可以了哈哈哈很感谢你![]()
![]()
![]()
1 个赞
利用api接入的大模型,是不带记忆功能的吧 ![]()
deepseek可以接入,目前用下来效果还行
1 个赞
对的,是不带的。
- 是否可以写提示词用ai整理一些不重要的笔记,不用整理整个笔记库,可以整理其中的一个文件夹,一个文档,甚至其中的一个列表之类的。有时候笔记多了,整理起来也是个费时间的事情

- 还有这个和Smart Connections的区别优势在哪里
1 个赞
- Text Generator 插件写模板来整理单篇文章会比较方便。但是多文章我不太了解有什么插件可以做。
- smart connections 聊天应该不支持图片上传,然后这个 smart composor 还可以 Apply Edit。
- smart connections 有相似度列表,smart composor没有。
1 个赞
感谢您分享一个好的插件,可以当作本地文档问答之类插件使用,。
smart connections插件对我来说不太合适,他的相似度列表在问我的多层级无序列表下很难使用,因为我的笔记组织利用无序列表的多个层级,很少使用标题区块等。不使用标题的原因是标题层级只有6级,而我的列表层级经常会超过6级。
抛开copilot推出copilot plus不谈,copilot有相比 composor的亮点吗,两者中是否都可以自定义回答格式(比如采取无序列表),两者是否存在明显的优势和不足。
初步看composor提问方便点,回答更简洁。copilot回答当前问题需要多点操作,目前更详细点

大佬请问你使用 Vault Search 功能时遇到过 “Aborted().Build with -sASSERTIONS for more info” 报错吗?
1 个赞
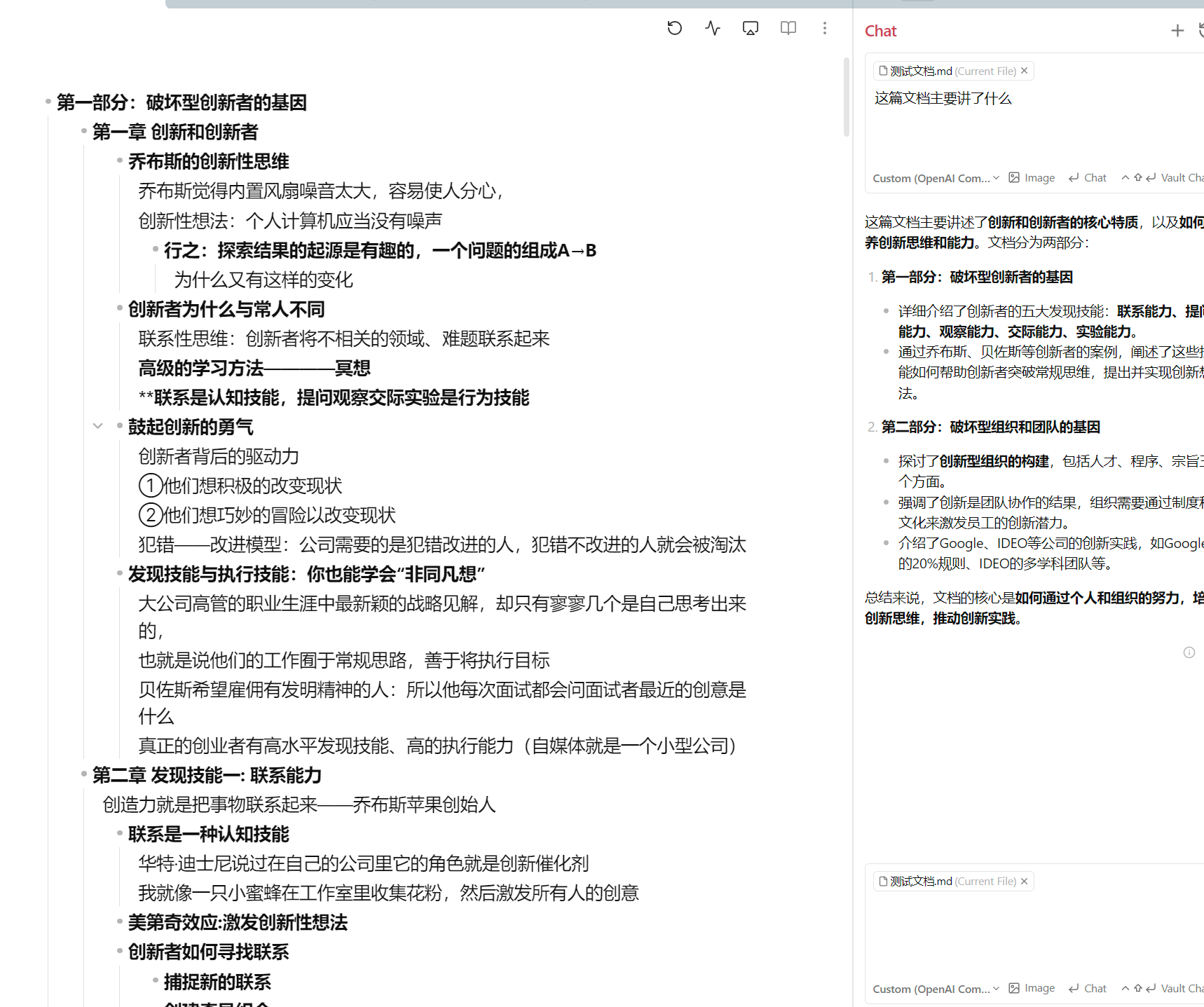
