不知道哪里断句的赶脚
![]() 这。。。我也是初学者,算不上什么大佬,写得又臭又长单纯是技术力不够,重复无用的部分太多了,外加懒,能一行写完的就不写两行
这。。。我也是初学者,算不上什么大佬,写得又臭又长单纯是技术力不够,重复无用的部分太多了,外加懒,能一行写完的就不写两行
现在回看这些代码,感觉写得真的是烂 ![]() ,作为一个分享贴,写成这样也确实不好,但是为什么帖子不能编辑了
,作为一个分享贴,写成这样也确实不好,但是为什么帖子不能编辑了 ![]()
我嘴拙,大佬的js香飘万里 ![]() 白嫖哪能是chou
白嫖哪能是chou
js普遍长得长,与大佬无瓜 ![]()
dv是个不错的js入门契入点呢,为了读通大佬的文,已经着手学最初阶js了 ![]()
1 个赞
大佬,我想使用dataviewjs对一个文件夹内的文件的latex公式引用,请问该怎么写呢,或者说怎么样才能读取文件内内容(我的公式都打上了块编码”^formula”)。
我试了一下,好像dataviewjs对块引用不太支持诶
那不然只能app.vault.readRaw读取文本内容后直接正则了
正则问题不大,主要是不太会如何读取文件哈哈哈
那现在你该会了吧
大概会了,不过正则在dataviewjs里面怎么写呀
嗯,就和js一样啊
我常用的方式是 exec
比如说
let pattern = /b(.*?)c/
let a = 'aabbccdd'
console.log(pattern.exec(a)[0])
// bbc
其他的都是可以查到的
收到收到哈哈哈,我也是刚入门js,边用边学
首先感谢楼主的分享 ,解决好多的问题,我也借用你的分享 解决了一些问题。
有一个问题想请教 :
我的日记里:
工作日志
日总结
年:2022 周:2022-W19
同日历史:[[2021-05-14]]
我利用你的日记 代码修改了一下:
const term = "工作日志"
const files = dv.pages(`"200-daily"`).sort(p=>p.file.name)
const b = files.map(async function(p){
var x = await app.vault.readRaw(p.file.path);
x = x.split("\n### ").filter(p=>p.slice(0,term.length)==term)[0];
dv.paragraph("## "+p.file.name+"\n\`\`\`ad-note\ntitle: DailyNote\n"+x.slice(term.length)+"\n\`\`\`");
}
)
能实现抽取[工作日志]标题下的内容 ,但它也连下的[日总结] 和历史的今天也抽出来了,能否只抽取[工作日志]标题下的内容

真是奇怪,这段代码在我这是正常的,我没办法复现你所说的情况,你试试把倒数第二句的 \n### 改成 ###
dv.pages("200-daily").sort(p=>p.file.name) – 是我这句话修改的有问题吗,你的是经标签过滤的,我的没有。修改成### 也是一样 出现下面的内容。
那把日记的全文源码和代码的结果截个图看看吧
这个是修改你的代码后的结果 ,现在结果显示的是对的
const term = "工作日志"
const files = dv.pages(`"200-daily"`).sort(p=>p.file.name)
const b = files.map(async function(p){
var x = await app.vault.readRaw(p.file.path);
x = x.split("\n### ").filter(p=>p.slice(0,term.length)==term)[0];
dv.paragraph("## "+p.file.name+"\n\`\`\`ad-note\ntitle: DailyNote\n"+x.slice(term.length)+"\n\`\`\`");
}
)
日记的全文源码图:

今天的代码结果图:
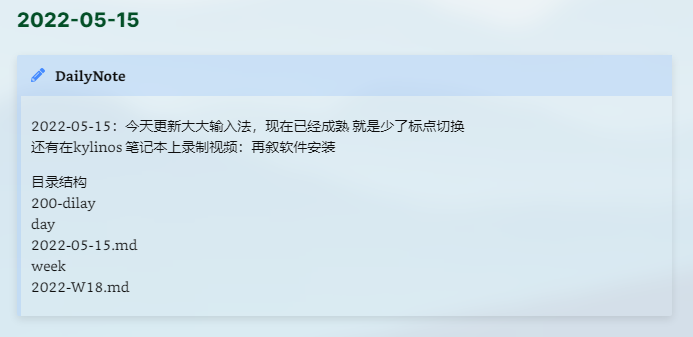
真是奇怪,那应该没什么问题了吧