希望后面有大佬解答一下,插件嵌入模型用的是ollama/bge-m3,回答模型用的是声称上下文长达百万token的ai模型,这里面的Chunk size、Threshold tokens、Minimum similarity、Limit每项数值应该怎么设置,使得回答准确性、相关性和回答速度都有着一定保障。
同时看是否能推荐一下更好的嵌入模型和回答模型,有些回答模型会报错。
回答的内容简洁详细与否,关系最大的应该是提示词和大模型api。
这两个插件功能相差不大。对我来说就是 copilot 的不足就是不能上传图片交流吧。
1 个赞
不好意思我没遇到过
哦哦,感谢回复 ![]()
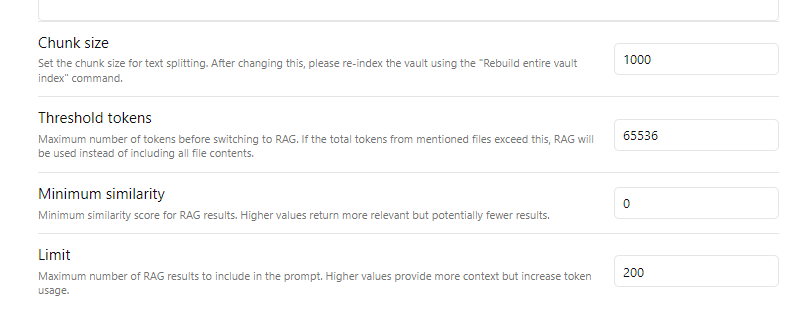
Chunk Size = 文档被剁碎时每个切片的大小, 500-2000 token 应该合理, 数值太小时片段语义不完整, 数值太大时向量嵌入也不能很好的抓到句子重点
Threshold tokens = 如同截图里的解释, 该插件首先会试着把全笔记都丢给聊天模型, 如果笔记实在太长就切到 RAG 模式, Threshold tokens 就是切换 RAG 模式的阈值, 65536 token 对应 30000~90000 中文字
个人建议这值设小点, 真有必要把巨大文本扔给模型让它读全文的场景, 其实较少 (出于应答快速, 模型注意力, 生成质量可控, 省成本等许多理由)
Minimum similarity = 当 query_text 和文档片段相似度达到多少时才允许召回, 比如设 0.3 就是说, 如果文档库里的片段相似度全都低于 0.3 它宁可不召回
该设置用于知识库拒答, 防止AI对于库里没有的知识瞎胡说, 对于那种团队或公开访问的, 要应对五花八门奇葩问题的知识库很必要
对于 Ob 个人库, 自己笔记都里有啥, 啥该问啥不该问心理有数, 这个值可以设为零
Limit = RAG 模式下最大召回文档片段数量, 一般是 5-20
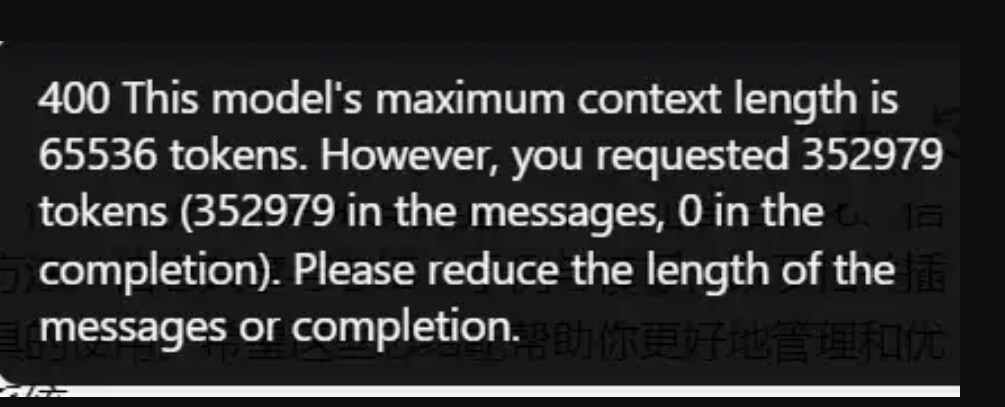
设为 200 很有问题, 浪费 token 且使模型抓不住重点 (不可能有必须依赖 200 个语料片段才能回答的问题) 截图里 requested 352979 tokens 很可能跟这个有关
4 个赞
感谢大佬详细的分析,一下子清晰明了。
好的,感谢回答,明白了关键在哪,那估计是插件提示词的问题。
应该是模型名错了
取值范围
lite
generalv3
pro-128k
generalv3.5
max-32k
4.0Ultra
指定访问的模型版本:
lite指向Lite版本;
generalv3指向Pro版本;
pro-128k指向Pro-128K版本;
generalv3.5指向Max版本;
max-32k指向Max-32K版本;
4.0Ultra指向4.0 Ultra版本;
我之前就是把modal指定免费的lite的,安卓是一样的错误。
用了一周了,的确很好用。要是能更新维护快一点,把从deepseek V3模型换到 R1模型,遇到的400错误问题解决就好了。
有相似度了呀。。。
1.添加一个Povider,Add custom provider
ID :随便填,例如:siliconflow
provider type : openai compatible
API Key:账户管理->API密钥 创建一个apikey复制进来
Base url:https://api.siliconflow.cn/v1
-
添加embedding model ,Add custom model
ID: 随便填
provider id :选上一步创建的provider,这里是siliconflow
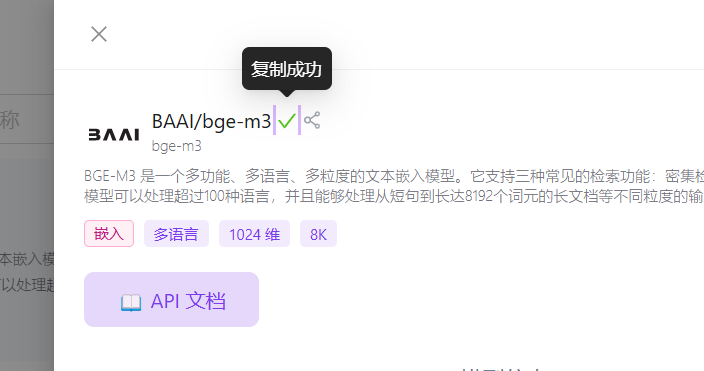
Model Name :在硅基流动官网复制模型名称,如图。这里是 BAAI/bge-m3
-
插件设置里拉倒下面的RAG → Embedding model 选择创建好的 BAAI/bge-m3
-
插件设置里拉倒最下面有个Manage Embedding Database,点击Manage,找到创建的BAAI/bge-m3,点击rebuild index
1 个赞